UC Berkeley Researchers Introduce ‘Autocast’, A New Dataset For Measuring Machine Learning ML Models’ Forecasting Ability
In this research article, the researchers from UC Berkeley demonstrated that extracting from a sizable news corpus may effectively train language models on prior predicting problems.
Forecasting is a process that makes educated projections using previous data as inputs when identifying the direction of future trends. Forecasting future events in the real world, including pandemics, the economy, or the environment, is still complex but essential. Because dynamic information processing is a crucial component of efficient forecasting, AI researchers are considering using strong large-scale language models to automate these processes.
Researchers present a dataset with tens of thousands of forecasting questions and a date-based news corpus in the new paper Forecasting Future World Events with Neural Networks. They also curate IntervalQA, a dataset with numerical questions and metrics for calibration.
Team contributions are-
- They provide Autocast, a dataset for forecasting that includes a range of subjects and several time horizons.
- A sizable news corpus categorized by date makes up a portion of their dataset, enabling us to thoroughly assess model performance on historical projections.
- The team of researchers demonstrates that existing language models struggle with predicting, with accuracy and calibration much below a solid human baseline.
The team assembled 6,707 true/false, multiple-choice, or quantity/date questions with a wide range of topics (politics, economics, and science) of general public interest for their Autocast dataset by collecting forecasting questions from three public forecasting competitions: Metaculus, Good Judgment Open, and CSET Foretell.
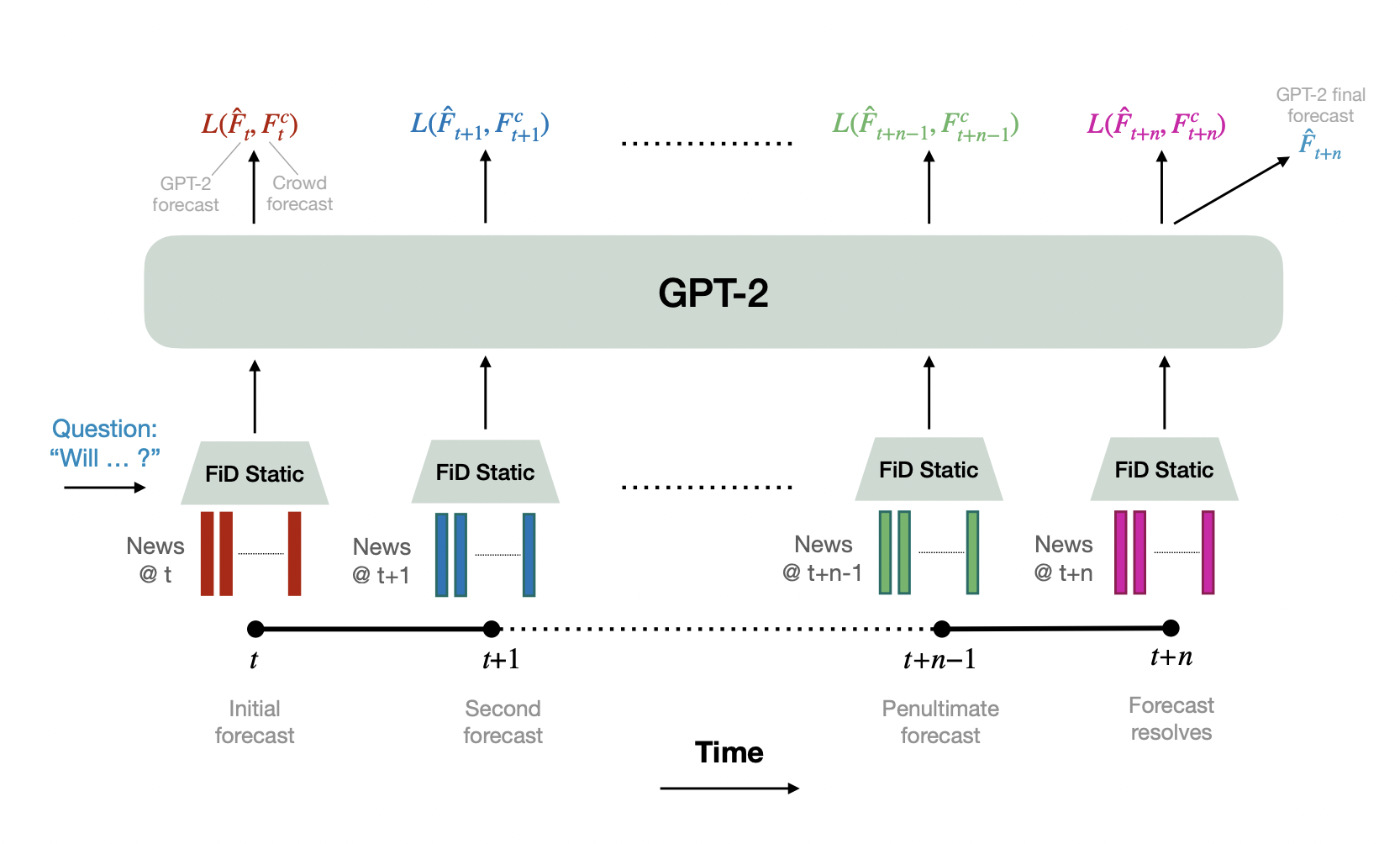
The text-to-text framework T5 (Raffel et al., 2020) and the QA model UnifiedQA-v2 (Khashabi et al., 2022) were first evaluated without retrieval, then retrieval-based approaches were assessed by the researcher to see if they might improve the model performance by picking relevant articles from the dataset with Autocast.

The team encoded articles obtained by the lexical search technique BM25 with cross-encoder reranking using a Fusion-in-Decoder model for retrieval. The frozen fine-tuned FiD model embeds every day’s top news story between a particular query’s open and closing dates and feeds these created embeddings to an autoregressive big language model like GPT-2.
The results reveal that retrieval-based techniques using Autocast significantly outperform UnifiedQA-v2 and T5, and their efficiency increases as the number of parameters rise. This suggests that more extensive models can extract pertinent information from retrieved articles better than smaller models.
Although the findings are still below the baseline of a human expert, performance can be improved by expanding the model and strengthening information retrieval. The team is specific that Autocast’s innovative method for allowing large language models to predict future global events will have significant practical advantages in various applications.
You can access the code and Autocast dataset on the project’s GitHub page. On arXiv, there is a study titled Forecasting Future World Events using Neural Networks.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Forecasting Future World Events with Neural Networks'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.