Tnt-LLM: A Novel Machine Learning Framework that Combines the Interpretability of Manual Approaches with the Scale of Automatic Text Clustering and Topic Modeling
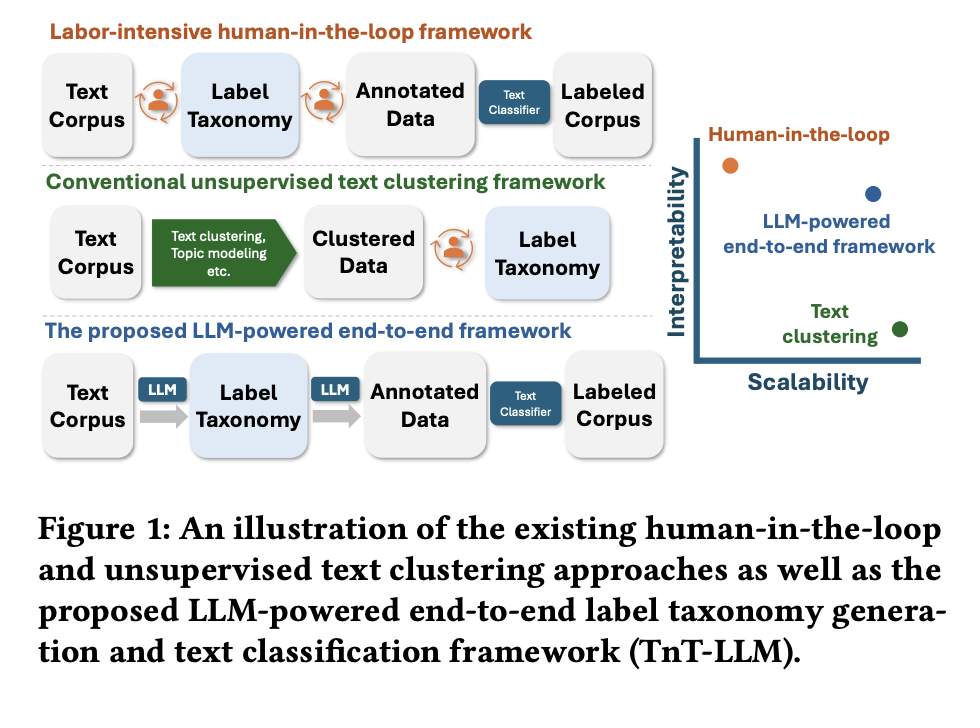
The term “text mining” refers to discovering new patterns and insights in massive amounts of textual data. Generating a taxonomy—a collection of structured, canonical labels that characterize features of the corpus—and text classification—the labeling of instances within the corpus using said taxonomy—are two fundamental and related activities in text mining. This two-step process can be recast as several practical use cases, particularly when the label space is ill-defined or while investigating an unexplored corpus. Similarly, intent detection includes labeling text material (such as chatbot transcripts or search queries) with the intent labels and then classifying the content (such as “book a flight” or “buy a product”).
A well-established method for accomplishing both goals is to assemble a label taxonomy with the help of domain experts. Then, to train a machine learning model for text classification, one must collect human annotations on a small number of corpus samples using this taxonomy. Although these human-in-the-loop methods are very interpretable, they are quite difficult to scale. In addition to being error- and bias-prone, manual annotation is expensive, time-consuming, and requires domain knowledge. Label consistency, granularity, and coverage must also be carefully considered. Also, for any use case further down the line (sentiment analysis, intent detection, etc.), you must perform it all over again. Machine learning methods such as text clustering, topic modeling, and phrase mining are part of an alternative area of research that attempts to address these scalability concerns. In this approach, the label taxonomy is derived by characterizing the learned clusters rather than the other way around. This is done by first grouping the corpus sample into clusters in an unsupervised or semi-supervised fashion. Some have compared the difficulty of defining text clusters consistently and understandably to “reading tea leaves,” even though such methods scale better with larger corpora and more use cases.
To tackle these issues, researchers from Microsoft Corporation, and University of Washington present TnT-LLM, a new framework that merges the comprehensibility of human methods with the scalability of automated topic modeling and text clustering. TnT-LLM is a two-stage approach that uses the distinct advantages of training after Large Language Models (LLMs) in both stages to generate taxonomies and classify texts.
To start, the researchers come up with a zero-shot multi-stage reasoning method for the taxonomy creation phase. This method tells an LLM to create and improve a label taxonomy for a specific use-case (such intent detection) repeatedly based on the corpus. Second, to train lightweight classifiers that can handle large-scale labeling, they take advantage of LLMs as data augments throughout the text classification phase to increase the production of training data. With minimal human involvement, this framework may be easily modified to accommodate various use cases, text corpora, LLMs, and classifiers because of its modular design and adaptability.
The team provides a set of quantitative and traceable assessment methodologies to validate each level of this paradigm. These tactics include deterministic automatic metrics, human evaluation metrics, and LLM-based evaluations. Bing Copilot (formerly Bing Chat) is a web-scale, multilingual, open-domain conversational agent, and they analyze its talks using TnT-LLM. Compared to the most advanced text clustering methods, the findings demonstrate that the suggested framework can produce label taxonomies that are both more accurate and relevant. In addition, they show that lightweight label classifiers trained on LLM annotations can outperform LLMs used as classifiers directly, occasionally even better, while having significantly superior scalability and model transparency. This work offers insights and suggestions for using LLMs on large-scale text mining based on quantitative and qualitative investigation.
In future work, the researchers plan to investigate hybrid approaches that combine LLMs with embedding-based methods in order to increase the framework’s speed, efficiency, and resilience, as well as model distillation, which refines a smaller model by using instructions from a bigger one. They also aim to investigate methods for doing more reliable LLM-assisted assessments, such as training a model to reason beyond pair judgment tasks, since evaluation is an important and unanswered question in the field. Although most of this work has been on conversational text mining, they are interested in seeing if this approach may be applied to other domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.