Uber Explores Deep Learning To Develop ‘DeepETA’: A Low-Latency Deep Neural Network Architecture For ETA Prediction

Web mapping services like Google Maps are excellent tools to dynamically navigate portions of the Earth. They are used daily by businesses that rely on accurate mapping features (such as food delivery services to provide accurate and optimized delivery time estimates) and everyday consumers looking for (best) routes between waypoints.
Therefore, predicting the expected arrival time (ETA) is vital to allow traffic participants to make better decisions, potentially avoiding congested areas and reducing the overall time spent stuck in traffic.
ETAs are typically computed using traditional routing algorithms, which divide the road network into small road segments represented by weighted edges in a graph. To calculate the ETA, they use shortest-path algorithms to find the best path through the graph and then add the weights. However, a road graph is merely a model that cannot accurately depict ground conditions. Furthermore, these models cannot predict which route a given rider should take to reach their destination.
Uber refined ETA predictions using gradient-boosted decision tree ensembles. With each release, the ETA model and its training dataset grew. To enhance their current model’s performance by improving its latency, accuracy, and generality, Uber AI collaborated with Uber Maps to develop DeepETA, a low-latency deep neural network architecture for worldwide ETA prediction. The team used the Canvas framework from Uber’s machine learning platform, Michelangelo, to train and deploy the model. They tested the model with seven neural network architectures: MLP, NODE, TabNet, Sparsely Gated Mixture-of-Experts, HyperNetworks, Transformer, and Linear Transformer. Automated retraining operations are set up regularly to retrain and evaluate the model.
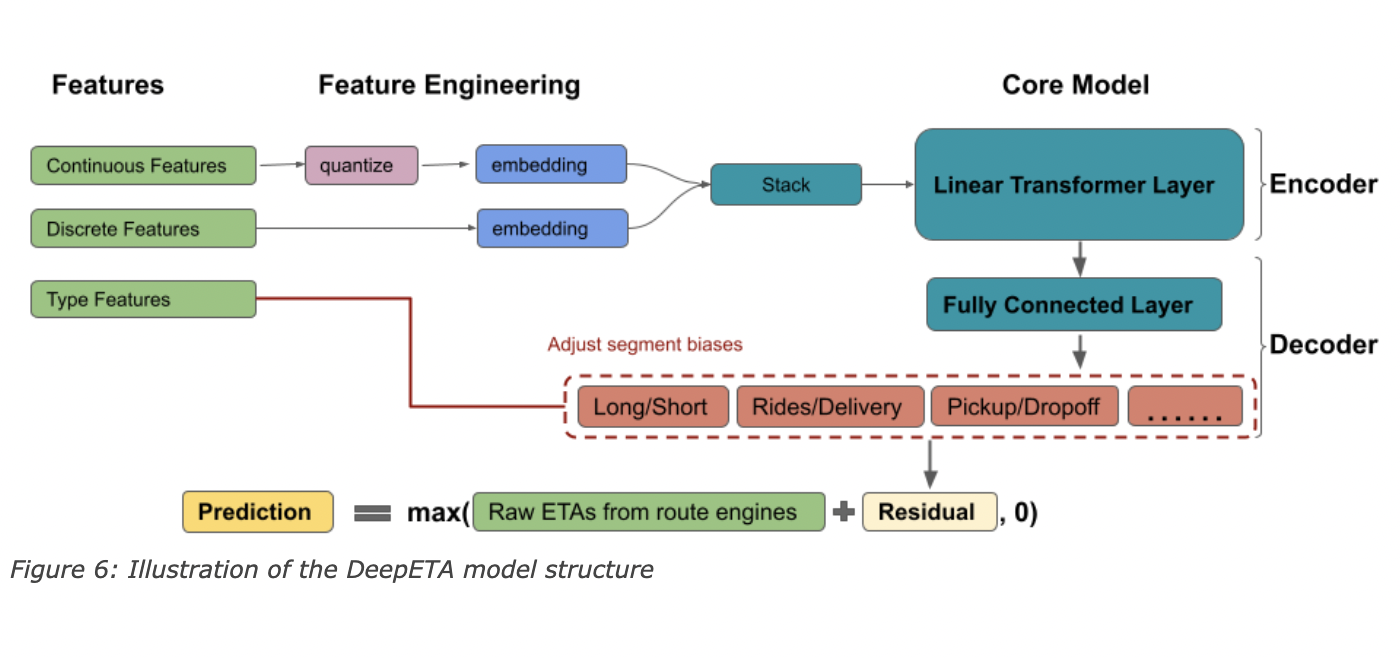
This new physical model is a routing engine that predicts an ETA as a sum of segment-wise traversal times along the optimum path between two sites. For this, it uses map data and real-time traffic observations. The residual between the routing engine ETA and real-world, observed outcomes is then predicted using machine learning. The researchers call this hybrid technique ETA post-processing. In practice, modifying the post-processing model rather than refactoring the routing engine makes it easier to integrate new data sources and adapt rapidly changing business requirements.
A post-processing ML model considers spatial and temporal features (for example, the origin, destination, time of the request), real-time traffic information, and the nature of the request (such as a delivery drop-off or rideshare pick-up). This model must be quick to avoid adding unnecessary latency to an ETA request. In addition, it must also increase ETA accuracy as assessed by mean absolute error (MAE) across different segments of data. At Uber, this post-processing model has the greatest QPS (queries per second).
Improving Accuracy By Using Encoder with Self-Attention
Self-attention is a sequence-to-sequence procedure that takes a vector sequence and generates a reweighted vector sequence. DeepETA does not use positional encoding because the sequence of the features here is irrelevant. The self-attention layer, for example, scales the value of elements based on the time of day, origin and destination, traffic conditions, and so on during a route from origin A to destination B.
Before embedding, the DeepETA model buckets all continuous features and then embeds all categorical features. The results show that continuous bucketing features resulted in better accuracy than utilizing continuous features directly.
Improving Accuracy By Feature Encoding
The origin and destination of a trip are given to post-processing models as latitudes and longitudes. DeepETA encodes these start and end points differently than other continuous features since they are critical for forecasting ETAs. The distribution of location data is relatively uneven globally, and it comprises information at several geographical resolutions. As a result, they quantized locations using latitude and longitude to create several resolution grids. The number of different grid cells grows exponentially as the resolution improves, whereas each grid cell’s average amount of data drops proportionately.
The team experimented with three methods for mapping these grids to embeddings: exact indexing, multiple feature hashing, and feature hashing. The experiments revealed that the accuracy remained the same or slightly worse depending on the grid resolution. Compared to exact indexing, multiple feature hashing provided the best accuracy and latency while saving space.

