UC Berkeley Researchers Introduce Dynalang: An AI Agent that Learns a Multimodal World Model to Predict Future Text and Image Representations and Learns to Act from Imagined Model Rollouts
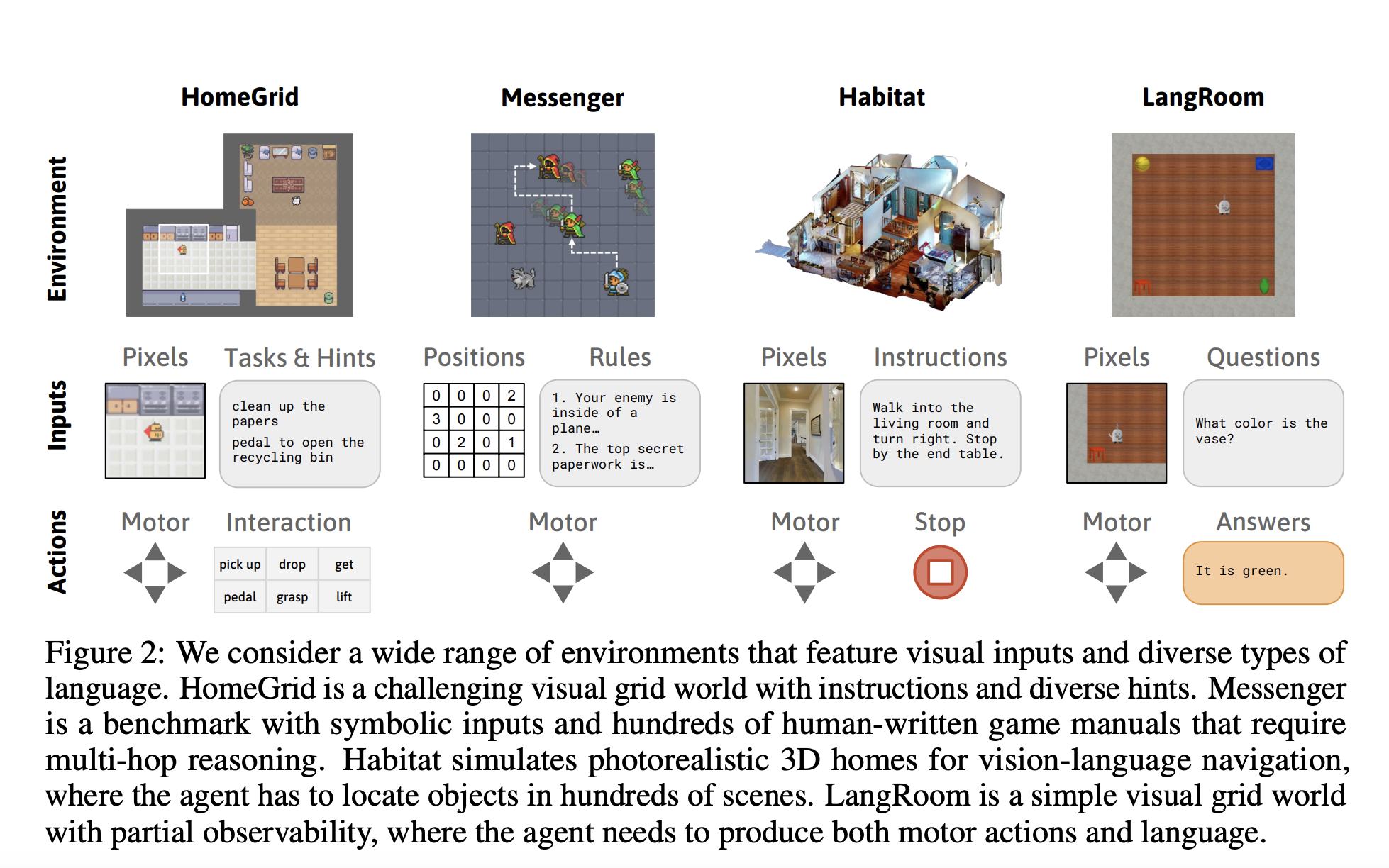
Creating bots that can communicate organically with people in the real world using language has long been an aim of artificial intelligence. Present-day embodied agents can execute straightforward, low-level commands like “get the blue block” or “go past the lift and turn right.” However, interactive agents need to be able to comprehend the full range of ways people use the language outside of the “here and now,” including knowledge transmission (for example, “the top left button turns off the TV”), situational information (for example, “we’re out of milk”), and coordination (for example, “I already vacuumed the living room”).
