UC Berkeley Researchers Unveil LoRA+: A Breakthrough in Machine Learning Model Finetuning with Optimized Learning Rates for Superior Efficiency and Performance
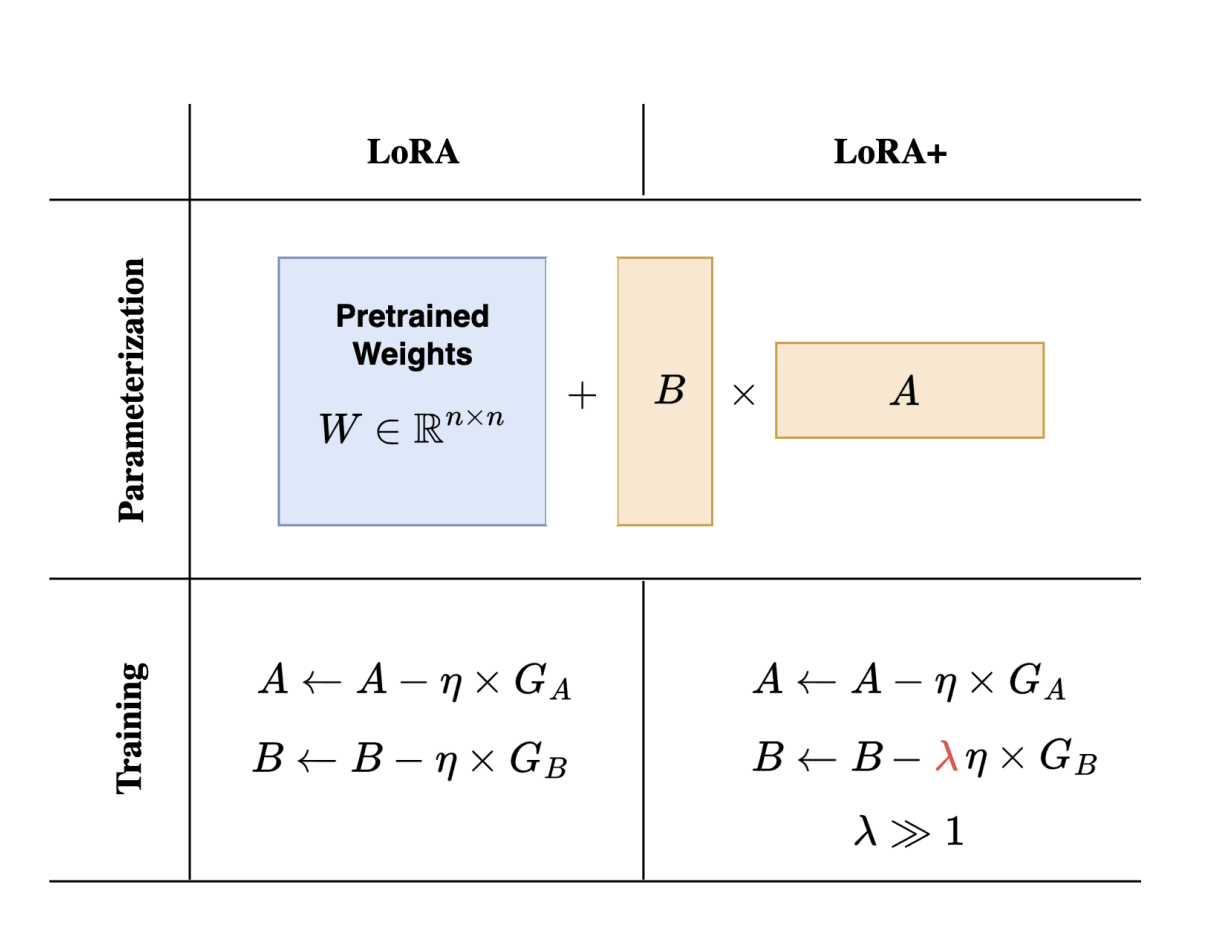
In deep learning, the quest for efficiency has led to a paradigm shift in how we finetune large-scale models. The research spearheaded by Soufiane Hayou, Nikhil Ghosh, and Bin Yu from the University of California, Berkeley, introduces a significant enhancement to the Low-Rank Adaptation (LoRA) method, termed LoRA+. This novel approach is designed to optimize the finetuning process of models characterized by their vast number of parameters, which often run into the tens or hundreds of billions.
Adapting massive models to specific tasks has been challenging due to computational burden. Researchers have navigated this by freezing the original weights of the model and adjusting only a small subset of parameters through methods like prompt tuning, adapters, and LoRA. The last, in particular, involves training a low-rank matrix added to the pretrained weights, thus reducing the number of parameters that need adjustment.
