This Machine Learning Research Unveils Cutting-Edge Techniques for Cost-Effective Large Language Model Training
Developing large language models (LLMs) represents a cutting-edge frontier. These models, trained to parse, generate, and interpret human language, are increasingly becoming the backbone of various digital tools and platforms, enhancing everything from simple automated writing assistants to complex conversational agents. Training these sophisticated models is an endeavor that demands substantial computational resources and vast datasets. The quest for efficiency in this training process is driven by the need to mitigate the environmental impact and manage the escalating computational costs associated with the ever-growing datasets.
The traditional method of indiscriminately feeding gargantuan datasets to models, hoping to capture the vast expanse of linguistic nuances, is inefficient and unsustainable. This method’s brute-force approach is being reevaluated in light of new strategies that seek to enhance the learning efficiency of LLMs by carefully selecting training data. These strategies aim to ensure that each piece of data used in training packs the maximum possible instructional value, thus optimizing the training efficiency.
Recent innovations by researchers of Google DeepMind, University of California San Diego, and Texas A&M University have led to the development of sophisticated data selection methods that aim to elevate model performance by focusing on the quality and diversity of the training data. These methods employ advanced algorithms to assess the potential impact of individual data points on the model’s learning trajectory. By prioritizing data that offers a wide variety of linguistic features and selecting examples deemed to have a high learning value, these strategies seek to make the training process more effective and efficient.
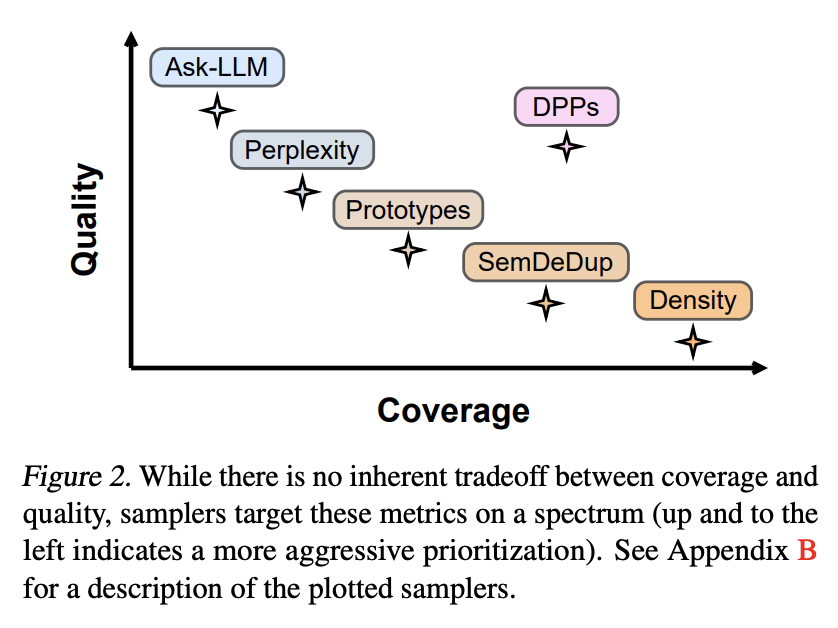
Two standout techniques in this realm are ASK-LLM and DENSITY sampling. ASK-LLM leverages the model’s zero-shot reasoning capabilities to evaluate the usefulness of each training example. This innovative approach allows the model to self-select its training data based on a predetermined set of quality criteria. Meanwhile, DENSITY sampling focuses on ensuring a wide representation of linguistic features in the training set, aiming to expose the model to as broad a spectrum of the language as possible. This method seeks to optimize the coverage aspect of the data, ensuring that the model encounters a diverse array of linguistic scenarios during its training phase.
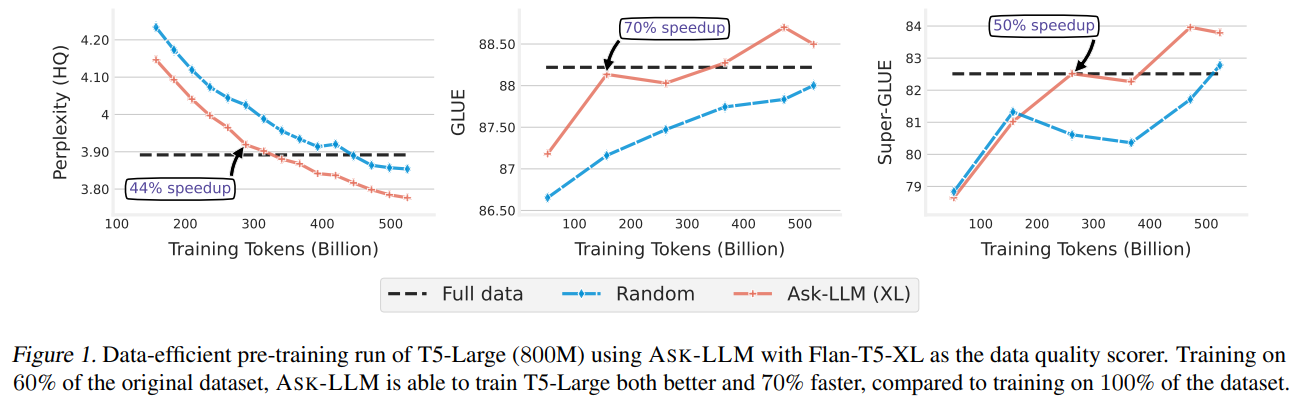
ASK-LLM, for example, has shown that it can significantly improve model capabilities, even when a large portion of the initial dataset is excluded from the training process. This approach speeds up the training timeline and suggests creating high-performing models with substantially less data. The efficiency gains from these techniques suggest a promising direction for the future of LLM training, potentially reducing the environmental footprint and computational demands of developing sophisticated AI models.
