UC Berkeley Researchers Introduce Koala: A New AI Chatbot from Fine-Tuned on Dialogue Close to ChatGPT Quality
Systems like ChatGPT, Bard, Bing Chat, and Claude can answer various user queries, provide sample code, and even produce poetry thanks to large language models (LLMs).
The most powerful LLMs typically demand extensive computing resources for training and thus necessitate the usage of big, private datasets. The open-source models probably won’t be as powerful as the closed-source ones, but with the right training data, they might be able to come close. Smaller open-source models can be vastly improved with the correct data, as evidenced by projects like Stanford’s Alpaca, which fine-tunes LLaMA using OpenAI’s GPT model data.
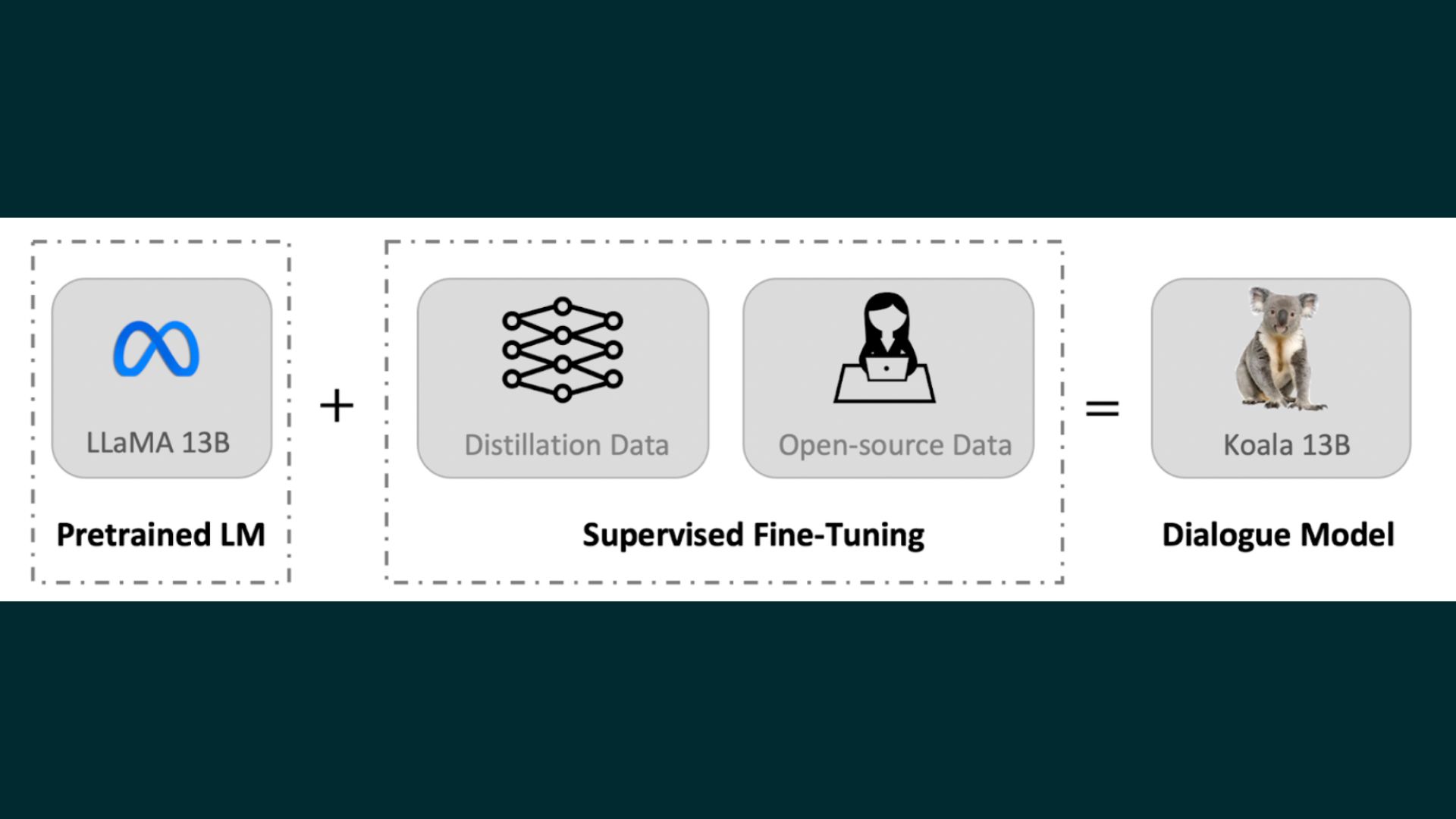
A recent UC Berkely AI research presents a novel model called Koala. Koala is trained using data that includes interaction with capable closed-source models like ChatGPT. This data is available on the web and used in training. Using online scraped dialogue data, question-answering datasets, and human feedback datasets. The researchers fine-tune a LLaMA base model. The datasets include high-quality responses to user inquiries from existing big language models.
Training data curation is a major roadblock in developing conversational AI. Many existing chat models use custom datasets that require extensive human annotation. Koala’s training set was hand-picked by scouring the internet and public sources for conversational data. Conversations between users and large language models (like ChatGPT) are included in this data set.
Instead of trying to get as much data as possible from the web, the team chose quality over quantity. Question-answering, human feedback (evaluated both favorably and negatively), and conversations with preexisting language models were all conducted using publicly available datasets.
The team ran trials to compare two models, one that relies exclusively on distillation data (Koala-Distill) and another that uses all available data (Koala-All), including distillation data and open-source data. They examine how well these models function and assess how much of an impact distillation and public datasets have on final results. They put Koala-All through its paces against Koala-Distill, Alpaca, and ChatGPT in a human evaluation.
The Alpaca model’s training data is found in the Alpaca test set, which comprises representative user prompts taken from the self-instruct dataset. They also provide their (Koala) test set, comprised of 180 actual user queries submitted online, to give a second, more realistic evaluation process. These questions come from a wide range of users and are written in a natural, conversational tone; they are more indicative of how people use chat-based services. Using these two sets of evaluation data, the researchers asked roughly one hundred evaluators to compare the quality of model outputs on these hidden sets of tasks using the Amazon Mechanical Turk platform.
Koala-All performed just as well as Alpaca did on the Alpaca test set. On the other hand, Koala-All was scored as better than Alpaca in nearly half of the cases and either exceeded or tied to Alpaca in 70% of the cases, based on the proposed test set, which comprises genuine customer questions.
The team mentioned that due to the fine-tuning dialogue, Koala could hallucinate and make non-factual comments with a highly confident tone. If this is the case, then future research needs to investigate the potential drawback of smaller models inheriting the confident style of bigger language models before inheriting the same level of factuality.
This article is based on the BAIR Blog on Koala and its Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.