Unlocking Efficiency in Vision Transformers: How Sparse Mobile Vision MoEs Outperform Dense Counterparts on Resource-Constrained Applications
A neural network architecture called a Mixture-of-Experts (MoE) combines the predictions of various expert neural networks. MoE models deal with complicated jobs where several subtasks or elements of the problem call for specialized knowledge. They were introduced to strengthen neural networks’ representations and enable them to handle various challenging tasks.
In addition, a neural network architecture known as sparsely-gated Mixture-of-Experts (MoE) models expands on the idea of conventional MoE models by adding sparsity to the gating mechanism. These models are created to increase the MoE designs’ efficiency and scalability, enabling them to handle large-scale jobs while lowering computing costs.
Due to their capacity to exclusively activate a small part of the model parameters for every given input token, they can decouple model size from inference effectiveness.
It’s still difficult to balance both performance and efficiency when using neural networks (NNs), especially when only few computational resources are available. Sparsely-gated Mixture-of-Experts models (sparse MoEs), which enable the decoupling of model size from inference effectiveness, have recently been viewed as a potential solution.
Sparse MoEs offer the prospect of augmenting model capabilities while minimizing computational costs. This makes them an option for integration with Transformers, the prevailing architectural choice for large-scale visual modeling.
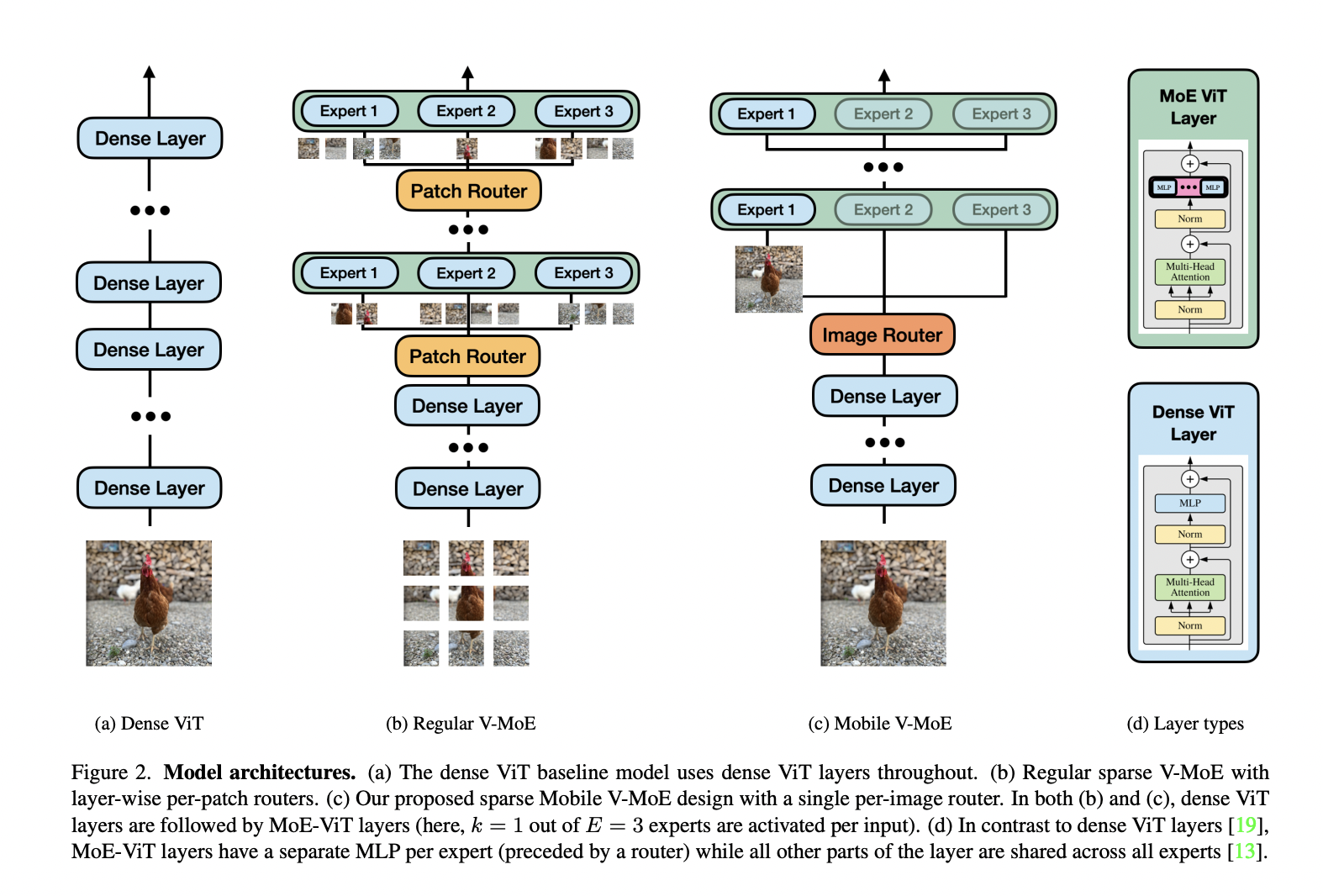
Consequently, an Apple research team introduced the concept of sparse Mobile Vision MoEs in their paper titled Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts. These V-MoEs are an efficient, mobile-friendly Mixture-of-Experts design that maintains remarkable model performance while downscaling Vision Transformers (ViTs).
The researchers have emphasized that they have developed a simple yet robust training procedure in which expert imbalance is avoided by leveraging semantic super-classes to guide router training. It utilizes single per-image router, as opposed to per-patch routing. In traditional per-patch routing, more experts are typically activated for each image. However, the per-image router reduces the number of activated experts per image.
The research team started the training phase by training a baseline model. The model’s predictions were then noted on a validation set withheld from the training dataset to create a confusion matrix. The confusion graph was then subjected to a graph clustering algorithm using this confusion matrix as the foundation. Super-class divisions were created as a result of this process.
They said the model presents empirical results on the standard ImageNet-1k classification benchmark. They trained all models from scratch on the ImageNet-1k training set of 1.28M images and then evaluated their top-1 accuracy on the validation set of 50K images.
The researchers want to use MoE design in other mobile-friendly models besides ViTs in the future. They also intend to take other visual tasks, such object detection, into account. Additionally, they want to quantify the actual on-device latency across all models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.