Top Neural Network Architectures For Machine Learning Researchers
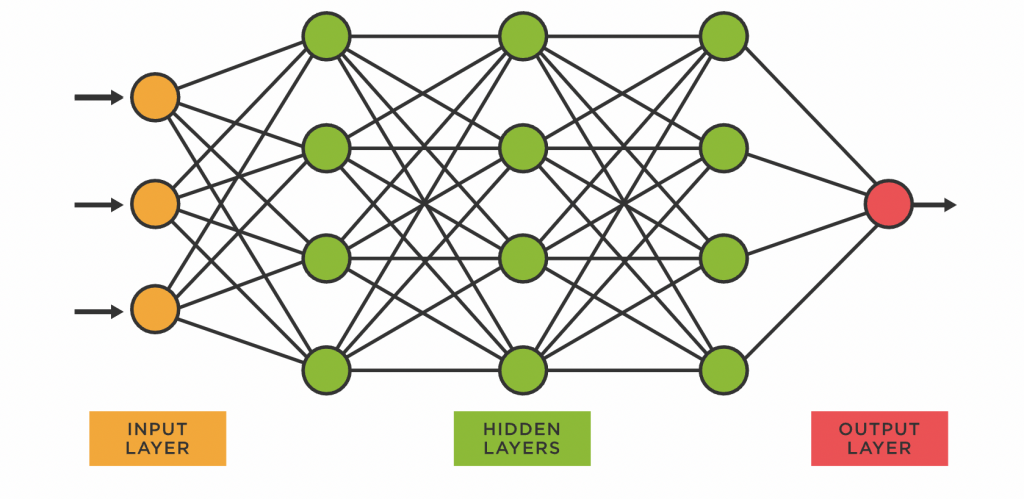
The neural networks discussed are specifically referred to as artificial neural networks. As the name implies, they are based on what is known about the structure and operation of the human brain.
A neural network is a computing system composed of several crucial yet intricately linked parts, sometimes called “neurons,” stacked in layers and processing data using dynamic state reactions to outside inputs. In this structure, designs are communicated to one or more hidden layers present in the network by the input layer, which in this structure has one neuron for each component present in the input data. These layers are only referred to as “hidden” because they do not make up the input or output layer. This method is quite helpful in locating patterns that are too complex to manually obtain and train into the computer, as we will see later.

All of the processing actually takes place in the hidden layers through a network of connections known as weights and biases (W and b): after receiving the input, the neuron calculates a weighted sum while also including the prejudice and then uses the result along with a preset activation function—the most popular of which is the sigmoid function, though better ones like ReLu are also available—to determine whether it should be “fired” or activated. The neuron transmits the data in a “forward pass” process to other linked neurons. At the end of this process, the final hidden layer is connected to the output layer, which has one neuron for each potential desired output.
Top Neural Network Architectures
Perceptrons
Perceptrons, merely computational representations of a single neuron, are regarded as the initial generation of neural networks. The perceptron, also known as a feed-forward neural network, feeds data from the front to the back. The neuron receives information, processes them, and produces a result. Backpropagation is typically required for perceptron training, providing the network with paired datasets of inputs and outputs. The discrepancy between the input and the outcome is frequently one of the many variations of the error being backpropagated. Theoretically, the network can always model the relationship between the input and output if there are enough hidden neurons. Though practically much more constrained, they are frequently coupled with other networks to create new networks.

Perceptrons have some limits. However, you can achieve practically anything if you manually select the features and have enough features. We can create any kind of discrimination on binary input vectors since we can have a different feature unit for each of the exponentially many binary vectors. A perceptron’s ability to learn is severely constrained once the hand-coded features have been identified.
Convolutional Neural Networks
Contrary to most other networks, convolutional neural networks are rather unique. They can be used for various inputs, such as audio, although their primary purpose is image processing. When you input the network images to classify, that is a typical use case for CNNs. CNNs frequently begin with an input “scanner” that isn’t designed to instantly analyze all of the training data. For instance, you wouldn’t need a layer with 10,000 nodes to input an image with 100 by 100 pixels. Instead, you make a 10 x 10 scanning input layer into which you feed the image’s initial 10 x 10 pixels. After the input has been passed, you move the scanner one pixel to the right to provide the following 10 × 10 pixels.
