To help Ukraine, Berkeley AI Researchers Provide Machine Learning Methods And Pretrained Models To Interchangeably Use Any Imagery
Extracting knowledge and actionable insights by manually processing hundreds of terabytes of data downlinked from satellites to data centers has become difficult.
Synthetic aperture radar (SAR) imaging is a type of active remote sensing in which a satellite sends microwave radar wave pulses down to the Earth’s surface. These radar signals return to the satellite after reflecting off the Earth and any objects. A SAR image is created by processing these pulses over time and space, with each pixel representing the superposition of multiple radar scatters. Radar waves penetrate clouds and illuminate the Earth’s surface even during nights because the satellite is actively creating them.
They produce visual that is sometimes contradictory and incompatible with modern computer vision systems. Three common effects are polarisation, layover, and multi-path.
- The layover effect occurs when radar beams reach the top of a structure before reaching the bottom. This causes the top of the object to appear to be overlapping with the bottom.
- When radar waves reflect off objects on the ground and bounce numerous times before returning to the SAR sensor, this is known as multi-path effects. Multi-path effects cause things in the picture to appear in multiple transformations in the final image.
Existing computer vision approaches based on typical RGB pictures aren’t designed to account for these impacts. The current techniques can be applied to SAR imagery but with lower performance and systemic mistakes that can only be handled with a SAR-specific approach.
During the present invasion of Ukraine, satellite imagery is a key source of intelligence. Many types of satellite images cannot observe the ground in Ukraine due to a high level of cloud cover and attacks that frequently occur at night. Cloud-piercing synthetic aperture radar (SAR) imagery is available, but it requires expertise. Image analyzers are forced to rely on manual analysis, which is time-consuming and prone to errors. Automating this time-consuming procedure would allow for real-time analysis, but current computer vision approaches based on RGB pictures do not adequately account for the phenomenology of SAR.
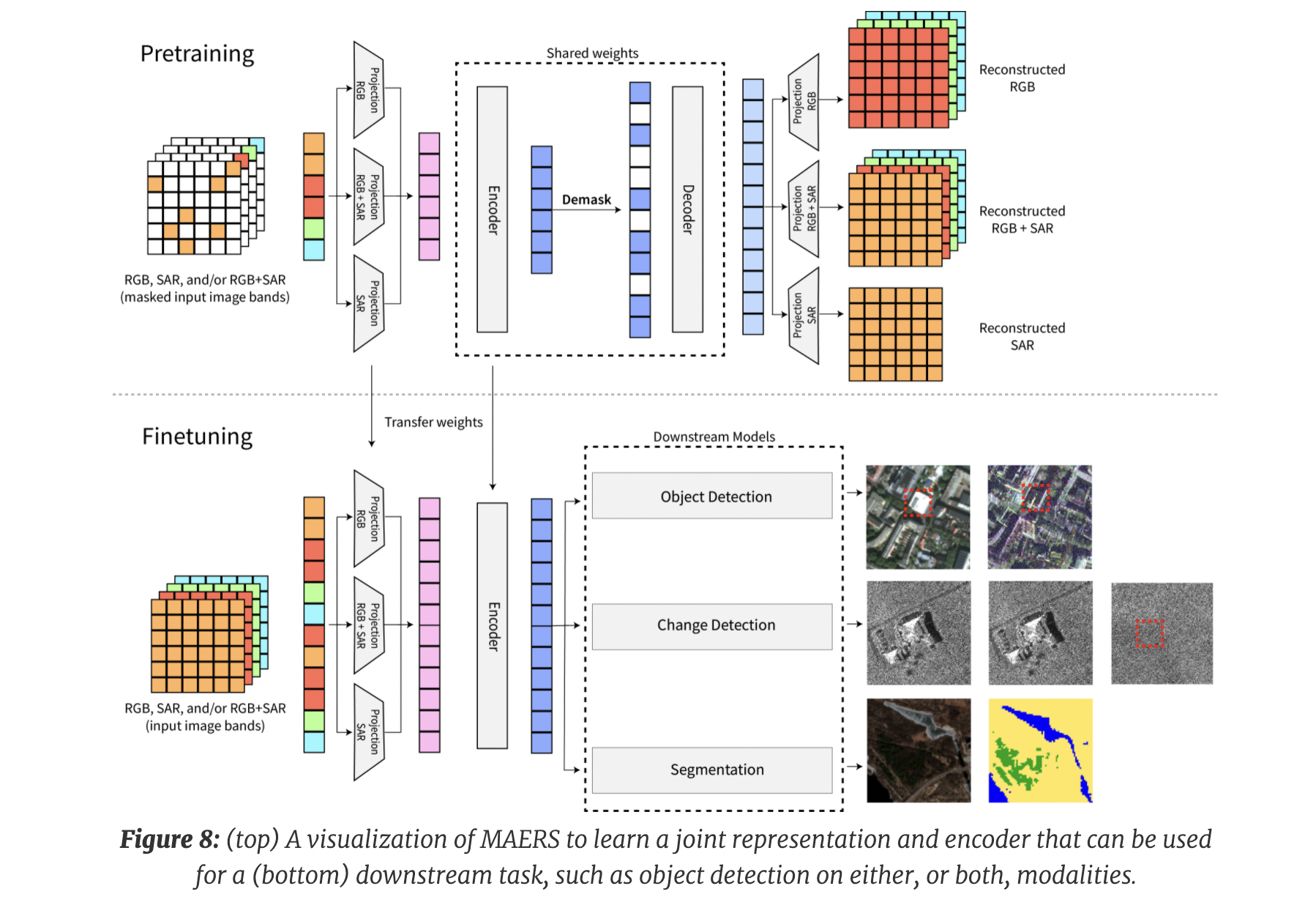
To overcome these issues, the team at Berkeley AI Research developed an initial set of algorithms and models that learned robust representations for RGB, SAR, and co-registered RGB + SAR imagery. The researchers used the publicly available BigEarthNet-MM dataset and data from Capella’s Open Data, which includes both RGB and SAR imagery. Imagery analysts can now use RGB, SAR, or co-registered RGB+SAR imagery interchangeably for downstream tasks such as picture classification, semantic segmentation, object detection, and change detection utilizing our models.
