Unlocking the Power of Context with Google AI: A Showdown Between prefixLM and causalLM in In-Context Learning
The War of Troy is famous, where Achilles etched his name in history forever by defeating Prince Hector once and for all, but today, in the rapidly evolving landscape of artificial intelligence, the quest to harness context for improved learning and comprehension has taken center stage. Two contenders, prefixLM and causalLM, have entered the ring to combat in-context learning. As the battle between these language model giants rages on, it’s clear that the way they handle context will make all the difference in learning outcomes in machine learning.
The Challenger and the Conqueror
Both prefixLM and causalLM have entered the ring equipped with their unique theoretical frameworks. PrefixLM dons the armor of unrestricted attention, allowing all in-context samples to communicate freely. It treats each sample as a prefix and uses full attention on the first n positions in the battle.
In the other corner of the ring stands causalLM, armed with autoregressive attention – a mechanism that curbs interactions between in-context samples and their future counterparts. This strategy preserves a linear learning trajectory, preventing futuristic spoilers from influencing the learning process. It is a focused approach, but does it truly capture the essence of context? Can it defeat PrefixLM’s robust approach to ICL?
The Battle is Afoot
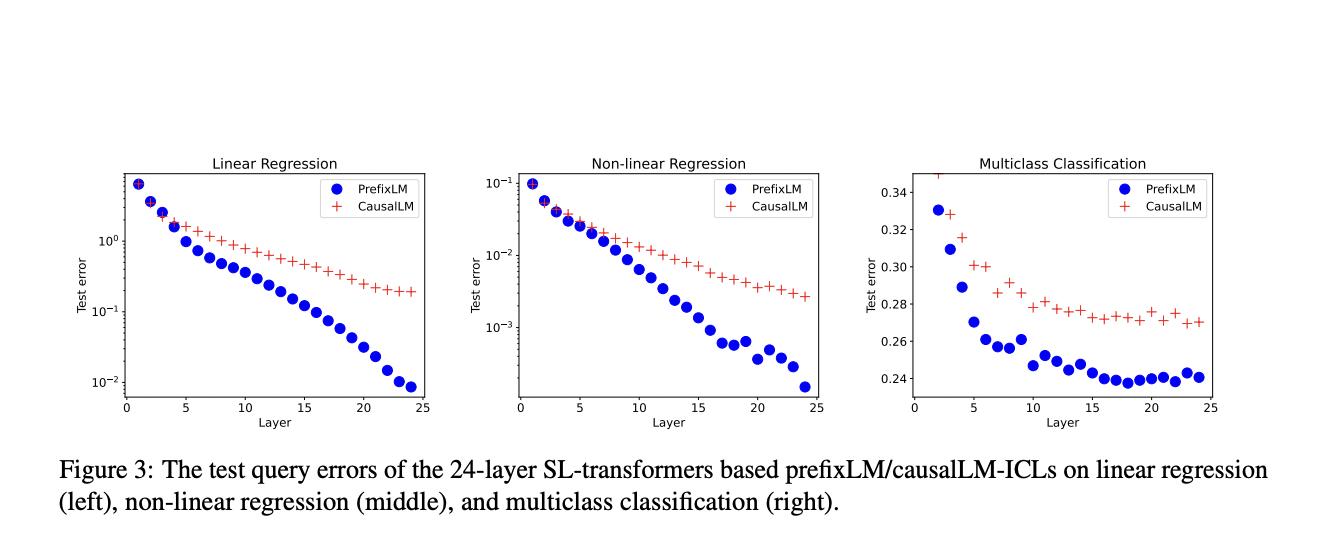
To separate theory from practice, a battlefield of synthetic numerical tasks becomes the proving ground relying on softmax transformers. Linear regression, nonlinear regression, and multiclass classification form the battleground where prefixLM and causalLM have locked horns. As the dust settles, the outcomes echo the voices of empirical evidence.
Amidst linear regression tasks, the training errors of both models exhibit linear decay rates, a testament to their learning prowess. However, the tide turns when the test errors emerge from the shadows. CausalLM stumbles with significantly larger test errors, raising eyebrows from the crowd. The culprit? The autoregressive nature of causalLM restricts the mutual attention between the in-context examples which yields it a suboptimal result.
The Champion rises from the ashes
With the empirical outcomes illuminating the path, it’s prefixLM that emerges as the champion of in-context learning. Its open-armed approach, enabling diverse in-context samples to communicate, appears to be the key. Whether it’s linear regression, nonlinear regression, or multiclass classification, prefixLM consistently showcases its superiority, proving that its power of context can’t be denied.
As the curtain falls on this clash of the titans, prefixLM stands tall, waving the banner of comprehensive context understanding. CausalLM, while valiant, might need to revisit its strategy in the in-context arena. The battle highlights that prefixLM is the champion today indeed, awaiting yet another challenger in the future in the battle of AI.
To a more mathematical approach to this battle to analyze PrefixLM’s triumph deeply, please refer to the research paper.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.