Twitter Releases ‘Qurious’ For Next-Generation Data Insights Using Natural Language Queries
This summary is based on Twitter's research 'Next generation data insights using natural language queries' Please don't forget to join our ML Subreddit
Twitter processes over 400 billion events in real-time and generates data on a petabyte (PB) scale. One of the most significant challenges with current data-consumption systems is the requirement for backroom processing. Before consumption, engineers and analysts must build dashboards, reports, and other items. This creates a lower data time value, affecting Twitter’s ability to make timely data-driven decisions.
The entire cost of obtaining insights from additional traits, features, and dashboards has increased. Current technologies don’t foresee and proactively uncover insights from exabytes of data based on what our internal business customers could find beneficial, resulting in missed opportunities.
Many studies suggest a comprehensive and resilient big data platform’s infrastructure for data processing, storage, and data consumption. We have robust infrastructure across the industry for processing petabytes of data and storing large amounts of data, such as distributed blob stores. However, obtaining timely, meaningful, and actionable insights from these exabyte-scale data systems via dashboards, visualizations, and reports remains non-trivial.
Advances in natural language processing and machine learning have made it possible to make data consumption from exascale platforms for insights both easy and timely.
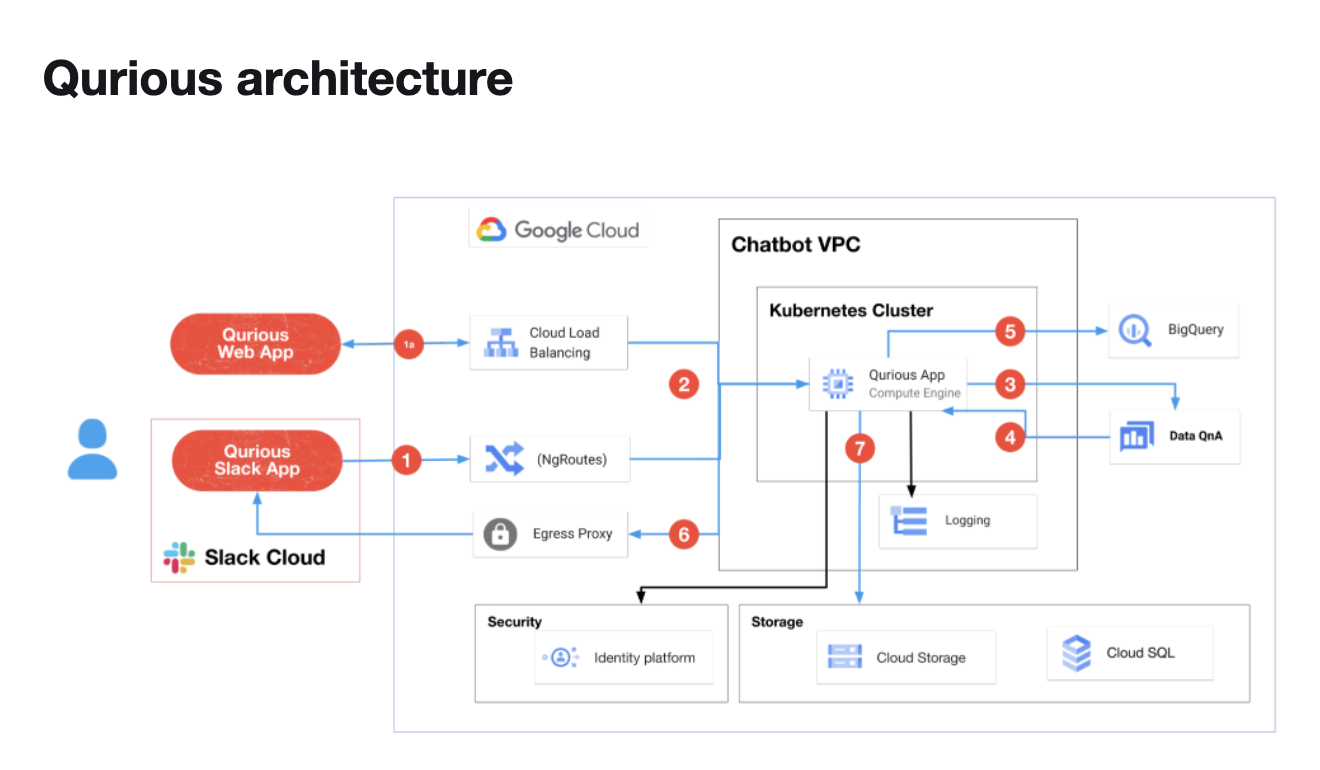
Twitter has recently released Qurious, a new in-house product that allows internal business customers to ask inquiries in natural language. The product consists of a web app and a Slack chatbot connected to BigQuery and Data QnA APIs. The Slack chatbot was created with node.js and the Express Framework, based on a Google Data QnA reference implementation. They are then offered real-time analytics without having to construct dashboards.
The slack chatbot model saves the token and session information in a DataStore database based on the Slack user id. The token helps in maintaining connectivity across devices by using Slack. Further, the session value is stored in local storage variables in the web app model.
The team used Google Cloud Platform and internal Twitter services to create the app. This includes the following:
Google Kubernetes Engine (GKE): It is a fully managed Kubernetes service from Google Cloud that implements the entire Kubernetes API. It makes sure that the information is found via secure communication channels by adhering to all Twitter services’ protocols, policies, and security standards. The team is enabled to scale the platform in response to the workload by using an automated mechanism.
Twitter Puppet: The configuration management system used by Twitter is Puppet, which creates a new image using Twitter templates with a preset setup.
Google Cloud load balancing: It is in charge of routing requests to the servers available in GKE. A new server is installed if the load grows too great, and the load balancer will be in charge of routing traffic to it.
SSL certificate TLS certificates are used to secure TLS server connections. They’re used to get certificates from a publicly trusted certificate authority (CA) suitable for web servers. As their applications contain sensitive information, they plan to use an SSL certificate to ensure a safe connection.
Data QnA API: Natural language processing is supported by Google Cloud’s Data QnA APIs. Data QnA turns customers’ inquiries, which are posed in natural language, into a SQL query that can be used to retrieve answers in the dataset.
BigQuery API: The BigQuery APIs on Google Cloud construct a job that executes queries generated by the Data QnA APIs. The query results are rendered in a data table or visualization once it has been completed successfully.
The team used Twitter Feather Components Library to create the Navigation Bar, Buttons, Charts, Tables, Progress Spinners, and CSS style sheets and React. This covers GCP services that transmit a variety of Remote Procedure Calls (RPCs), such as:
- Creating potential questions
- Creating SQL queries based on the questions that have been asked
- Creating jobs for BigQuery to conduct SQL queries
Both the web app and the Slack chatbot use common services to make code maintenance easier. It also enables a smooth flow between the two surfaces. The following are some of the most common services:
- Google OAuth for authentication and authorization ensures that consumers may only ask queries about datasets they have access to. A service account authentication is also set for performing BigQuery backend processes.
- The Data QnA Question Service Client is created and configured by the Data QnA service. It asks the Data QnA question and interprets the endpoint with numerous interpretation handlers. It then inquires about the user’s preferred interpretation, answers the question, formats it, and sends it to the user.
- The BigQuery service is used to construct a job that will run SQL queries and produce a structured answer.
- Caching service is the caching layer for question-answer. It uses the cache to serve commonly asked questions.
Reference: https://blog.twitter.com/engineering/en_us/topics/insights/2022/next-generation-data-insights-using-natural-language-queries
Suggested
Credit: Source link
Comments are closed.