UC Berkeley Researchers Introduce Video Prediction Rewards (VIPER): An Algorithm That Leverages Pretrained Video Prediction Models As Action-Free Reward Signals For Reinforcement Learning
Designing a reward function by hand is time-consuming and can result in unintended consequences. This is a major roadblock in developing reinforcement learning (RL)-based generic decision-making agents.
Previous video-based learning methods have rewarded agents whose current observations are most like those of experts. They cannot capture meaningful activities throughout time since rewards are conditional solely on the current observation. And generalization is hindered by the adversarial training techniques that lead to mode collapse.
U.C. Berkeley researchers have developed a novel method for extracting incentives from video prediction models called Video Prediction incentives for reinforcement learning (VIPER). VIPER can learn reward functions from raw films and generalize to untrained domains.
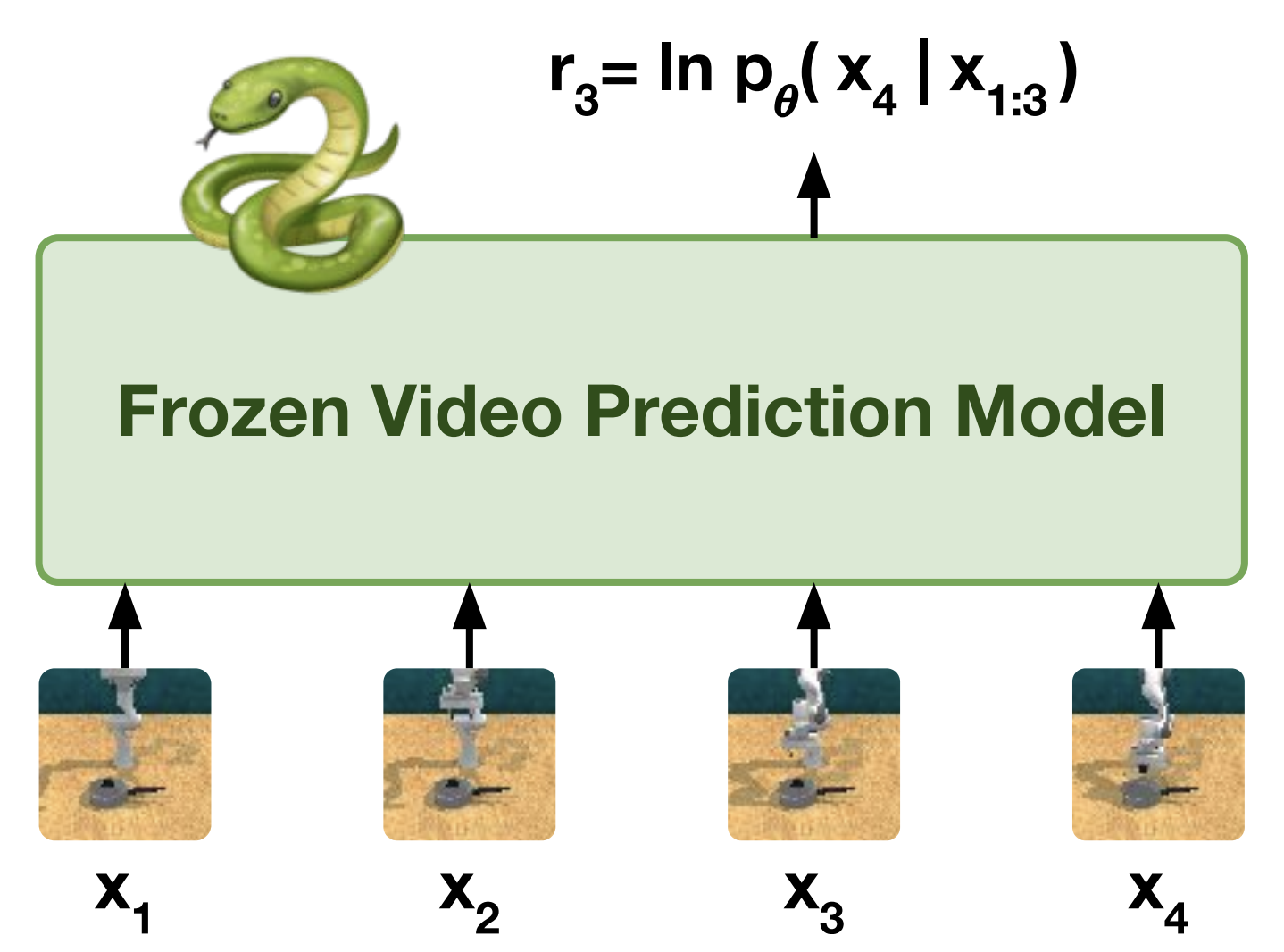
First, VIPER uses expert-generated movies to train a prediction model. The video prediction model is then used to train an agent in reinforcement learning to optimize the log-likelihood of agent trajectories. The distribution of the agent’s trajectories must be minimized to match the distribution of the video model. Using the video model’s likelihoods as a reward signal directly, the agent may be trained to follow a trajectory distribution similar to the video model’s. Unlike rewards at the observational level, those provided by video models quantify the temporal consistency of behavior. It also allows quicker training timeframes and greater interactions with the environment because evaluating likelihoods is much faster than doing video model rollouts.
Across 15 DMC tasks, 6 RLBench tasks, and 7 Atari tasks, the team conducts a thorough study and demonstrates that VIPER can achieve expert-level control without using task rewards. According to the findings, VIPER-trained RL agents beat adversarial imitation learning across the board. Since VIPER is integrated into the setting, it does not care which RL agent is used. Video models are already generalizable to arm/task combinations not encountered during training, even in the small dataset regime.
The researchers think using big, pre-trained conditional video models will make more flexible reward functions possible. With the help of recent breakthroughs in generative modeling, they believe their work provides the community with a foundation for scalable reward specification from unlabeled films.
Check out the Paper and Project. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.