Instead of traditional layers, where each node is connected to every other node, convolutional layers are utilized to process the input data. Each node only thinks about cells that are close to it. As they get deeper, these convolutional layers also get smaller, usually due to input components that are easily divided. They frequently include pooling layers in addition to these convolutional layers. A common pooling strategy is max pooling, where we take, for example, 2 x 2 pixels and pass on the pixel with the most red. This method of filtering out details is known as pooling.
Recurrent Neural Networks
Perceptrons are essentially what recurrent neural networks (RNNs) are made of; however, unlike perceptrons, which are stateless, RNNs contain connections between passes and connections over time. Because they combine two characteristics—distributed hidden state, which lets them store a lot of historical data quickly, and non-linear dynamics, which enables them to update their hidden state in complex ways—RNNs are incredibly powerful. RNNs are capable of computing anything your computer is capable of computing given enough time and neurons.
What types of behavior can RNNs display, then? They can oscillate, settle into point attractors, and exhibit chaotic behavior. Additionally, kids might be taught to design a large number of little programs that each capture a piece of information and execute in parallel to interact to create incredibly complex results.
Long / Short Term Memory
LSTM networks use gates and an explicitly defined memory cell to try to solve the vanishing/exploding gradient problem. LSTMs have “input gates” that add new information to the cell and “output gates” that determine when to transmit the cell’s vectors onto the following hidden state. Unless a “forget gate” instructs the memory cell to forget those values, the memory cell keeps the initial values and retains them.
Gated Recurrent Unit
A minor modification to LSTMs is gated recurrent units (GRUs). Kyunghyun Cho et al. presented gated recurrent units (GRUs) as a gating technique for recurrent neural networks in 2014. The GRU has fewer parameters than an LSTM because it doesn’t have an output gate, but it is similar to an LSTM with a forget gate. It was discovered that GRU and LSTM performed similarly on some polyphonic music modeling, speech signal modeling, and natural language processing tasks. On some smaller, less frequently used datasets, GRUs have been proven to perform better.
Hopfield Network
A Hopfield network (HN) is a network in which every neuron is linked to every other neuron; it resembles a spaghetti-like mess since every node serves as every other node. Each node receives input before training, is concealed during exercise, and is output. The weights can then be determined once the networks have been trained by changing the neurons’ values to the desired pattern. Following this, the consequences stay the same. The network will always converge to one of the learned patterns once trained in one or more ways because the network is only stable in those states.
Boltzmann Machine
A particular kind of stochastic recurrent neural network is the Boltzmann Machine. It can be thought of as the stochastic version of Hopfield nets’ generative side. It is able to represent and resolve challenging combinatorial problems. It was one of the first neural networks capable of learning internal representations. Like Hopfield Networks, Boltzmann machines have specific neurons labeled as input neurons while leaving others “hidden.” After a full network update, the input neurons change into output neurons. The neurons usually have binary activation patterns when compared to a Hopfield Net. With random weights at first, it learns by backpropagation.
Deep Belief Network
A deep belief network (DBN) is a type of deep neural network used in machine learning. It comprises numerous layers of latent variables, or “hidden units,” with connections between the layers but not between the units within each layer.
Unsupervised training on a set of instances enables a DBN to develop the ability to probabilistically recreate its inputs. After that, the layers serve as feature detectors. A DBN can be further taught under supervision to perform categorization after this learning phase.
Autoencoder
An artificial neural network called an autoencoder is used to learn effective codings for unlabeled input (unsupervised learning). By teaching the network to disregard irrelevant data (or “noise”), the autoencoder learns a representation (encoding) for a set of data, generally for dimensionality reduction. The encoding is validated and improved by attempting to regenerate the information from the encoding.
Some variations try to make the learned representations take on beneficial features. Examples include variational autoencoders, which have applications as generative models, and regularized autoencoders (Sparse, Denoising, and Contractive), which are efficient in learning representations for later classification tasks. Autoencoders solve various issues, such as word meaning acquisition, feature detection, anomaly detection, and facial recognition. Additionally, autoencoders are generative models that can generate new data at random, similar to the input data (training data).
