This Machine Learning Survey Paper from China Illuminates the Path to Resource-Efficient Large Foundation Models: A Deep Dive into the Balancing Act of Performance and Sustainability
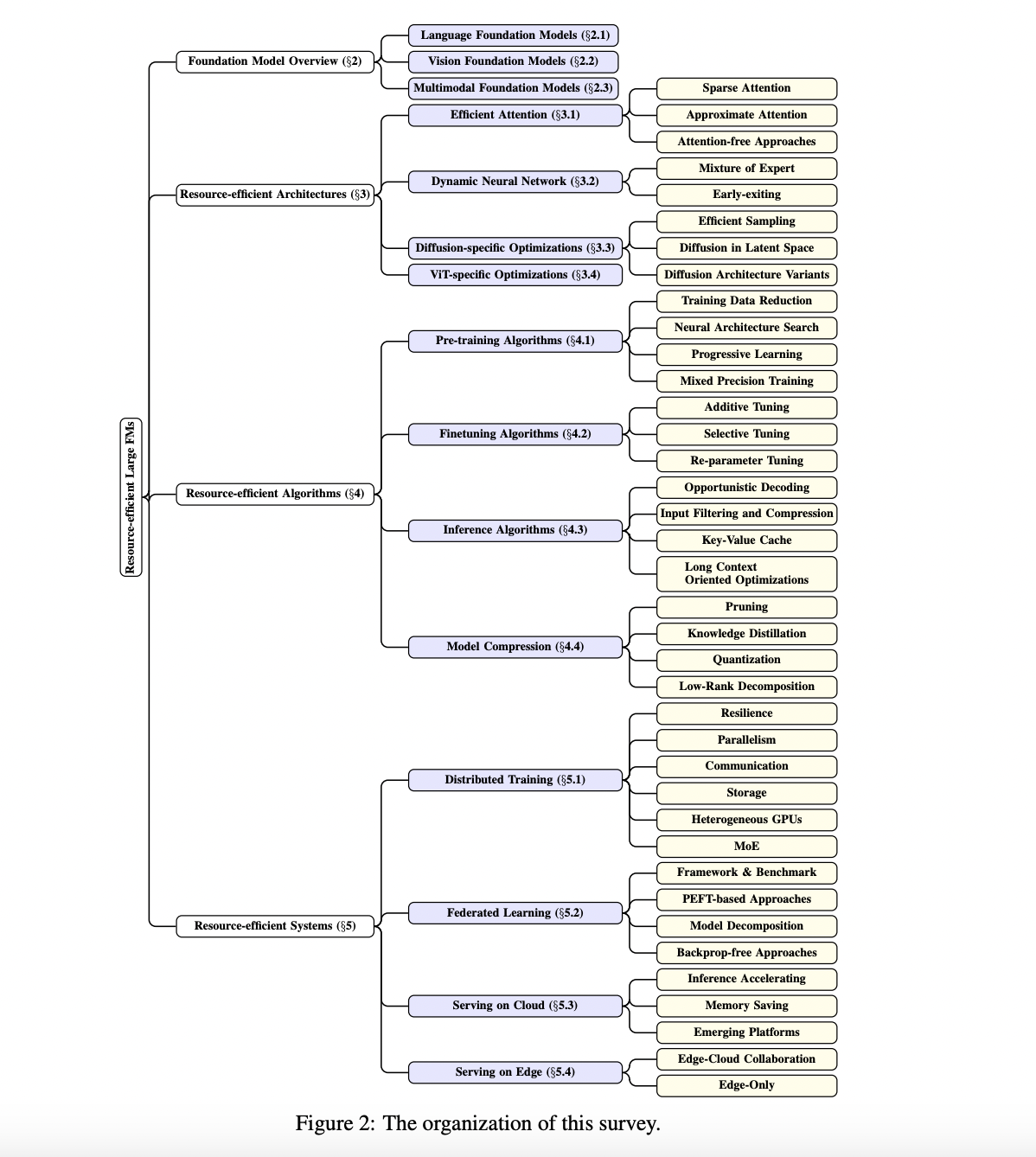
Developing foundation models like Large Language Models (LLMs), Vision Transformers (ViTs), and multimodal models marks a significant milestone. These models, known for their versatility and adaptability, are reshaping the approach towards AI applications. However, the growth of these models is accompanied by a considerable increase in resource demands, making their development and deployment a resource-intensive task.
The primary challenge in deploying these foundation models is their substantial resource requirements. The training and maintenance of models such as LLaMa-270B involve immense computational power and energy, leading to high costs and significant environmental impacts. This resource-intensive nature limits their accessibility, confining the ability to train and deploy these models to entities with substantial computational resources.
In response to the challenges of resource efficiency, significant research efforts are directed toward developing more resource-efficient strategies. These efforts encompass algorithm optimization, system-level innovations, and novel architecture designs. The goal is to minimize the resource footprint without compromising the models’ performance and capabilities. This includes exploring various techniques to optimize algorithmic efficiency, enhance data management, and innovate system architectures to reduce the computational load.
The survey by researchers from Beijing University of Posts and Telecommunications, Peking University, and Tsinghua University delves into the evolution of language foundation models, detailing their architectural developments and the downstream tasks they perform. It highlights the transformative impact of the Transformer architecture, attention mechanisms, and the encoder-decoder structure in language models. The survey also sheds light on speech foundation models, which can derive meaningful representations from raw audio signals, and their computational costs.
Vision foundation models are another focus area. Encoder-only architectures like ViT, DeiT, and SegFormer have significantly advanced the field of computer vision, demonstrating impressive results in image classification and segmentation. Despite their resource demands, these models have pushed the boundaries of self-supervised pre-training in vision models.
A growing area of interest is multimodal foundation models, which aim to encode data from different modalities into a unified latent space. These models typically employ transformer encoders for data encoding or decoders for cross-modal generation. The survey discusses key architectures, such as multi-encoder and encoder-decoder models, representative models in cross-modal generation, and their cost analysis.
The document offers an in-depth look into the current state and future directions of resource-efficient algorithms and systems in foundation models. It provides valuable insights into various strategies employed to address the issues posed by these models’ large resource footprint. The document underscores the importance of continued innovation to make foundation models more accessible and sustainable.
Key takeaways from the survey include:
- Increased resource demands mark the evolution of foundation models.
- Innovative strategies are being developed to enhance the efficiency of these models.
- The goal is to minimize the resource footprint while maintaining performance.
- Efforts span across algorithm optimization, data management, and system architecture innovation.
- The document highlights the impact of these models in language, speech, and vision domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.