ASK-LLM’s process involves evaluating training examples through the lens of the model’s existing knowledge, effectively allowing the model to prioritize data that it ‘believes’ will enhance its learning the most. This self-referential data evaluation method marks a significant shift from traditional data selection strategies, emphasizing the intrinsic quality of data. On the other hand, DENSITY sampling employs a more quantitative measure of diversity, seeking to fill in the gaps in the model’s exposure to different linguistic phenomena by identifying and including underrepresented examples in the training set.
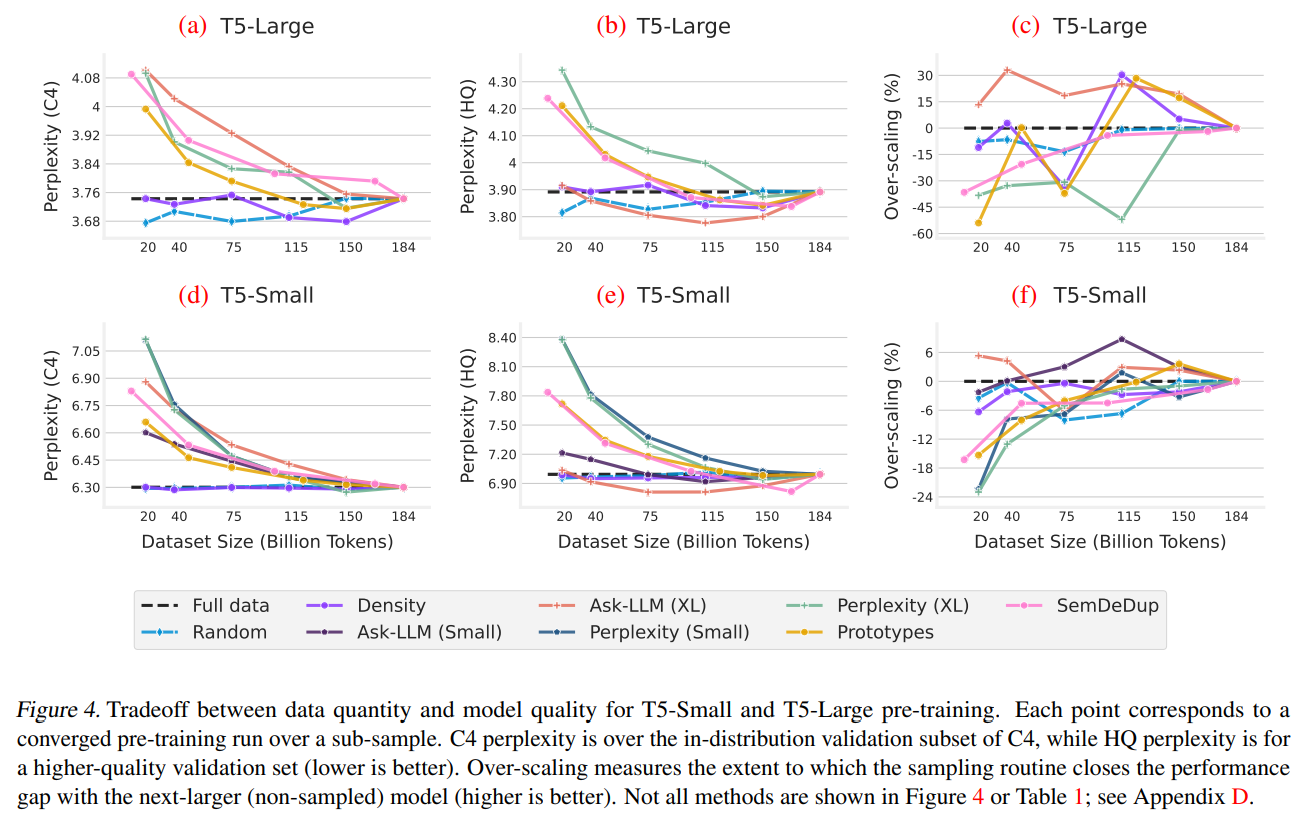
The research outcomes underscore the efficacy of these approaches:
- Models trained with ASK-LLM-selected data consistently outperformed those trained with the full dataset, demonstrating the value of quality-focused data selection.
- DENSITY sampling matched the performance of models trained on complete datasets by ensuring diverse linguistic coverage, highlighting the importance of variety in training data.
- The combination of these methods presents a compelling case for a more discerning approach to data selection, capable of achieving superior model performance while potentially lowering the resource requirements for LLM training.
In conclusion, exploring data-efficient training methodologies for LLMs reveals a promising avenue for enhancing AI model development. The significant findings from this research include:
- The introduction of ASK-LLM and DENSITY sampling as innovative techniques for optimizing training data selection.
- Demonstrated improvements in model performance and training efficiency through strategic data curation.
- Potential for reducing the computational and environmental costs associated with LLM training, aligning with broader sustainability and efficiency goals in AI research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.