UNC School of Medicine Researchers Identify Long COVID Patients In The USA Using Machine Learning
Clinical scientists have explored de-identified electronic health record data in the National COVID Cohort Collaborative(N3C), a National Institutes of Health-funded national clinical database, using machine learning models to help decipher characteristics of individuals with long COVID and attributes that may help identify such patients using information from medical records.
The discoveries published in The Lancet Digital Health have the potential to enhance clinical research on extended COVID and inspire a more consistent COVID treatment regimen.
The author Emily R. Pfaff, Ph.D., an assistant professor in the UNC School of Medicine’s Division of Endocrinology and Metabolism, said that characterizing, diagnosing, treating, and caring for long COVID patients has turned out to be difficult owing to the list of characteristic symptoms constantly evolving over time. They needed to better grasp the intricacies of long COVID, and it made sense to use current data analysis methods and a unique, extensive data resource like N3C, which represents many of the properties of long COVID.
The N3C data enclave, funded by the National Institutes of Health’s National Center for Advancing Translational Sciences (NCATS), already has information on more than 13 million people from 72 locations, including approximately 5 million COVID-19-positive patients. This resource does rapid research on developing topics involving COVID-19 vaccines, treatments, risks, and possible health outcomes.
This new study is a segment of the National Institutes of Health’s Researching COVID to Enhance Recovery (RECOVER) initiative, which has been recruiting thousands of people across the country to answer key research questions about the syndrome to accurately identify who has long COVID, risk factors for long COVID, and possible interventions and treatments.
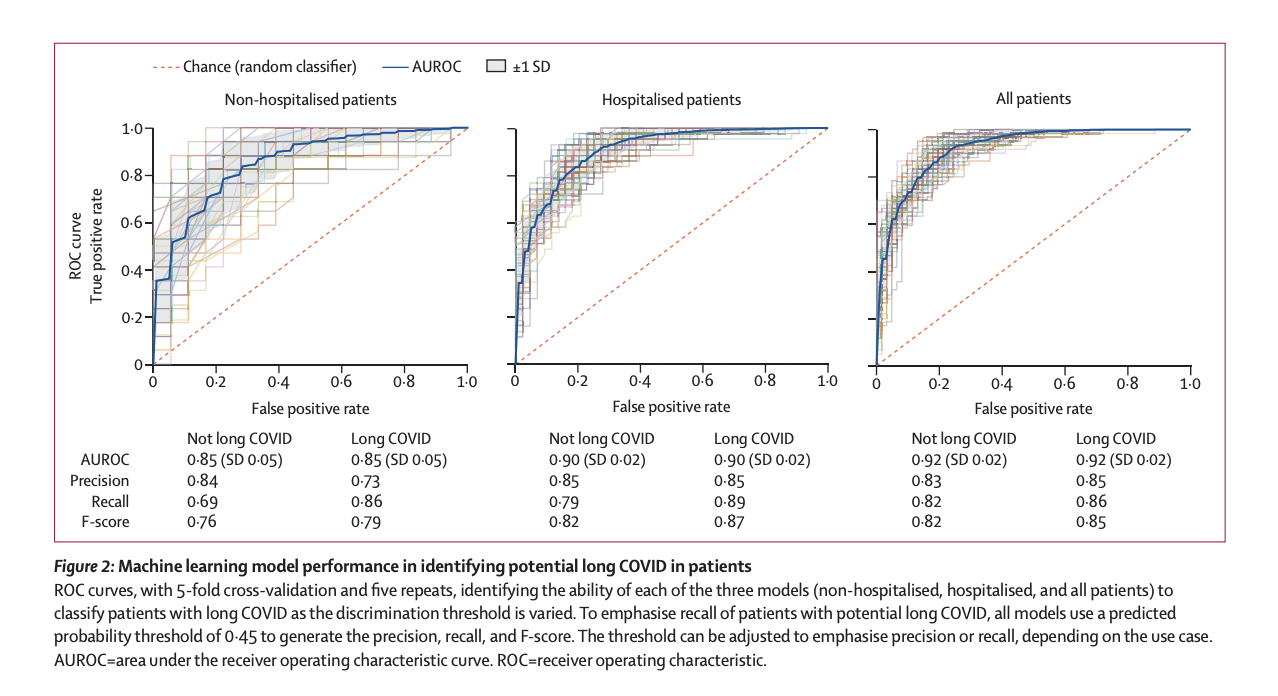
For a large pool of adult COVID-19 participants, researchers looked at demographics, healthcare utilization, diagnoses, and medicines. They trained and tested three machine learning models on nearly 600 long COVID patients from three long COVID specialty clinics, intending to identify potential COVID patients in three groups: all COVID-19 patients and COVID-19 patients who were hospitalized, and COVID-19 patients who were not hospitalized.
The models also revealed several vital characteristics distinguishing probable long COVID patients from non-long COVID patients. They only looked at individuals who had a positive COVID test and had been sick for at least 90 days. Post-COVID respiratory symptoms and treatments are more commonly identified among potential long COVID patients, as are non-respiratory symptoms commonly reported as part of long COVID, pre-existing risk factors for greater acute COVID severity, and proxies for hospitalization, indicating more significant critical COVID severity.
NCATS Acting Director Joni Rutter, Ph.D., remarked that these results attest to the profound influence of real-world clinical data and the potential possibilities of N3C to assist in better understanding and developing solutions for critical public health concerns like extended COVID.
The study looked at how data from electronic health records (EHRs) is slanted toward those who utilize healthcare systems more frequently. Uninsured people, patients with limited access to or ability to pay for care, and patients seeking care at small community hospitals with limited data interchange capabilities, according to Pfaff, are among those whose data is not very likely to be represented.
Dr. Pfaff, also Co-Director of the NC TraCS Informatics and Data Science (IDSci) Program, explained that Electronic Health Records only include information for persons who go to the doctor. So, if someone doesn’t have adequate access to care or doesn’t go to the doctor, they won’t have any information about them. They also have more data on folks who visit the doctor frequently. As a result, Pfaff provides this caution with every EHR-based study as they need to figure out who isn’t in the database.
As more real-world data becomes available, the N3C team continues to develop its models. Their longitudinal data for COVID patients can provide a solid foundation for creating machine learning algorithms to detect long-term COVID patients. Future studies will involve research to identify subgroups of long COVID, making the illness more straightforward to study and treat as more significant cohorts of long COVID patients are formed.
Pfadd also said that depending on where the study takes them, they may discover that patients with varied manifestations of extended COVID require fundamentally different therapy. As a result, they must determine if long COVID is a single illness or a group of similar disorders linked to having had acute COVID-19.
With this big data strategy, effective research recruiting attempts may be done to better grasp the complexity of extended COVID. Understanding and confirming the association between lengthy COVID and socioeconomic determinants of health and demographics, comorbidities, and treatment implications will only strengthen the algorithm in these models as more data arise and establish cohorts for research investigations.
This Article Is Based On The Research Paper 'Identifying who has long COVID in the USA: a machine learning approach using N3C data'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, and blog. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.