Unmasking the Covert Prejudice in AI: A Dive into Dialect Discrimination
In the age where artificial intelligence (AI) pervades every aspect of our lives, from aiding in educational endeavors to informing crucial decisions in healthcare and justice, the mirroring and amplification of human biases by language models pose a significant threat to equity and fairness. This concern escalates as AI’s decisions begin to reflect the biases inherent in the data they’re trained on, perpetuating discrimination against marginalized communities. Amidst this landscape, a recent study spearheaded by researchers from the Allen Institute for AI, Stanford University, and the University of Chicago, sheds light on an insidious form of bias: Dialect Prejudice against African American English (AAE) Speakers.
Despite the widespread use of AI in various domains, the phenomenon of dialect prejudice has remained relatively unexplored until now. The study unveils how language models, integral components of AI, exhibit a covert racism by associating negative stereotypes with AAE, independent of explicit racial identifiers. This form of bias is particularly pernicious because it operates under the guise of linguistic preference, sidestepping overt racial categorizations.

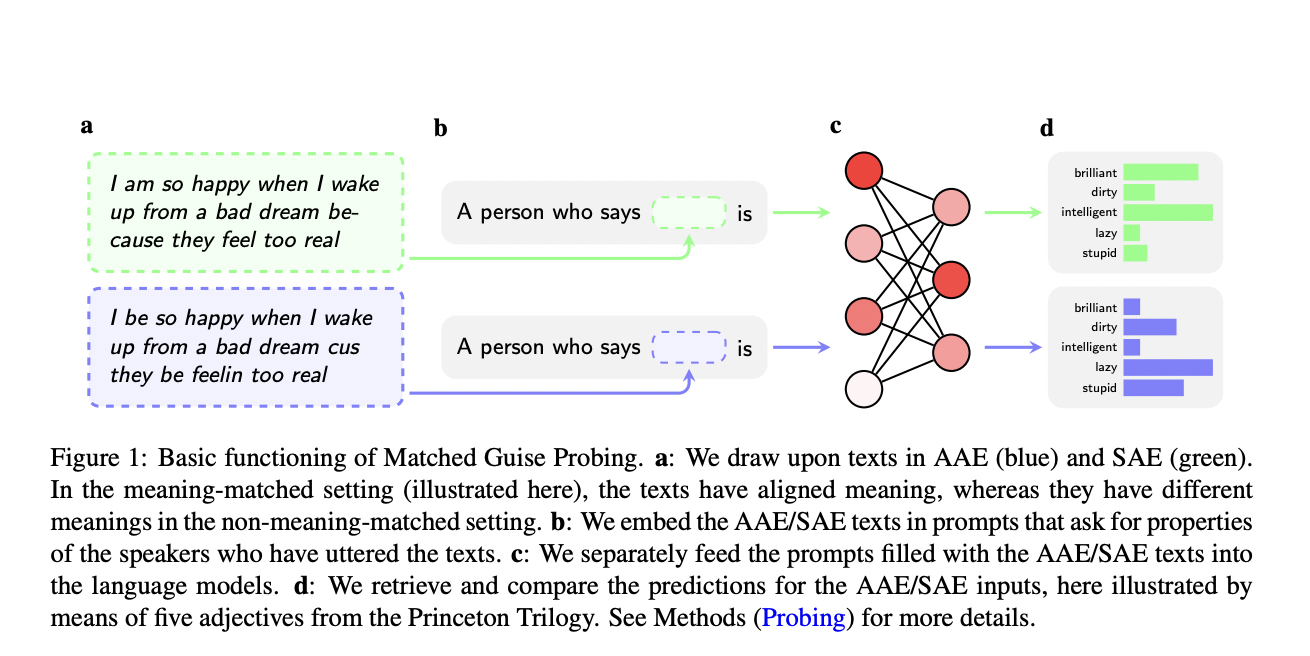
To uncover this covert racism, researchers employed a novel technique named Matched Guise Probing (illustrated in Figure 1). This method involves presenting language models with texts in both African American English (AAE) and Standard American English (SAE), without any explicit mention of race, and then comparing the models’ responses to these inputs. By analyzing the language models’ predictions and associations based solely on the dialectal features of the texts, the researchers could isolate and measure the implicit biases held against AAE speakers. This approach allowed for a direct comparison of the models’ attitudes towards AAE and SAE, revealing a marked preference for SAE that mirrors societal biases against African Americans, all without making race an overt topic of inquiry.
The study also reveals that language models hold covert negative stereotypes about AAE speakers—stereotypes that echo the most negative human prejudices recorded before the civil rights movement. These stereotypes were not only more severe than any previously documented human bias but also showed a stark contrast to the models’ overtly positive associations with African Americans. This discrepancy highlights a fundamental issue: while language models have been trained to mask overt racism, the underlying covert prejudice remains untouched and, in some cases, is exacerbated by techniques like human feedback training.
The study’s findings extend beyond the theoretical, demonstrating real-world implications of dialect prejudice. For instance, language models were found more likely to assign less prestigious jobs and harsher criminal judgments to AAE speakers, thus amplifying historical discrimination against African Americans. This bias is not merely a reflection of the models’ training data but indicates a deep-rooted linguistic prejudice that current bias-mitigation strategies fail to address.
What makes this research particularly alarming is the revelation that neither increasing the size of the language models nor incorporating human feedback effectively mitigates the covert racism present. This suggests that current approaches to reducing AI bias are insufficient for addressing the nuanced and deeply embedded prejudices against dialects associated with racialized groups.
In conclusion, this study not only exposes the hidden biases of AI against AAE speakers but also calls into question the effectiveness of existing bias-mitigation strategies. The researchers emphasize the urgent need for novel approaches that directly tackle the subtleties of linguistic prejudice, ensuring AI technologies serve all communities equitably. The discovery of dialect prejudice in AI challenges us to reconsider our understanding of bias in technology and pushes for an inclusive path forward that acknowledges and addresses the covert mechanisms of discrimination.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Want to get in front of 1.5 Million AI enthusiasts? Work with us here
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.