Tiny Titans Triumph: The Surprising Efficiency of Compact LLMs Exposed!
In the rapidly advancing field of natural language processing (NLP), the advent of large language models (LLMs) has significantly transformed. These models have shown remarkable success in understanding and generating human-like text across various tasks without specific training. However, the deployment of such models in real-world scenarios is often hindered by their substantial demand for computational resources. This challenge has prompted researchers to explore the efficacy of smaller, more compact LLMs in tasks such as meeting summarization, where the balance between performance and resource utilization is crucial.
Traditionally, text summarization, particularly meeting transcripts, has relied on models requiring large annotated datasets and significant computational power for training. While these models achieve impressive results, their practical application is limited due to the high costs associated with their operation. Recognizing this barrier, a recent study explored whether smaller LLMs could serve as a viable alternative to their larger counterparts. This research focused on the industrial application of meeting summarization, comparing the performance of fine-tuned compact LLMs, such as FLAN-T5, TinyLLaMA, and LiteLLaMA, against zero-shot larger LLMs.
The study’s methodology was thorough, employing a range of compact and larger LLMs in an extensive evaluation. The compact models were fine-tuned on specific datasets, while the larger models were tested in a zero-shot manner, meaning they were not specifically trained on the task at hand. This approach allowed for directly comparing the models’ abilities to summarize meeting content accurately and efficiently.
Remarkably, the research findings indicated that certain compact LLMs, notably FLAN-T5, could match or even surpass the performance of larger LLMs in summarizing meetings. FLAN-T5, with its 780M parameters, demonstrated comparable or superior results to larger LLMs with parameters ranging from 7B to over 70B. This revelation points to the potential of compact LLMs to offer a cost-effective solution for NLP applications, striking an optimal balance between performance and computational demand.
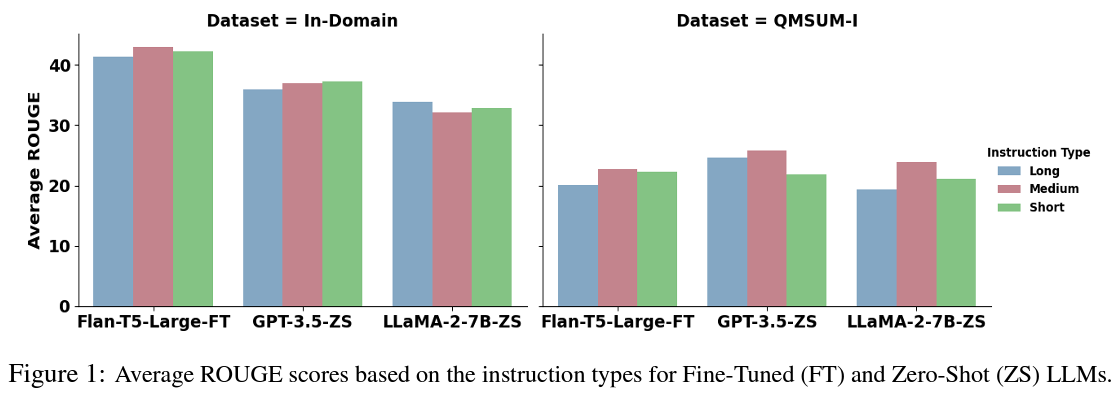
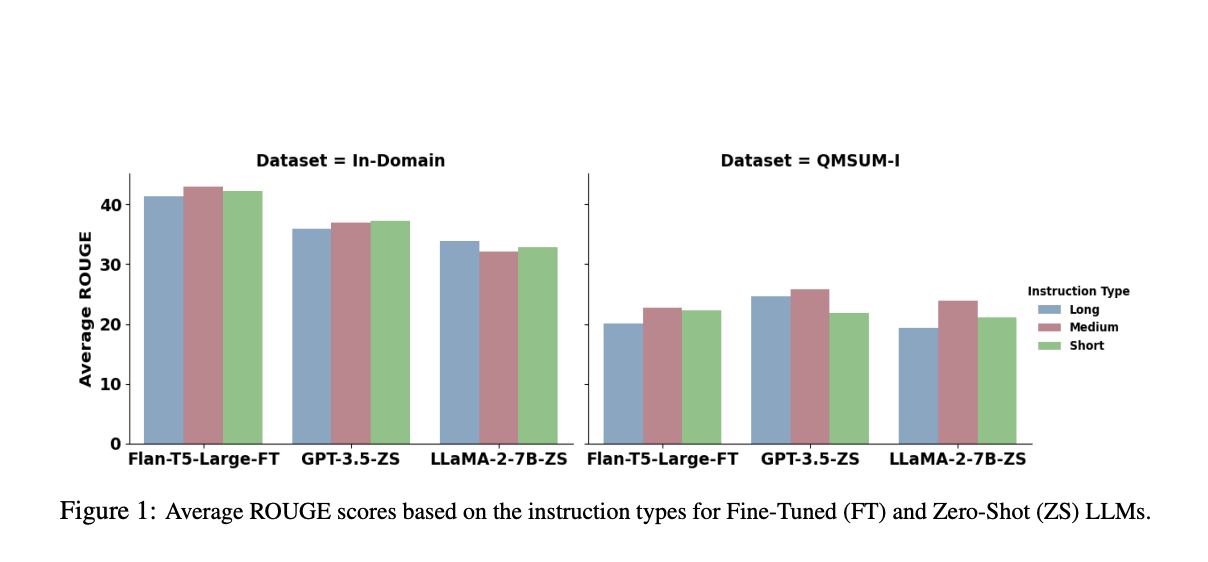
The performance evaluation highlighted FLAN-T5’s exceptional capability in the meeting summarization task. For instance, FLAN-T5’s performance was on par with, if not better, many larger zero-shot LLMs, underscoring its efficiency and effectiveness. This result highlights the potential of compact models to revolutionize how we deploy NLP solutions in real-world settings, particularly in scenarios where computational resources are limited.
In conclusion, the exploration into the viability of compact LLMs for meeting summarization tasks has unveiled promising prospects. The standout performance of models like FLAN-T5 suggests that smaller LLMs can punch above their weight, offering a feasible alternative to their larger counterparts. This breakthrough has significant implications for deploying NLP technologies, indicating a path forward where efficiency and performance go hand in hand. As the field continues to evolve, the role of compact LLMs in bridging the gap between cutting-edge research and practical application will undoubtedly be a focal point of future studies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.