This Machine Learning Research Presents ScatterMoE: An Implementation of Sparse Mixture-of-Experts (SMoE) on GPUs
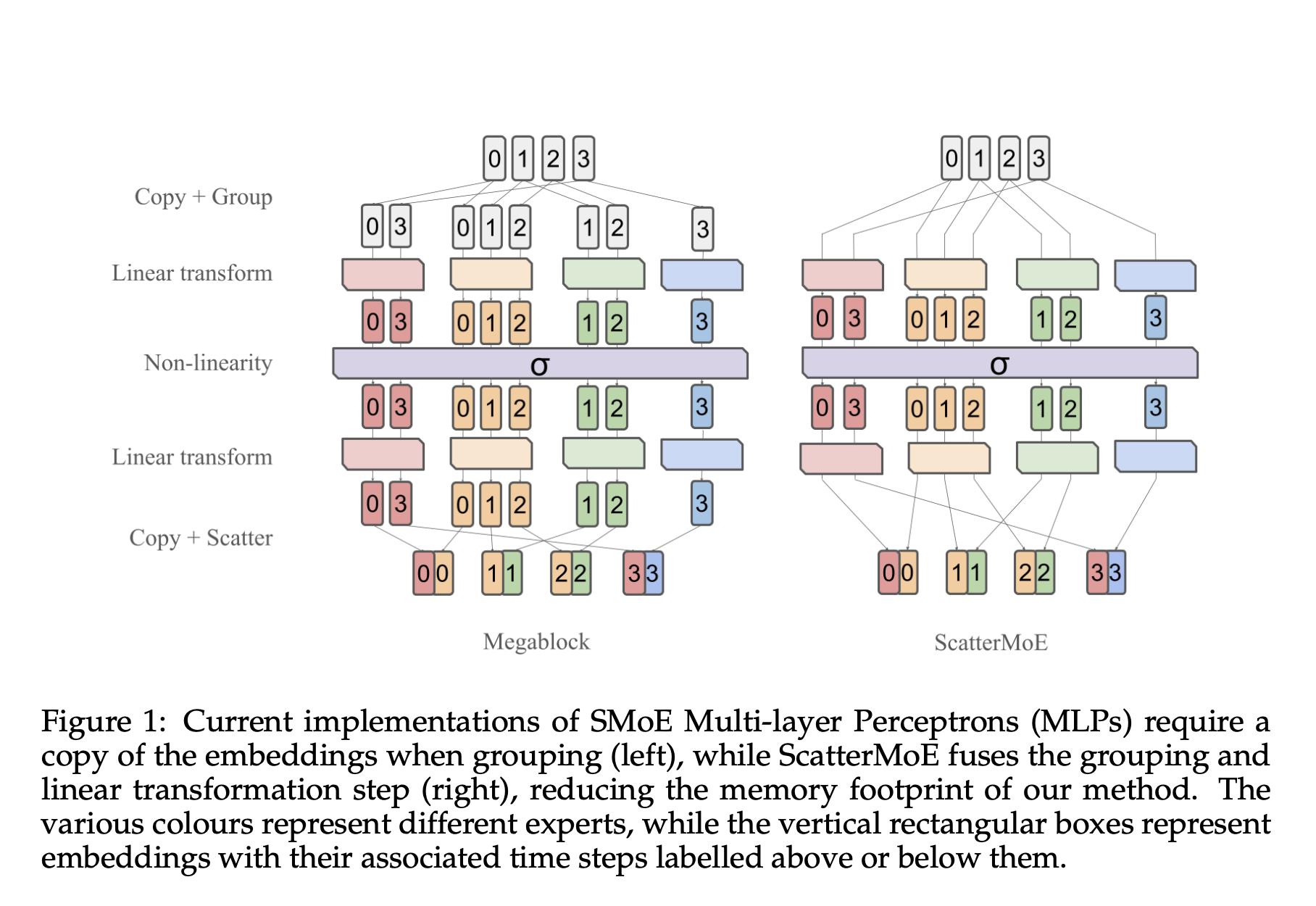
A sparse Mixture of Experts (SMoEs) has gained traction for scaling models, especially useful in memory-constrained setups. They’re pivotal in Switch Transformer and Universal Transformers, offering efficient training and inference. However, implementing SMoEs efficiently poses challenges. Naive PyTorch implementations lack GPU parallelism, hindering performance. Also, initial deployments of TPUs need help with tensor size variability, leading to memory allocation issues due to imbalanced expert usage.
Megablocks and PIT propose framing SMoE computation as a sparse matrix multiplication problem to address these challenges. This allows for more efficient GPU-based implementations. However, existing approaches still have drawbacks. They require a scatter-to-group initial copy of the input, leading to memory overhead during training. Some implementations further exacerbate this issue by padding the grouped copy, increasing memory usage. Moreover, translating the SMoE problem into a sparse matrix format introduces computation overhead and opacity, making extension beyond SMoE MLPs difficult.
