Tinkoff Researchers Unveil ReBased: Pioneering Machine Learning with Enhanced Subquadratic Architectures for Superior In-Context Learning
New standards are being set across various activities by Large Language Models (LLMs), which are causing a revolution in natural language processing. Despite their successes, most of these models rely on attention mechanisms implemented in Transformer frameworks. Impractical computing complexity for extending contextual processing is caused by these techniques, which scale poorly with large text sequences.
Several substitutes for Transformers were put forward to deal with this limitation. To avoid the quadratic difficulty of the series length, some research has proposed switching out the exponential function for the kernel function in the attention mechanism. This would reorder the computations. Nevertheless, this method diminishes performance when contrasted with plain old Transformers. Additionally, there is still no resolution to the issue of kernel function selection. State Space Models (SSMs) provide an alternate method of linear model definition; when evaluated with the complexity of language modeling, they can produce results on par with Transformers.
Note that Linear Transformers and SSMs are both Recurrent Neural Networks (RNNs) types. However, as data volumes grow, RNNs have problems managing long-term text dependencies due to memory overflow. In addition, SSMs demonstrated superior text modeling quality, even though Linear Transformers had a bigger hidden state than RNNs. To tackle these issues, the Based model was introduced with a hybrid design that combined a Linear Transformer with a new kernel function obtained from an exponential function’s Taylor expansion. While tested on the Multi-Query Associative Recall (MQAR) task, research showed that the based model performed better than others when dealing with longer content. Unlike the traditional transformer architecture, even the Based model suffers a performance decline in the presence of broad contexts.
To progress with the Based architectures, one must have a deep understanding of the processes taking place within them. Researchers from Tinkoff claim that the kernel function used in Based is not ideal and has limits when dealing with long context and small model capacity based on their examination of the attention score distribution.
In response, the team presented ReBased, an improved variant of the Linear Transformer model. Their main focus was fixing Based’s attention process bug, which prevented it from disregarding certain tokens with zero probability. A model that simplifies the calculation of the attention mechanism and improves accuracy on tasks involving retrieving information from long sequences of tokens was developed by refining the kernel function and introducing new architectural improvements.
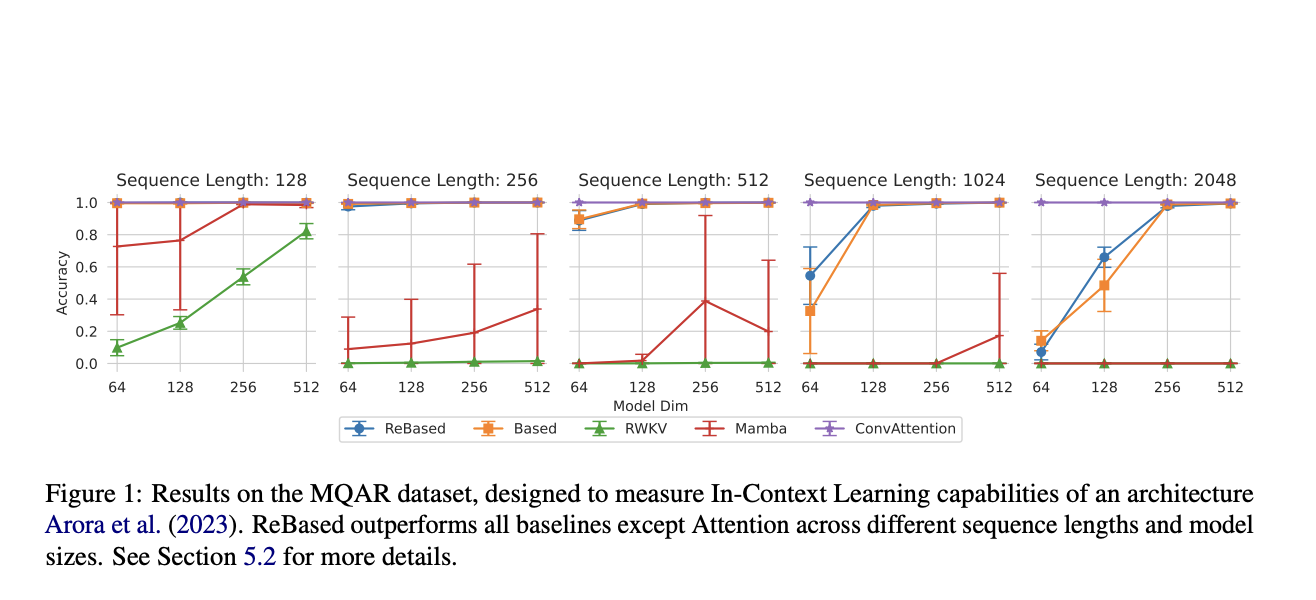
The researchers found that ReBased is more similar to attention than Based after comparing its internal representation with that of Based and vanilla attention modules. Unlike Based’s usage of a Taylor expansion of an exponential function, a ReBased kernel function differs from the exponent yet demonstrates superior performance. The findings suggest that a second-order polynomial isn’t enough for optimal performance and that more advanced learnable kernels could be used to boost trained models’ efficiency. Normalization has the potential to enhance numerous kernel functions even more. This shows that academics should look again at traditional kernel-based methods to see if they can make them more flexible and efficient. The research shows that attention-based models, particularly as sequence lengths grow, perform much worse than other models, Based on the MQAR challenge. Using the MQAR task to evaluate their improved architecture, ReBased outperforms the original Based model in various scenarios and with different model sizes. The findings also show that ReBased outperformed its predecessor in In-Context Learning and modeled associative dependencies exceptionally well using enhanced perplexity measures after training with the Pile dataset.
Compared to non-attention models, attention models perform far better on longer sequences. Further study into strategies that could bridge this gap and attain the performance of attention-based methods is necessary, as highlighted by these data. It is possible that other models can meet or even surpass the better features of attention processes, particularly on associative recall tasks like machine translation. This might be better understood, leading to more effective models for handling lengthy sequences on different natural language processing tasks.
The team highlights that their proposed approach works well for most jobs that Transformers are used for, but how well it handles tasks that need extensive copying or remembering past context is still up in the air. To completely alleviate inference issues related to attention mechanisms, it is essential to handle these jobs effectively. Furthermore, it should be mentioned that the models tested in the research are of an academic scale only. Specifically, when trying to apply the results to bigger models, this does provide some restrictions. Despite these limitations, they believe that their findings shed light on the method’s potential effectiveness.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.