Understanding the Dark Side of Large Language Models: A Comprehensive Guide to Security Threats and Vulnerabilities
LLMs have become increasingly popular in the NLP (natural language processing) community in recent years. Scaling neural network-based machine learning models has led to recent advances, resulting in models that can generate natural language nearly indistinguishable from that produced by humans.
LLMs can boost human productivity, ranging from assisting with code generation to helping in email writing and co-writing university homework, and have exhibited amazing results across fields, including law, mathematics, psychology, and medicine. Despite these advances, the academic community has highlighted many problems related to the harmful use of their text-generating skills.
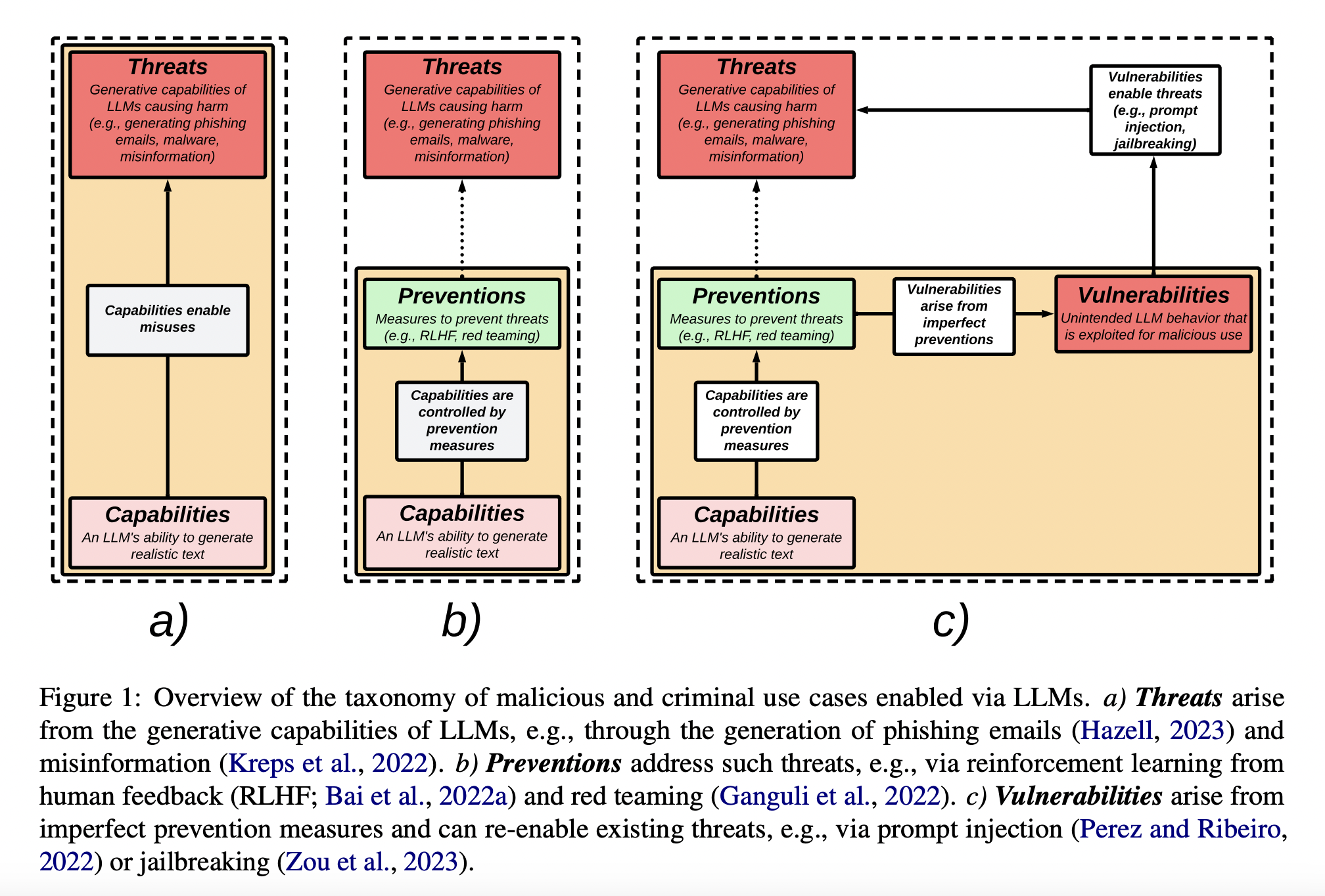
Therefore, researchers from Tilburg University and University College London survey the state of safety and security research on LLMs and provide a taxonomy of existing techniques by classifying them according to dangers, preventative measures, and security holes. LLMs’ sophisticated generating capabilities make them a natural breeding ground for threats such as the creation of phishing emails, malware, and false information.
Existing efforts, including content filtering, reinforcement learning from human feedback, and red teaming, all aim to reduce the risks posed by these capabilities. Then, flaws emerge from inadequate measures to forestall the dangers and conceal techniques like jailbreaking and immediate injection. This opens the door for previously disabled threats to return. The researchers clarify key terms and present a comprehensive bibliography of academic and real-world examples for each broad area.
The paper explains why any technique for addressing undesirable LLM behaviors that do not completely eradicate them renders the model vulnerable to adversarial quick attacks. Studies make a similar point, arguing that Large AI Models (LAIMs), which refer to foundation models including and beyond language, are inherently insecure and vulnerable due to three features attributable to their training data. They also note that there will be a significant drop in accuracy from the baseline model if we want to increase model security. That there is an inevitable trade-off between the precision of a standard model and its resilience against adversarial interventions. Such arguments further question the level of safety and security possible for LLMs. In light of the tension between an LLM’s practicality and security, it is crucial that both LLM providers and users carefully consider this trade-off.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.