Unlocking AI Potential with MINILLM: A Deep Dive into Knowledge Distillation from Larger Language Models to Smaller Counterparts
Knowledge distillation which involves training a small student model under the supervision of a big teacher model is a typical strategy to decrease excessive computational resource demand due to the fast development of large language models. Black-box KD, in which only the teacher’s predictions are accessible, and white-box KD, in which the teacher’s parameters are used, are the two kinds of KD that are often used. Black-box KD has recently demonstrated encouraging outcomes in optimizing tiny models on the prompt-response pairs produced by LLM APIs. White-box KD becomes increasingly helpful for research communities and industrial sectors when more open-source LLMs are developed since student models get better signals from white-box instructor models, potentially leading to improved performance.
While white-box KD for generative LLMs has not yet been investigated, it is mostly examined for small (1B parameters) language understanding models. They look into white-box KD of LLMs in this paper. They contend that the common KD could be better for LLMs that carry out tasks generatively. Standard KD objectives (including several variants for sequence-level models) essentially minimize the approximated forward Kullback-Leibler divergence (KLD) between the teacher and the student distribution, known as KL, forcing p to cover all the modes of q given the teacher distribution p(y|x) and the student distribution q(y|x)parameterized by. KL performs well for text classification problems because the output space often contains finite-number classes, ensuring that both p(y|x) and q(y|x) have a small number of modes.
However, for open text generation problems, where the output spaces are far more complicated, p(y|x) may represent a substantially wider range of modes than q(y|x). During free-run generation, minimizing forward KLD can lead to q giving the void regions of p excessively high probability and producing highly improbable samples under p. They suggest minimizing the reverse KLD, KL, which is commonly employed in computer vision and reinforcement learning, to solve this issue. A pilot experiment shows how underestimating KL drives q to seek the major modes of p and give its vacant areas a low probability.
This means that in the language generation of LLMs, the student model avoids learning too many long-tail versions of the instructor distribution and concentrates on the produced response’s accuracy, which is crucial in real-world situations where honesty and dependability are required. They generate the gradient of the objective with Policy Gradient to optimize min KL. Recent studies have demonstrated the effectiveness of policy optimization in optimizing PLMs. However, they also discovered that training the model still suffers from excessive variation, reward hacking, and generation length bias. As a result, they include:
- Single-step regularisation to lessen variation.
- Teacher-mixed sampling to lessen reward hacking.
- Length normalization to reduce length bias.
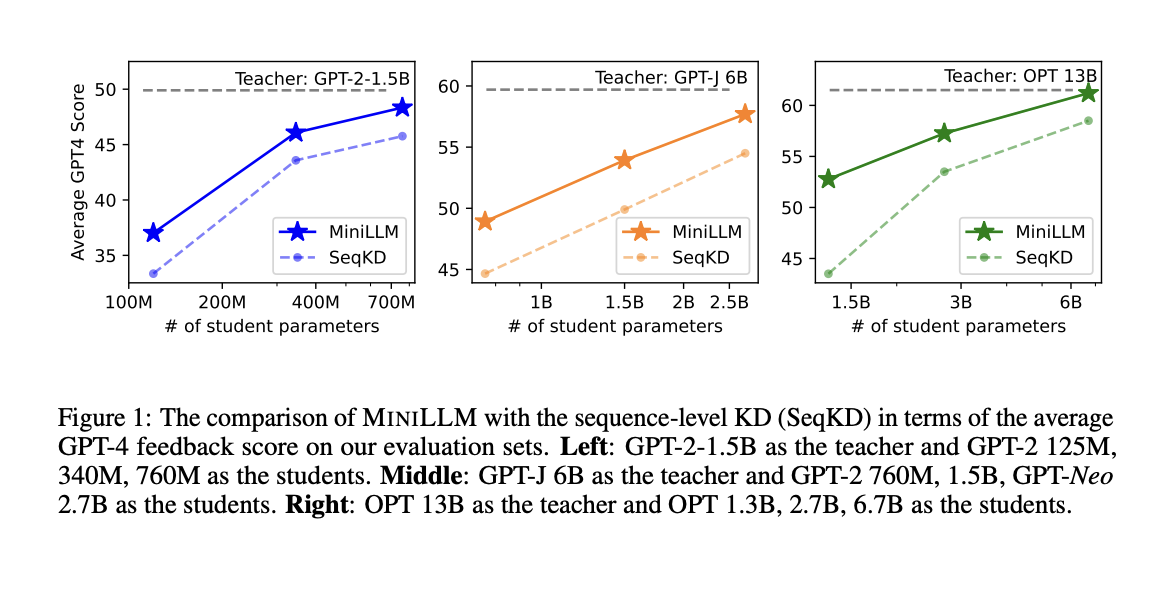
In the instruction-following setting, which encompasses a wide range of NLP tasks, researchers from The CoAI Group, Tsinghua University, and Microsoft Research offer a novel technique called MINILLM, which they then apply to several generative language models with parameter sizes ranging from 120M to 13B. Five instruction-following datasets and Rouge-L and GPT-4 feedback for assessment are used. Their tests demonstrate that MINILM scales up successfully from 120M to 13B models and consistently beats the baseline standard KD models on all datasets (see Figure 1). More research reveals that MINILLM works better at producing lengthier replies with more variety and has reduced exposure bias and better calibration. The models are available on GitHub.

Check Out The Paper and Github link. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.