Unveiling the Secrets of Multimodal Neurons: A Journey from Molyneux to Transformers
Transformers could be one of the most important innovations in the artificial intelligence domain. These neural network architectures, introduced in 2017, have revolutionized how machines understand and generate human language.
Unlike their predecessors, transformers rely on self-attention mechanisms to process input data in parallel, enabling them to capture hidden relationships and dependencies within sequences of information. This parallel processing capability not only accelerated training times but also opened the way for the development of models with significant levels of sophistication and performance, like the famous ChatGPT.
Recent years have shown us how capable artificial neural networks have become in a variety of tasks. They changed the language tasks, vision tasks, etc. But the real potential lies in crossmodal tasks, where they integrate various sensory modalities, such as vision and text. These models have been augmented with additional sensory inputs and have achieved impressive performance on tasks that require understanding and processing information from different sources.
In 1688, a philosopher named William Molyneux presented a fascinating riddle to John Locke that would continue to captivate the minds of scholars for centuries. The question he posed was simple yet profound: If a person blind from birth were suddenly to gain their sight, would they be able to recognize objects they had previously only known through touch and other non-visual senses? This intriguing inquiry, known as the Molyneux Problem, not only delves into the realms of philosophy but also holds significant implications for vision science.
In 2011, vision neuroscientists started a mission to answer this age-old question. They found that immediate visual recognition of previously touch-only objects is not feasible. However, the important revelation was that our brains are remarkably adaptable. Within days of sight-restoring surgery, individuals could rapidly learn to recognize objects visually, bridging the gap between different sensory modalities.
Is this phenomenon also valid for multimodal neurons? Time to meet the answer.
We find ourselves in the middle of a technological revolution. Artificial neural networks, particularly those trained on language tasks, have displayed remarkable prowess in crossmodal tasks, where they integrate various sensory modalities, such as vision and text. These models have been augmented with additional sensory inputs and have achieved impressive performance on tasks that require understanding and processing information from different sources.
One common approach in these vision-language models involves using an image-conditioned form of prefix-tuning. In this setup, a separate image encoder is aligned with a text decoder, often with the help of a learned adapter layer. While several methods have employed this strategy, they have usually relied on image encoders, such as CLIP, trained alongside language models.
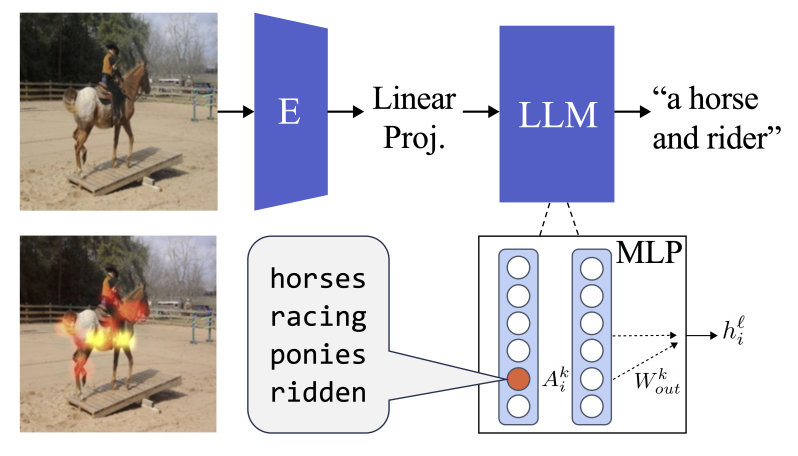
However, a recent study, LiMBeR, introduced a unique scenario that mirrors the Molyneux Problem in machines. They used a self-supervised image network, BEIT, which had never seen any linguistic data and connected it to a language model, GPT-J, using a linear projection layer trained on an image-to-text task. This intriguing setup raises fundamental questions: Does the translation of semantics between modalities occur within the projection layer, or does the alignment of vision and language representations happen inside the language model itself?
The research presented by the authors at MIT seeks to find answers to this 4 centuries-old mystery and shed light on how these multimodal models work.
First, they found that image prompts transformed into the transformer’s embedding space do not encode interpretable semantics. Instead, the translation between modalities occurs within the transformer.
Second, multimodal neurons, capable of processing both image and text information with similar semantics, are discovered within the text-only transformer MLPs. These neurons play a crucial role in translating visual representations into language.
The final and perhaps the most important finding is that these multimodal neurons have a causal effect on the model’s output. Modulating these neurons can lead to the removal of specific concepts from image captions, highlighting their significance in the multimodal understanding of content.
This investigation into the inner workings of individual units within deep networks uncovers a wealth of information. Just as convolutional units in image classifiers can detect colors and patterns, and later units can recognize object categories, multimodal neurons are found to emerge in transformers. These neurons are selective for images and text with similar semantics.
Furthermore, multimodal neurons can emerge even when vision and language are learned separately. They can effectively convert visual representations into coherent text. This ability to align representations across modalities has wide-reaching implications, making language models powerful tools for various tasks that involve sequential modeling, from game strategy prediction to protein design.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.