UC San Diego and Meta AI Researchers Introduce MonoNeRF: An Autoencoder Architecture that Disentangles Video into Camera Motion and Depth Map via the Camera Encoder and the Depth Encoder
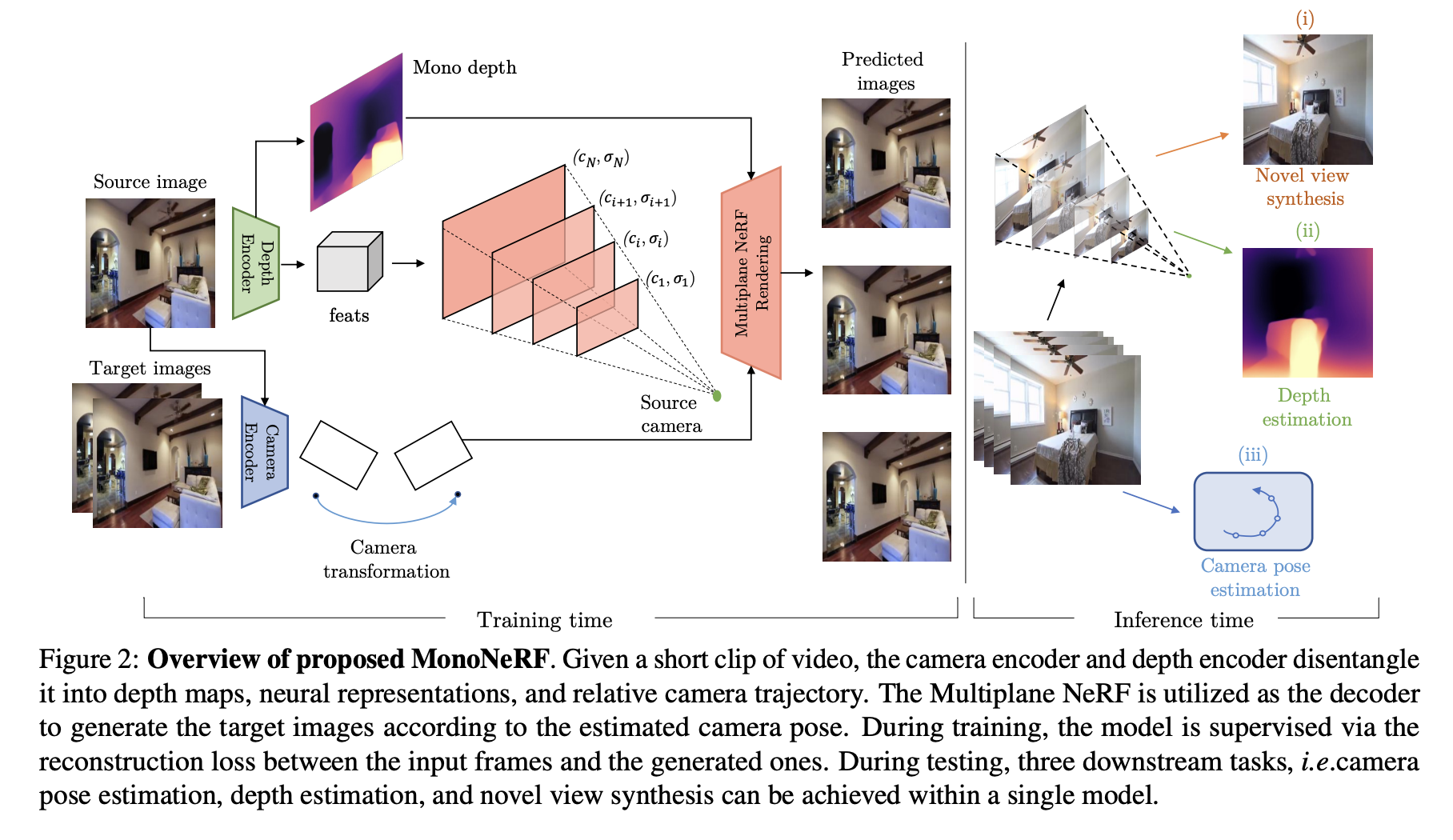
Researchers from UC San Diego and Meta AI have introduced MonoNeRF. This novel approach enables the learning of generalizable Neural Radiance Fields (NeRF) from monocular videos without the dependence on ground-truth camera poses.
The work highlights that NeRF has exhibited promising results in various applications, including view synthesis, scene and object reconstruction, semantic understanding, and robotics. However, constructing NeRF requires precise camera pose annotations and is restricted to a single scene, resulting in time-consuming training and limited applicability to large-scale unconstrained videos.
In response to these challenges, recent research efforts have focused on learning generalizable NeRF by training on datasets comprising multiple scenes and subsequently fine-tuning on individual scenes. This strategy allows for reconstruction and view synthesis with fewer view inputs, but it still necessitates camera pose information during training. While some researchers have attempted to train NeRF without camera poses, these approaches remain scene-specific and struggle to generalize across different scenes due to the complexities of self-supervised calibrations.
MonoNeRF overcomes these limitations by training on monocular videos capturing camera movements in static scenes, effectively eliminating the need for ground-truth camera poses. The researchers make a critical observation that real-world videos often exhibit slow camera changes rather than diverse viewpoints, and they leverage this temporal continuity within their proposed framework. The method involves an Autoencoder-based model trained on a large-scale real-world video dataset. Specifically, a depth encoder estimates monocular depth for each frame, while a camera pose encoder determines the relative camera pose between consecutive frames. These disentangled representations are then utilized to construct a NeRF representation for each input frame, which is subsequently rendered to decode another input frame based on the estimated camera pose.
The model is trained using a reconstruction loss to ensure consistency between the rendered and input frames. However, relying solely on a reconstruction loss may lead to a trivial solution, as the estimated monocular depth, camera pose, and NeRF representation might not be on the same scale. The researchers propose a novel scale calibration method to address this challenge of aligning the three representations during training. The key advantages of their proposed framework are twofold: it removes the need for 3D camera pose annotations and exhibits effective generalization on a large-scale video dataset, resulting in improved transferability.
At test time, the learned representations can be applied to various downstream tasks, such as monocular depth estimation from a single RGB image, camera pose estimation, and single-image novel view synthesis. The researchers conduct experiments primarily on indoor scenes and demonstrate the effectiveness of their approach. Their method significantly improves self-supervised depth estimation on the Scannet test set and shows superior generalization to NYU Depth V2. Moreover, MonoNeRF consistently outperforms previous approaches using the RealEstate10K dataset in camera pose estimation. For novel view synthesis, the proposed MonoNeRF approach surpasses methods that learn without camera ground truth and outperforms recent approaches relying on ground-truth cameras.
In conclusion, the researchers present MonoNeRF as a novel and practical solution for learning generalizable NeRF from monocular videos without needing a ground-truth camera pose. Their method addresses limitations in previous approaches and demonstrates superior performance across various tasks related to depth estimation, camera pose estimation, and novel view synthesis, particularly on large-scale datasets.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.