This New Method Trains AI Models With Multi-Label Classification Data Using Adaptive Resonance Theory-Based Clustering
With the recent developments of IoT technology, it has become relatively easy to obtain a large amount of data and use them for machine learning algorithms. Engaging in ongoing learning is becoming increasingly crucial for machine learning algorithms to use the data effectively. One of the machine learning algorithms is Classification. A classification algorithm is a supervised learning technique in which new data is classified based on the training data. The program learns from examples and categorizes the new data, such as the picture of a cat/dog, whether the mail is spam or not, etc. There can be two types of Classification:
- Binary Classification: if the output label has only two possible outcomes, it is known as binary Classification, e.g., spam or not, yes or no, cat or dog.
- Multi-class Classification: If the output label has more than two outcomes, it is known as multi-class Classification. E.g., classifying types of music or types of crops.
Traditional machine learning mainly addresses single-label classification issues, wherein there is a one-to-one relationship between the data and the related phenomena or objects (label information). However, there is rarely a one-to-one match between data and label information.
Hence, in recent years the focus has shifted to multi-class label classification problems in which there is a one-to-many relation between the data set and the labels. For example, while predicting the category of a movie, it can be labeled as an adventure, action, horror, etc. Additionally, the capacity to learn over time without erasing previously acquired knowledge is necessary for effectively exploiting continuously amassed massive data.
👉 Read our latest Newsletter: Microsoft’s FLAME for spreadsheets; Dreamix creates and edit video from image and text prompts……
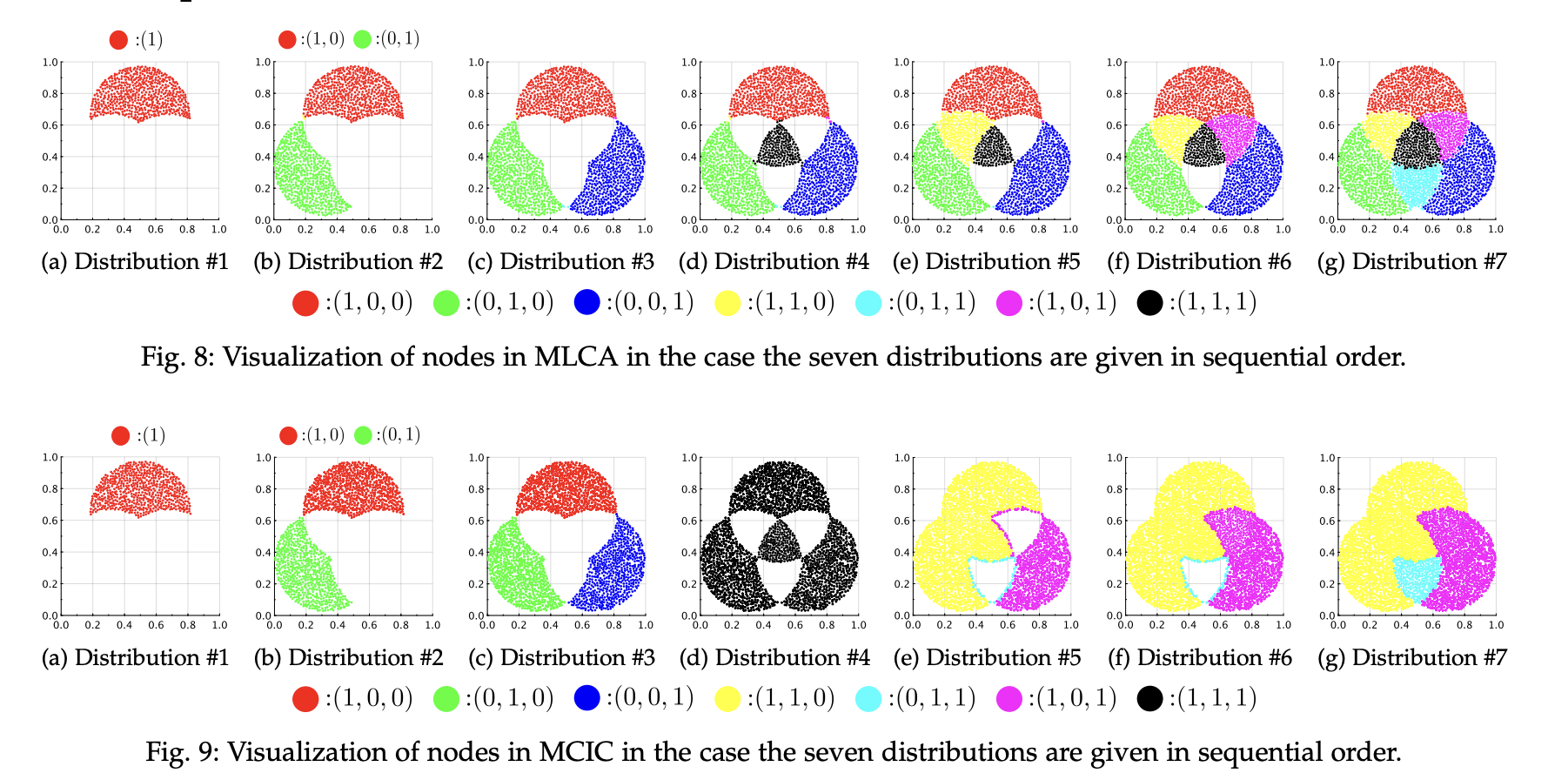
A research team from Osaka Metropolitan University’s Graduate School of Informatics, coordinated by Associate Professor Naoki Masuyama and Professor Yusuke Nojima, published a paper on Multi-label Classification via Adaptive Resonance Theory-based Clustering. Multi-label classification receives much attention from machine learning and related topics like web mining, rule mining, and information retrieval since real-world phenomena and objects are complicated and may have numerous interpretations. Hence the team has devised a new method that combines classification problem data with multiple labels with the capacity to learn new things from data over time. The proposed method outperformed conventional methods when experimented on real-world multi-label datasets.
In this paper, researchers proposed Multi-Label CIM-based ART (MLCA), which integrates the Bayesian approach for label probability computation into the ART-based clustering with the CIM to achieve a multi-label classification algorithm capable of continuous learning. Additionally, to enhance the classification performance of MLCA, researchers provided two versions of the algorithm. This is done by changing the CIM’s calculation approach. According to empirical investigations, the paper’s contributions are: Recent multi-label classification algorithms can’t match the classification performance of the MLCA and its derivatives. The use and superiority of MLCA’s ability to learn continuously are explored from various angles. This new algorithm’s simplicity makes it simple to create an evolved version that may be used in conjunction with other algorithms. An underlying clustering algorithm is helpful for ongoing big data preparation because it groups data based on similar data entries.
The CIM-based ART and the Bayesian technique for label probability computation make up the two halves of the suggested algorithms. The proposed algorithms can achieve continuous learning since both parts can handle a scenario in which new training cases and accompanying labels are successively delivered. The results of in-depth studies from both qualitative and quantitative angles demonstrated that MLCA has competitive classification performance to other well-known algorithms while keeping the capability of continuous learning. The outcomes also showed that by changing the CIM’s calculation strategy, MLCA’s performance might improve.
Thus, this new method will significantly benefit the emerging AI industry.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.