The researchers remark that the Vision Transformer (ViT) is a particularly excellent design for representation learning with SAR because it removes the scale and shift-invariant inductive biases built into convolutional neural networks.
MAERS is the top-performing method for representation learning on RGB, SAR, and co-registered RGB + SAR. It is based on Masked Autoencoder (MAE). The network takes a masked version of input data and learns to encode it. Then it learns to decode the data so that it reconstructs the unmasked input data. Unlike many other contrastive learning approaches, the MAE does not require particular augmentation invariances in the data that may be erroneous for SAR features. Instead, it relies only on reconstructing the original input, regardless of whether it is RGB, SAR, or co-registered.
MAERS enhances MAE by:
- Learning independent RGB, SAR, and RGB+SAR input projection layers
- Encoding the output of these projected layers with a shared ViT
- Using independent output projection layers to decode them to RGB, SAR, or RGB+SAR channels.
The input encoder can accept RGB, SAR, or RGB+SAR as input, and the shared ViT and input projection layers can then be shifted to downstream tasks like object detection or change detection.
The team states that content-based image retrieval, classification, segmentation, and detection can benefit from learning representations for RGB, SAR, and co-registered modalities. They evaluate their method on well-established benchmarks for:
- Multi-label classification on BigEarthNet-MM dataset
- Semantic segmentation on the VHR EO and SAR SpaceNet 6 dataset.
Their findings suggest that fine-tuned MAERS beats the top RGB+SAR results from the BigEarthNet-MM study. This demonstrates that adapting the MAE architecture for representation learning yields State-of-the-Art results.

They also used transfer learning for semantic segmentation of building footprints, a prerequisite for performing building damage assessment. This would help imagery analysts grasp the disaster in Ukraine.
They used the SpaceNet 6 dataset as an open and public benchmark to demonstrate the effectiveness of the learned representations for detecting building footprints with Capella Space’s VHR SAR. Compared to training the RGB+SAR model from scratch or adjusting ImageNet weights with the same architecture, the MAERS pretrained model improves by 13 points.
This research demonstrates that MAERS may learn strong RGB+SAR representations that allow practitioners to perform downstream tasks using EO or SAR images interchangeably.
The researchers intend to continue their research with comprehensive experiments and standards. They will help humanitarian partners use these models to perform change detection over residential and other civilian areas, allowing for better tracking of war crimes in Ukraine.
Reference: https://bair.berkeley.edu/blog/2022/03/21/ukraine-sar-maers/
Suggested
Credit: Source link
Comments are closed.