UC Berkeley Researchers Propose a Novel Technique Called Chain of Hindsight (CoH) that can Enable LLMs to Learn from Any Form of Feedback Improving Model Performance
Over the past few years, large-scale neural networks have drawn considerable attention from researchers. This is mostly due to their outstanding performance in various tasks, including natural language understanding, solving challenging mathematical equations, and even protein structure prediction. Nonetheless, in order to ensure that these models make constructive contributions to society, it is crucial that they align with human values and considers human preferences. The use of human feedback is one of the most essential aspects in accomplishing this because it enables humans to assess the performance of such models based on a wide range of metrics such as accuracy, fairness, bias, etc., and offers insights into how these models can be improved to produce more ethical outputs. In order to improve the efficiency of incorporating user feedback, researchers have been experimenting with several approaches for human-in-the-loop systems during the past few years. Results show that ChatGPT and InstructGPT have demonstrated amazing results as a result of using human feedback to learn.
These performance gains in language modeling have been largely attributed to a strategy that relies on supervised finetuning (SFT) and Reinforcement Learning with Human Feedback (RLHF) approaches. Although these strategies have significantly contributed to achieving promising outcomes regarding language model performance, they have their own drawbacks. SFT mainly relies on human annotation, rendering these models both difficult to use and inefficient in data utilization. On the other hand, since reinforcement learning works on a reward function basis, it is very challenging to optimize these models.
To counter these issues, researchers from the University of California, Berkeley, developed a novel technique that turns all feedback into sentences and uses them to finetune the model to understand the feedback. This technique, known as the Chain of Hindsight (CoH), is largely inspired by how humans process substantial feedback supplied in the form of languages. The goal of the researchers when designing the technique was to combine the strengths of SFT and RLHF while avoiding using reinforcement learning to utilize all feedback fully. Their current approach uses language’s ability to understand and learn from feedback, ultimately improving the models’ capacity to carry out a wide range of tasks more precisely and effectively.
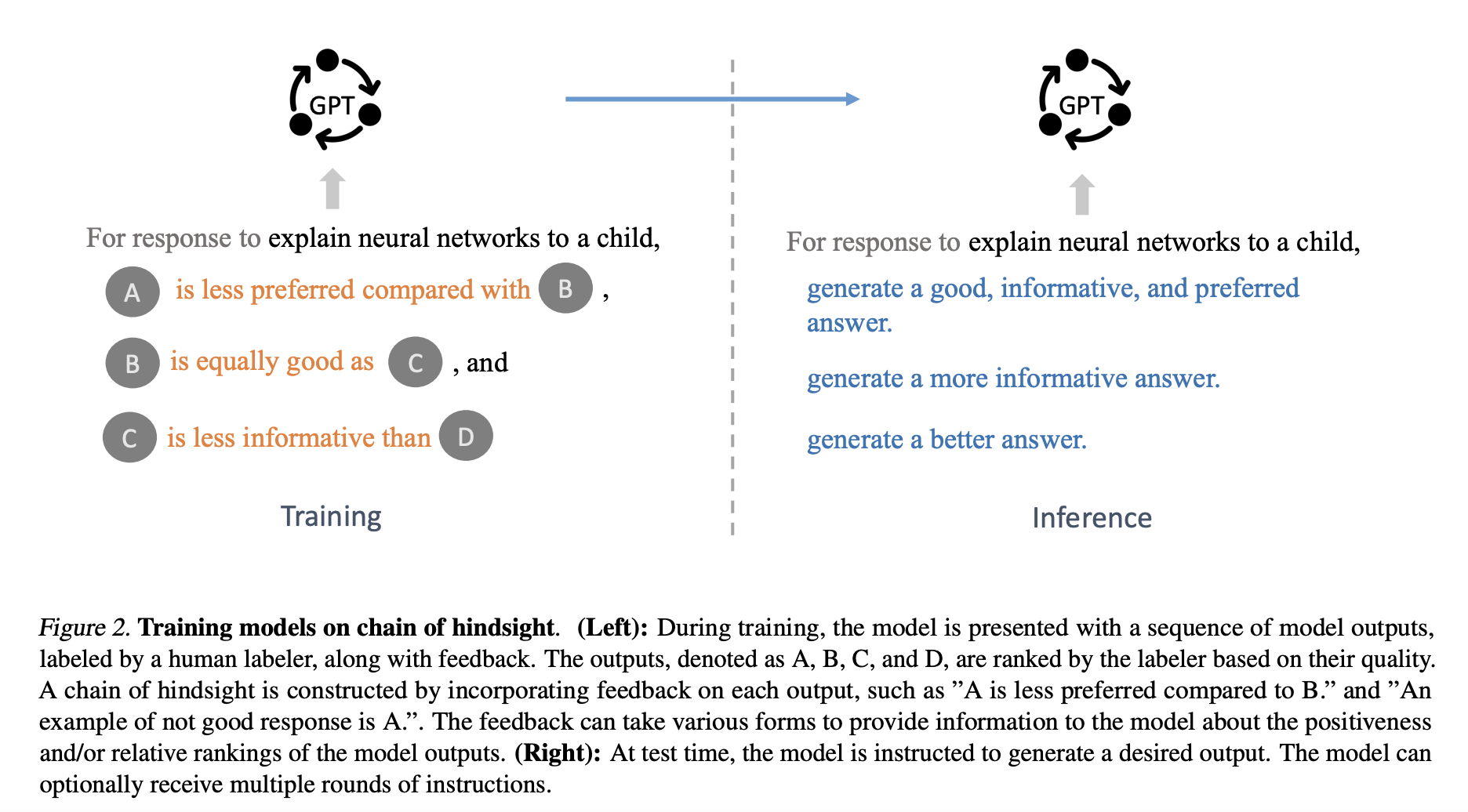
The researchers made use of the fact that humans learn well from rich feedback in the form of language. Given the impressive capabilities of pre-trained language models to learn effectively in context, researchers wondered about the possibility of turning all feedback into a sentence and training the models to follow the feedback. In greater detail, the researchers suggested finetuning the model to predict results while relying on one or more sorted results and their feedback in the form of comparisons. CoH randomly selects one or more model outputs during training and utilizes them to construct a sentence that includes both positive and negative feedback in the form of comparison. For instance, two example sentences can be “The following is a bad summary” and “The following summary is better.” The model uses positive feedback at inference time to generate the desired outputs.
The CoH approach allows models to learn from both positive and negative feedback, allowing the identification and correction of negative attributes or errors. The strategy has a number of additional benefits as well. They include a more organic style of feedback and a system for training. Also, the CoH technique greatly outperforms earlier approaches in correlating language models with human preferences, according to numerous experimental assessments carried out by researchers. The method is preferred in human evaluations and performed remarkably well on summarization and discussion tasks. The UC Berkeley team strongly believes that CoH has enormous potential for use in the future with various other types of feedback, such as automatic and numeric feedback.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.