Minimizing Latency With DeepETA
According to the team, although the transformer-based encoder had the highest accuracy, it was too sluggish to meet the latency requirements to serve in real-time. This is because of its quadratic complexity when computing a K*K attention matrix from K inputs. Therefore, the researchers decided to use a linear transformer to avoid calculating the attention matrix using the kernel trick.
Furthermore, the team used feature sparsity to speed up DeepETA. As most of the parameters are found in embedded lookup tables, they tried to avoid assessing any unnecessary embedding table parameters by discretizing the inputs and translating them to embeddings.
Generalizing The Model
Finally, the team wanted to design their model to generalize its use for all of Uber’s business lines worldwide. The decoder employed in their model is a fully connected neural network with a segment bias adjustment layer. The absolute error distribution differs significantly across various parameters such as delivery trips and riding trips, long and short travels, pick-up and drop-off trips, and worldwide mega-regions. By using bias adjustment layers to change the raw prediction for each segment, the MAE can be improved by accounting for their natural variances. This method outperforms by merely including segment information in the model.
Further, different forms of ETA point estimations are required for different business use cases and different proportions of outliers in the data. DeepETA employs an asymmetric Huber loss, a parameterized loss function that is robust to outliers. It can also support a variety of regularly used point estimates to accommodate this diversity.
The team believes that they can further improve the model’s accuracy by examining every aspect of the modeling process. In addition, they plan to investigate enhancements such as continuous, incremental training to train ETAs on more recent data.
Reference: https://eng.uber.com/deepeta-how-uber-predicts-arrival-times/
Suggested

Credit: Source link
Comments are closed.