Generative Adversarial Networks
Generative Adversarial Networks (GANs) are composed of two networks, one of which is charged with producing material (generative), and the other of which is tasked with evaluating content (judgmental) (discriminative). The discriminative model is tasked with deciding if a particular image (one from the dataset) seems natural or artificially produced. The generator’s job is to create images that appear natural and are similar to the initial data distribution. This can be viewed as a two-player zero-sum or minimax game.
The study uses the analogy that the discriminative model is “the police seeking to find the counterfeit currency.” Still, the generative model is “a team of counterfeiters, trying to make and utilize false currency.” The discriminator tries to avoid being duped by the generator, while the generator tries to trick the discriminator. Both approaches are enhanced due to the models’ training through alternating optimization, where “counterfeits are indistinguishable from the real products.”
LeNet-5
Convolutional neural networks are feed-forward neural network that excels at processing large-scale images because their artificial neurons may respond to a portion of the surrounding cells in the coverage range. LeCun et al. proposed the convolutional neural network topology LeNet in 1998. LeNet is a common term for LeNet-5, a straightforward convolutional neural network.
LeNet5’s architecture is relatively simple. Image features will be dispersed throughout the whole picture. By combining learnable parameters with convolutions, similar characteristics can be retrieved quite well. LeNet5 was developed when CPUs were extraordinarily sluggish, and no GPU was available to aid in training.
This architecture’s primary benefit is the reduction of computation and parameter usage. LeNet5 contrasted this with an elaborate multi-layer neural network where each pixel was treated as a separate input. Since the photos have strong spatial correlations, employing single pixels as distinct input features would be problematic and should not be used in the first layer.
AlexNet
AlexNet is the name of a convolutional neural network (CNN) architecture. It used the non-saturating ReLU activation function, which outperformed tanh and sigmoid in terms of training performance. The initial five layers of AlexNet were convolutional, part of them was followed by max-pooling layers, and the final three layers were fully connected.
One of the most important studies in computer vision is AlexNet, which inspired many other works using CNNs and GPUs to speed up deep learning. According to Google Scholar, the AlexNet paper has had over 80,000 citations as of 2021.
VGG
Each convolutional layer in Oxford’s VGG networks employed smaller 33 filters for the first time. Also combined as a series of convolutions were smaller 33 filters.
LeNet’s guiding principles are contrasted by VGG. Large convolutions were used to capture a set of similar features in an image. Compared to LeNet architecture, VGG used smaller filters on the network’s initial layers. Large AlexNet filters like 9 x 9 and 11 x 11 were not applied in VGG. Multiple 3 x 3 convolutions in succession made it possible to mimic the impact of larger receptive fields like 7 × 7 and 5 x 5. It was also VGG’s most important benefit. Multiple 33 convolutions are used in series in modern network architectures like ResNet and Inception.
GoogLeNet and Inception
The efficiency of server farm architectures and large deployments have come to the fore for internet behemoths like Google. The ImageNet Large-Scale Visual Recognition Challenge included the GoogLeNet, a 22-layer deep convolutional network, in 2014. GoogleNet is the first architecture developed to lighten deep neural network processing. The content of video frames and images was categorized using deep learning models.
References:
- https://towardsdatascience.com/understanding-neural-networks-what-how-and-why-18ec703ebd31
- https://www.bmc.com/blogs/neural-network-introduction/
- https://data-notes.co/a-gentle-introduction-to-neural-networks-for-machine-learning-d5f3f8987786
- https://analyticsindiamag.com/top-5-neural-network-models-for-deep-learning-their-applications/
- https://www.analyticsinsight.net/top-10-neural-network-architectures-every-ml-engineer-should-know/
- https://www.upgrad.com/blog/neural-network-architectures/
Please Don't Forget To Join Our ML Subreddit
![]()
Prathamesh Ingle is a Consulting Content Writer at MarktechPost. He is a Mechanical Engineer and working as a Data Analyst. He is also an AI practitioner and certified Data Scientist with interest in applications of AI. He is enthusiastic about exploring new technologies and advancements with their real life applications
Credit: Source link
Comments are closed.