Transforming Specialized AI Training- Meet LMFlow: A Promising Toolkit to Efficiently Fine-Tune and Personalize Large Foundation Models for Superior Performance
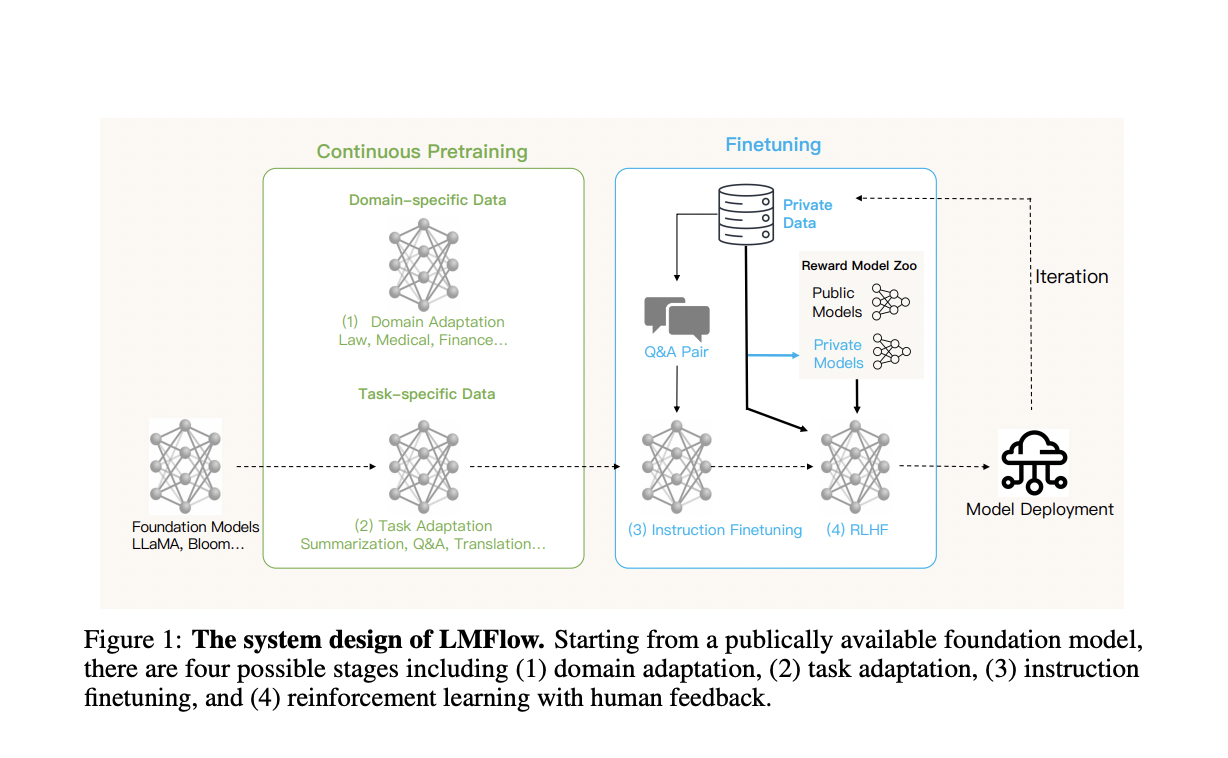
Large language models (LLMs) built on top of big foundation models have shown the general ability to execute various tasks that were impossible before. However, more finetuning of such LLMs is required to increase performance on specialized domains or jobs. Common procedures for finetuning such big models include:
- Ongoing pretraining in niche areas, allowing a broad base model to pick up expertise in such areas.
- Tuning of instructions to train a big, general-purpose base model to understand and carry out certain types of natural-language instructions.
- Training a big foundation model with the necessary conversational abilities using RLHF (reinforcement learning with human feedback).
While several big models have already been pretrained and made available to the public (GPT-J, Bloom, LLaMA, etc.), no publicly available toolbox can efficiently carry out finetuning operations across all these models.
To help developers and researchers finetune and infer huge models efficiently with constrained resources, a team of academics from Hong Kong University and Princeton University has created an easy-to-use and lightweight toolset.
One Nvidia 3090 GPU and five hours are all it takes to train a custom model based on a 7-billion-parameter LLaMA model. The team has provided the model weights for academic research after using this framework to finetune versions of LLaMA with 7, 13, 33, and 65 billion parameters on a single machine.
There are four steps to optimizing the output of a large language model that is freely available online:
- The first step, “domain adaptation,” entails training the model on a certain domain to handle it better.
- Task adaptation is the second step, and it entails training the model to accomplish a particular goal, such as summarization, question answering, or translation.
- Adjusting the model’s parameters based on instructional question-answer pairings is the third stage, instruction finetuning.
- The last step is reinforcement learning using human feedback, which entails refining the model based on people’s opinions.
LMFlow offers a full finetuning procedure for these four steps, allowing for individualized training of huge language models despite constrained computational resources.
LMFlow offers a thorough finetuning approach for big models with features like continuous pretraining, instruction tuning, and RLHF, as well as easy and flexible APIs. Individualized model training is now accessible to everyone with LMFlow. For activities like question answering, companionship, writing, translation, and expert consultations in various subjects, each person can pick a suitable model based on their available resources. If users have a large enough model and dataset, training over a longer period will yield superior outcomes. The team has recently trained a 33B model that outperforms ChatGPT.
Check Out The Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.