Most of what kids read in texts or hear from others conveys information about the world, either how it functions or as it is right now. How might they make it possible for agents to speak in other languages? Reinforcement learning (RL) is a technique for teaching language-conditioned agents to solve problems. However, most language-conditioned RL techniques now in use are trained to produce actions from task-specific instructions, for example, by taking a goal description like “pick up the blue block” as input and making a series of motor commands. Directly mapping language to the best course of action offers a difficult learning challenge when considering the variety of roles natural language fulfills in the actual world.
If the work at hand is cleaning up, the agent should answer by going on to the next cleaning step, but if it is serving supper, the agent should collect the bowls. Take the case of “I put the bowls away” as an example. Language only has a weak correlation with the best course of action for the agent when it does not discuss the job. As a result, task-reward-only mapping of language to activities could be a better learning signal for learning to employ a variety of language inputs to complete tasks. Instead, they suggest that a unifying function of language for agents is to aid in future prediction. The phrase “I put the bowls away” enables agents to predict future observations more accurately (i.e., if it opens the cabinet, it will see the bowls within).
In this sense, much of the language kids come across might be rooted in visual experience. Agents can predict environmental changes using prior information, such as “wrenches can be used to tighten nuts.” Agents might anticipate observations by saying, “the package is outside.” This paradigm also combines common instruction-following practices under predictive terms: instructions aid agents in expecting their rewards. They contend that forecasting future representations offers agents a rich learning signal that will help them comprehend language and how it interacts with the outside world, much to how next-token prediction enables language models to construct internal representations of world knowledge.
Researchers from UC Berkeley introduce Dynalang, an agent that acquires a language and visual model of the world through online experience and utilizes the model to understand how to behave. Dynalang separates learning to behave using that model (reinforcement learning with task incentives) from learning to model the world with language (supervised learning with prediction targets). The world model receives visual and textual inputs as observation modalities, which are compressed into a latent space. With data gathered online as the agent interacts with its surroundings, it trains the world model to anticipate future latent representations. Using the latent representation of the world model as input, they train the policy to adopt decisions that maximize task reward.
Since world modeling is distinct from action, Dynalang may be pretrained on single modalities (text-only or video-only data) without activities or task rewards. Additionally, the framework for language production may be unified: an agent’s perception can influence its language model (i.e., its predictions about future tokens), allowing it to communicate about the environment by producing language in the action space. They test Dynalang on a wide range of domains with various linguistic contexts. Dynalang learns to employ linguistic cues regarding future observations, environment dynamics, and corrections to carry out chores more quickly in a multitask house cleaning setting. On the Messenger benchmark, Dynalang outperforms task-specific architectures by reading game manuals to match the most difficult stage of the game. They show that Dynalang can pick up instructions in visually and linguistically complicated areas in vision-language navigation. These contributions demonstrate that Dynalang learns to comprehend many forms of language to accomplish various tasks, frequently beating state-of-the-art RL algorithms and task-specific architectures.
These are the contributions they made:
• They suggest Dynalang, an agent that uses future prediction to connect language to visual experience.
• They show that Dynalang outperforms state-of-the-art RL algorithms and task-specific designs by learning to comprehend various types of language to tackle a wide variety of tasks.
• They demonstrate that the Dynalang formulation opens up new possibilities, including the ability to combine language creation with text-only pretraining without actions or task incentives in a single model.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.