Tired of Tuning Learning Rates? Meet DoG: A Simple Parameter-Free Optimizer Backed by Solid Theoretical Guarantees
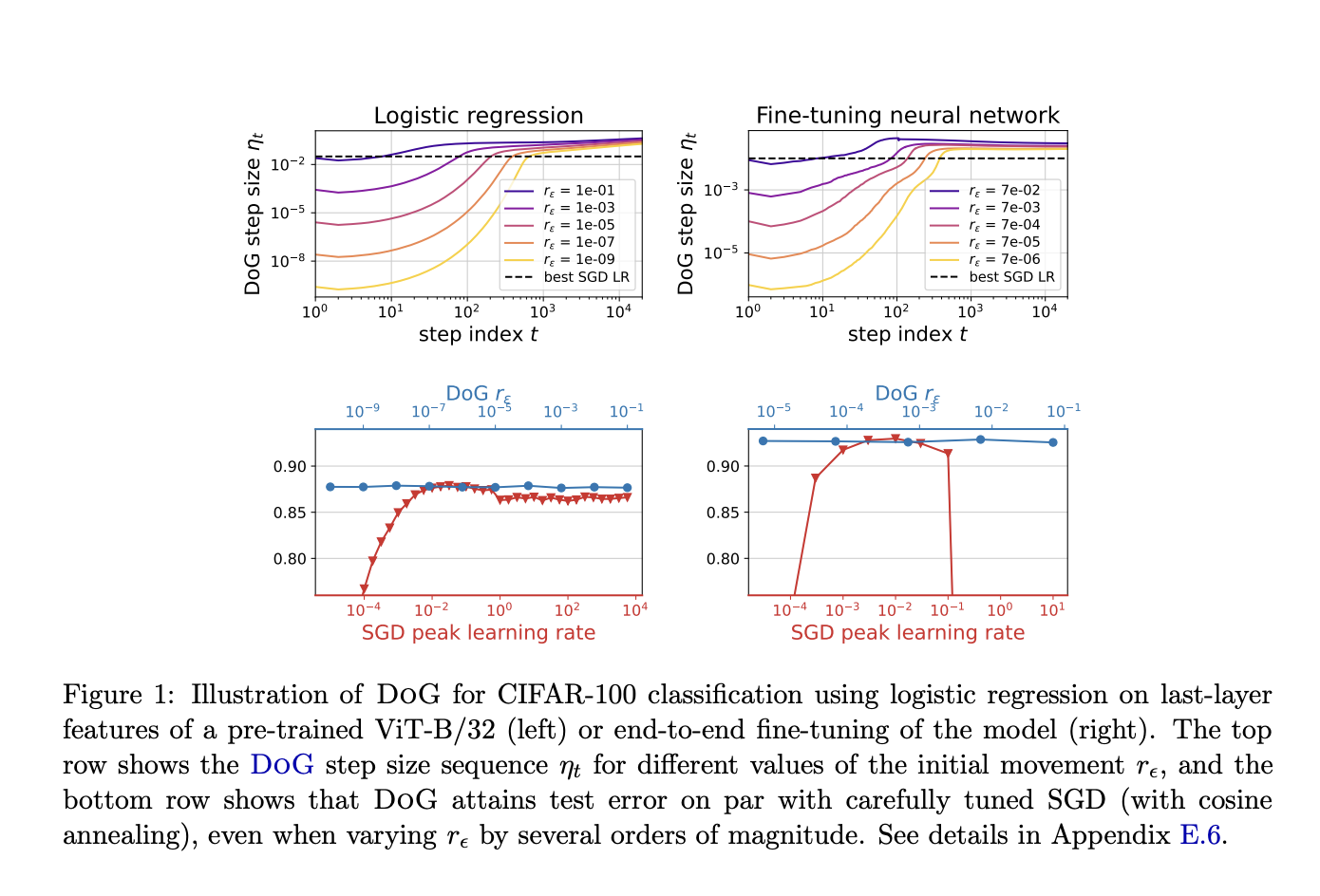
Researchers at Tel Aviv University propose tuning free dynamic SGD step size formula, called Distance over Gradients (DoG), which only depends upon the empirical quantities with no learning rate parameter. They theoretically show that a slight variation in the DoG formula would lead to locally bounded stochastic gradients converging.
A stochastic process requires an optimized parameter, and the learning rate remains difficult. The previous successful methods include selecting a suitable learning rate from the prior work. Methods like adaptive gradient methods require the learning rate parameter to be tuned. A parameter-free optimization doesn’t require tunning, as algorithms are designed to achieve a near-optimal rate of convergence with no prior knowledge of the problem.
Researchers at Tel Aviv University adopt the key insights from Carmon and Hinder and develop a parameter-free step-size schedule. They show that upon iterating DoG, there exists a high probability that DoG archives a convergence rate which is logarithmic. However, the DoG is not always stable. Its iterations can move farther away from the optimization. So, they use a variant of DoG, which they call T-DoG, in which the step size is smaller by a logarithmic factor. They obtain a high probability, which ensures convergence.
Their results, when compared to SGD, show that with a cosine step size schedule and tuned-based learning, DoG rarely attains a relative error improvement of more than 5% but for the convex problems, the relative difference in error is below 1%, which is astonishing. Their theory also predicts that DoG performs consistently over a large range of sensitivity. Researchers also used fine-tuned transformer language models to test the efficiency of DoG in modern Natural language understanding (NLU).
Researchers also performed limited experiments on the main fine-tuning testbed with ImageNet as a downstream task. These are more expensive to tune with an increase in the scale. They fine-tuned the CLIP model and compared it with DoG and L-DoG. They find that both algorithms perform significantly worse. It is due to an insufficient iteration budget.
Researchers experimented with training a model from scratch with polynomial averaging. The DoG performs well compared to SGD, with a momentum of 0.9 and a learning rate of 0.1. Upon comparison to other tuning-free methods, DoG and L-DoG provide better performance on most of the tasks.
Though the results of DoG are promising, much additional work is necessary for these algorithms. Well-proven techniques such as momentum, pre-parameter learning rates, and learning rate annealing need to be combined with DoG, which turns out to be challenging both theoretically and experimentally. Their experiments suggest a connection to batch normalization, which can even lead to robust training methods.
At last, their theory and experiments suggest DoG has the potential to save significant computation currently spent on learning rate tuning at little or no cost in performance.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.