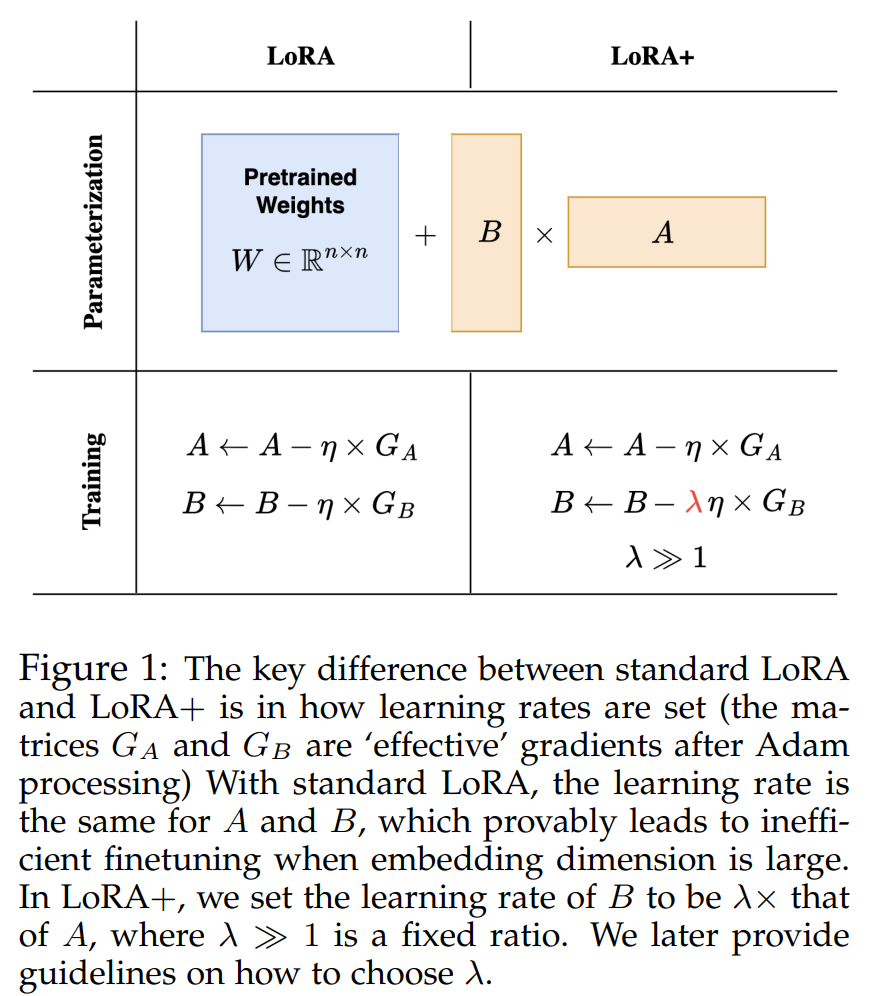
As identified by the UC Berkeley team, the crux of the inefficiency in the existing LoRA method lies in the uniform learning rate applied to the adapter matrices A and B. Given the vastness of the model width, more than a one-size-fits-all approach to the learning rate is needed, leading to suboptimal feature learning. The introduction of LoRA+ addresses this by implementing differentiated learning rates for matrices A and B, optimized through a fixed ratio. This nuanced approach ensures a tailored learning rate that better suits the scale and dynamics of large models.
The team’s rigorous experimentation provides solid backing for the superiority of LoRA+ over the traditional LoRA method. Through comprehensive testing across various benchmarks, including those involving Roberta-base and GPT-2 models, LoRA+ consistently showcased enhanced performance and finetuning speed. Notably, the method achieved performance improvements ranging from 1% to 2% and a finetuning speedup of up to approximately 2X while maintaining the same computational costs. Such empirical evidence underscores the potential of LoRA+ to revolutionize the finetuning process for large models.
Specifically, when applied to the Roberta-base model across different tasks, LoRA+ achieved remarkable test accuracies, with a notable increase in ‘harder’ tasks such as MNLI and QQP compared to easier ones like SST2 and QNLI. This variation in performance amplifies the importance of efficient feature learning, particularly in complex tasks where the pretrained model’s alignment with the finetuning task is less straightforward. Furthermore, the Llama-7b model’s adaptation using LoRA+ on the MNLI dataset and the Flan-v2 dataset solidified the method’s efficacy, showcasing significant performance gains.
The methodology behind LoRA+, involving setting different learning rates for LoRA adapter matrices with a fixed ratio, is not just a technical tweak but a strategic overhaul of the finetuning process. This approach allows for a more refined adaptation of the model to the specificities of the task at hand, enabling a level of customization previously unattainable with uniform learning rate adjustments.
In sum, the introduction of LoRA+ by the research team from UC Berkeley marks a pivotal advancement in deep learning. By addressing the inefficiencies in the LoRA method through an innovative adjustment of learning rates, LoRA+ paves the way for more effective and efficient finetuning large-scale models. This breakthrough enhances the performance and speed of model adaptation and broadens the horizon for future research and applications in optimizing the finetuning processes of neural networks. The findings from this study, substantiated by rigorous empirical evidence, invite a reevaluation of existing practices and offer a promising avenue for leveraging the full potential of large models in various applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.