Researchers from IBM, Mila, and the University of Montreal present ScatterMoE, an efficient SMoE implementation that minimizes memory footprint via ParallelLinear, which conducts grouped matrix operations on scattered groups. This approach enables intermediate representations to be exposed as standard PyTorch tensors, facilitating easy extension to other expert modules. Demonstrated with SMoE Attention, ScatterMoE is benchmarked against Megablocks, which is crucial for its usage in Megatron-LM. Megablocks is implemented using the STK framework, making it accessible for modification and extension.
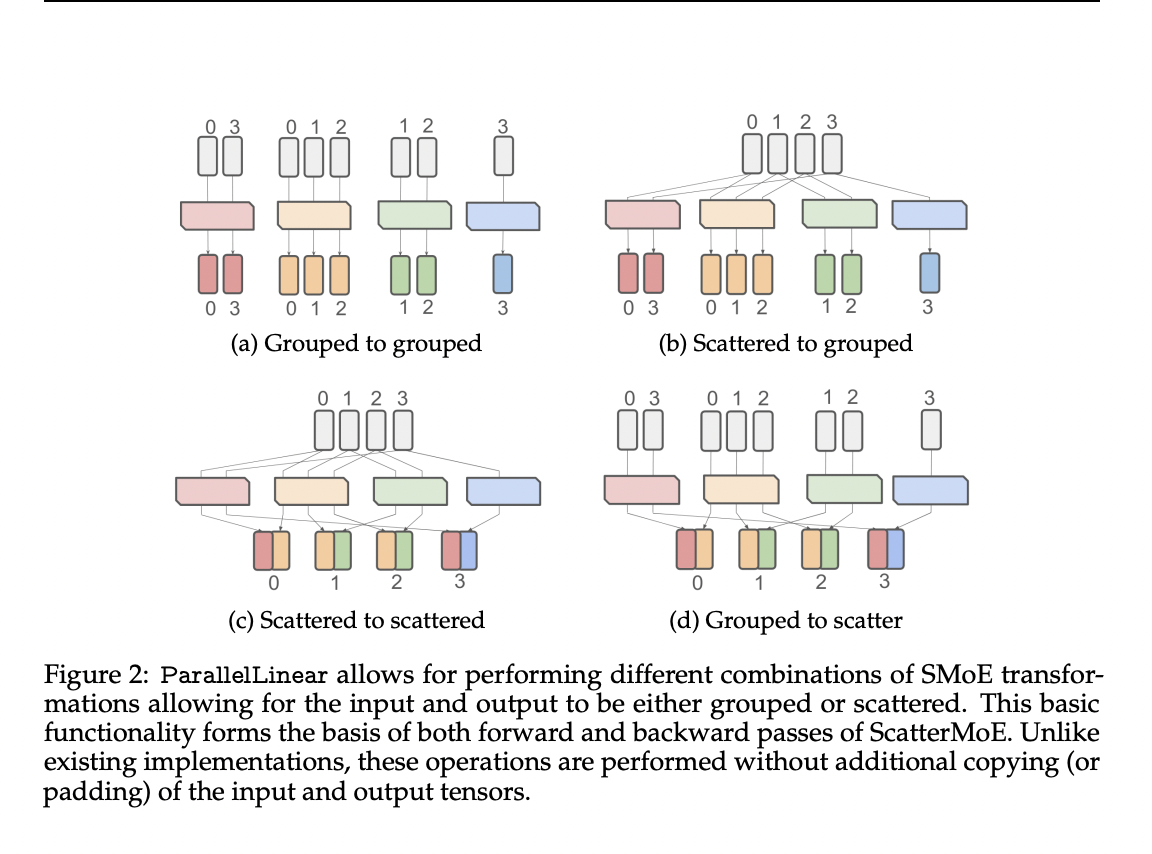
ScatterMoE employs ParallelLinear for efficient SMoE computation. It streamlines memory usage by avoiding additional copying and padding during operations. ParallelLinear facilitates various transformations, enhancing extensibility to other expert modules. For the backward pass, ParallelLinear efficiently computes gradients for each expert. ScatterMoE also enables seamless implementation of Mixture-of-Attention (MoA) without additional memory costs, supporting applications like SMoE Attention. The proposed method is benchmarked against Megablocks for validation.
In Mixtral, ScatterMoE outperforms Megablocks Sparse and Memory-efficient implementations by a staggering 38.1% overall throughput. Unit benchmarking on SMoE MLP reveals ScatterMoE’s higher throughput during training and lower memory consumption. As granularity increases, ScatterMoE demonstrates better scalability compared to Megablocks, making it the clear choice for high-granularity settings. Decreasing sparsity also showcases ScatterMoE’s efficiency, outperforming Megablocks in throughput while remaining more efficient than dense MLP models. Also, in Mixture of Attention implementation, ScatterMoE consistently outperforms Megablocks, particularly in high granularity settings.
In conclusion, the researchers have introduced ScatterMoE, which enhances SMoE implementations on GPUs by mitigating memory footprint issues and boosting inference and training speed. Leveraging ParallelLinear, it outperforms Megablocks, demonstrating superior throughput and reduced memory usage. ScatterMoE’s design facilitates the extension of Mixture-of-Experts concepts, exemplified by its implementation of Mixture of Attention. This approach significantly advances efficient deep learning model training and inference.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.