University of Illinois Researchers Develop XMem; A Long-Term Video Object Segmentation Architecture Inspired By Atkinson-Shiffrin Memory Model
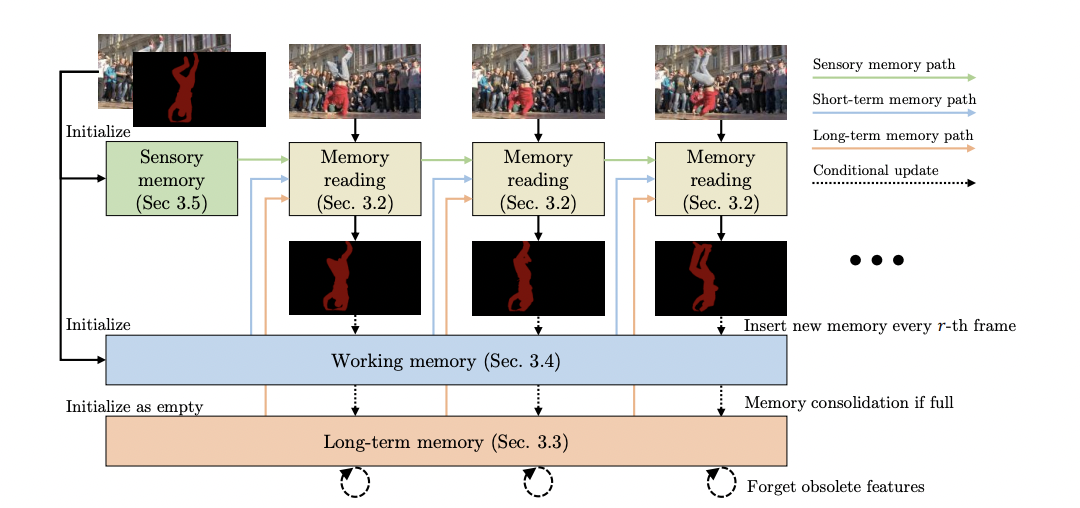
Video object segmentation (VOS) identifies and highlights certain target items in a video. Most VOS techniques use a feature memory to store relevant deep-net representations of an object since information must be transferred from the supplied annotation to other video frames. The focus here is on the semi-supervised situation, in which the user provides the first-frame annotation. After this, the approach separates objects in all subsequent frames as correctly as possible while running in real-time, online, and with a tiny memory footprint while processing large films.
The weights of a network are used as feature memory in online learning methods. This necessitates training during testing, which delays prediction. Recurrent approaches frequently transmit information from the most recent frames through a mask or a concealed representation. These approaches are prone to drifting and have difficulty dealing with occlusions. Recent cutting-edge VOS approaches utilize attention to connect representations of previous frames stored in feature memory with features derived from the newly observed query frame that has to be segmented. Despite their excellent efficiency, these approaches use a significant amount of GPU RAM to hold previous frame representations.
They typically struggle to handle films longer than a minute on consumer-grade technology. Some methods are mainly created for VOS in lengthy films. They frequently, however, forfeit segmentation quality. These strategies, in particular, reduce the representation size during feature memory insertion by merging new features with those already in the feature memory. Because high-resolution features are compressed immediately, they result in less accurate segmentations. Researchers believe that the negative relationship between performance and GPU memory usage directly results from employing a single feature memory type. To alleviate this constraint, they propose XMem, a unified memory architecture.
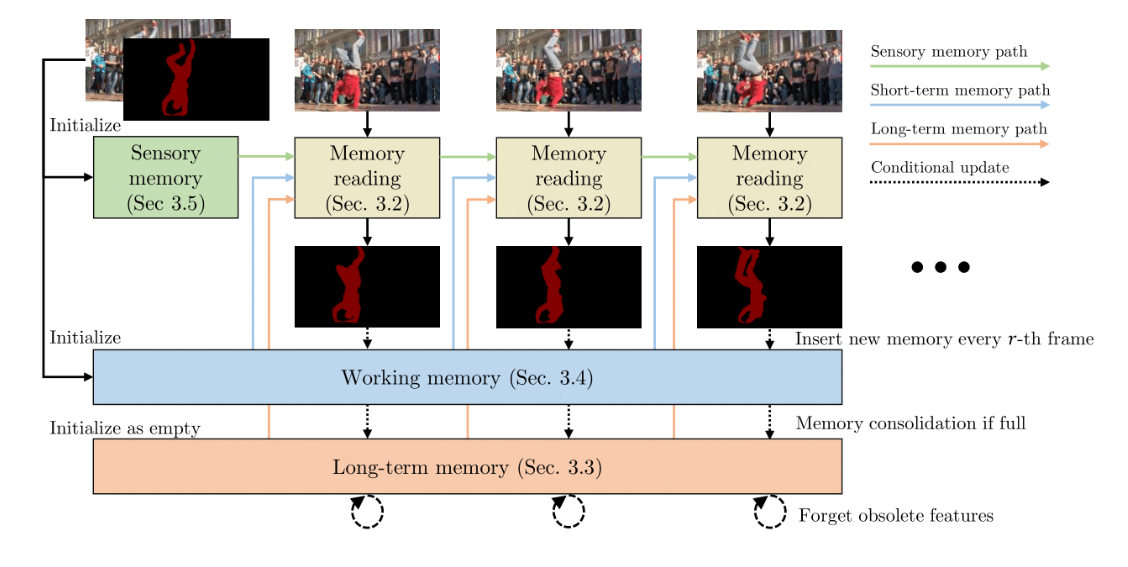
XMem maintains three independent yet deeply connected feature memory stores, inspired by the Atkinson-Shiffrin memory model, which hypothesizes that human memory consists of three components: a rapidly updated sensory memory, a high-resolution working memory, and a compact, thus sustained long-term memory. The sensory memory in XMem corresponds to the hidden representation of a GRU that is updated every frame. It delivers temporal smoothness but fails to forecast the long term owing to representation drift. On the other hand, working memory is agglomerated from a subset of historical frames and treats them all equally without drifting through time.
To manage the size of the working memory, XMem frequently consolidates its representations into long-term memory, a method inspired by the human memory’s consolidation mechanism. XMem stores long-term memory as a collection of ultra-compact prototypes. They design a memory potentiation approach to reduce aliasing caused by sub-sampling by aggregating richer information into these prototypes. They propose a space-time memory XMem: Long-Term Video Object Segmentation 3 reading procedure to read from working and long-term memory. Combining the three feature memory stores allows for the accurate processing of large films while keeping GPU memory utilization to a minimum.
On the Longtime Video dataset, they discover that XMem much outperforms previous state-of-the-art results. Notably, on short-video datasets, XMem performs on par with current state-of-the-art (which cannot handle long videos). It presents memory stores with multiple temporal scales. It equips them with a memory reading operation for high-quality video object segmentation on both long and short films, inspired by the Atkinson-Shiffrin memory model. It creates a memory consolidation method that picks representative prototypes from working memory, followed by a memory potentiation algorithm that enhances these prototypes into a compact yet powerful representation for long-term memory storage. The code implementation is freely available on Github.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.