US Hardware Startup, Cerebras, Sets Record For Largest AI Model Being Trained On One Device

When it comes to powerful chips, the US company Cerebras has you covered. They have trained their AI model on a single device powered by Wafer Scale Engine 2 – which is considered the world’s largest chip in terms of processing power.
According to the AI startup, A single CS-2 system may cut the engineering time and work required to train natural language processing (NLP) models from months to minutes. The branch of AI known as natural language processing (NLP) aims to make it possible for computers to analyze and comprehend human language from text or speech data.
One of the “most unpleasant elements” of training big NLP models, which often entails distributing the model across hundreds or thousands of different GPUs, will be eliminated, according to Cerebras, as a result of its most recent finding.
The mechanism of dividing a model among GPUs, according to the business, is exclusive to each pair of network compute clusters, making it impossible to transfer the work to other clusters or neural networks.
The Cerebras WSE-2 processor, which the manufacturer claims to be the biggest processor ever made, made it feasible to train a sizable model on a single device. It is 56 times bigger than the biggest GPU, with 2.55 trillion more transistors and 100 times as many computation cores.
A new chip cluster that might “unlock brain-scale neural networks” is being powered by the WSE-2 processor, according to a statement made by Cerebras last year. The AI business claimed that a single CS-2 could handle models with hundreds of billions or trillions of parameters using this processor.
Scaling ML across GPU clusters: Challenges
The distributed computation challenge of spreading the training of an extensive network over a cluster of processors is challenging. Large neural networks and other computational issues that can’t be solved on a single processor fall under this category. It takes a lot of effort to divide computing, memory, and communication and then spread them over hundreds or thousands of processors. The fact that every CPU, memory, and network allocation across a processor cluster is customized complicates matters further: partitioning a neural network on a particular processor cluster is exclusive to that neural network and that cluster hardware. A different partitioning would be necessary for another neural network on the same cluster. Different partitioning on another cluster would also be needed for even the same neural network. Although this is common knowledge in distributed computing, we appear to have forgotten it as distributed computation and AI has quickly and unavoidably merged.
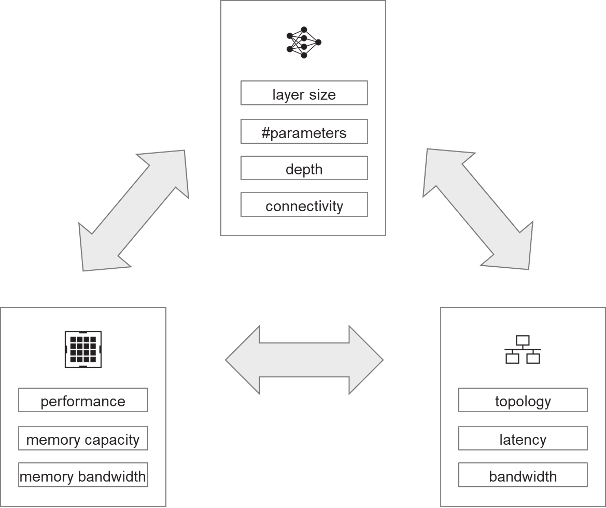
Given the distinctive properties of the neural network, the unique properties of each processor in the cluster, and the specific properties of the communication network connecting the processors, it is possible to distribute a neural network over a particular cluster of processors (Figure 1). The size, depth, parameters, and communication structure of the model interact with the compute performance, memory capacity, and memory bandwidth of each processor, as well as the topology, latency, and bandwidth of the communication network, to determine how to distribute the neural network over the cluster.
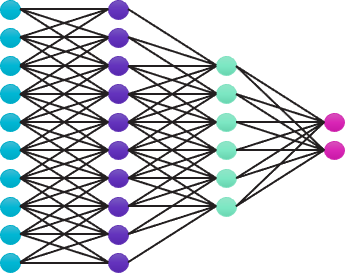
Let’s look at this in further depth. Think of a straightforward, four-layer neural network like Figure 2. A distinct hue designates each layer. Each layer performs computations and then transmits the results to the following layer, which utilizes them to conduct its own calculations.
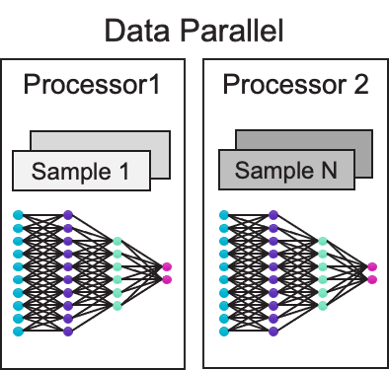
Data-Parallel
It is simple to train a neural network if it can fit on a single CPU. Data parallelism may then be used to speed up training when several processors are available.
As illustrated in Figure 3, we divide the data in half for data-parallel training and repeat the whole network on Processors 1 and 2. The findings are then averaged after sending half the data to Processor 1 and a half to Processor 2. Because the data is divided in half and processed simultaneously, this is known as data parallelism. If all goes according to plan, training should take about half as long with two processors as it did with one.
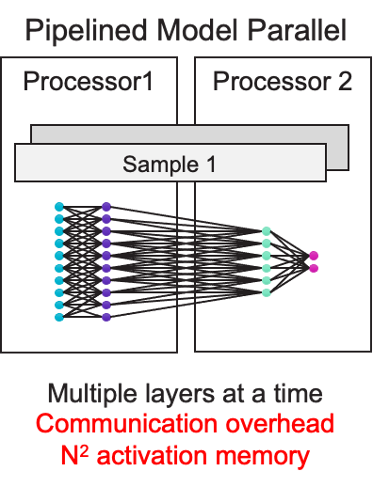
Parallel Pipeline Model
As illustrated in Figure 4, the problem for Pipeline Model Parallel is split up by assigning specific layers to Processor 1 and some layers to Processor 2. The challenging aspect of this type of parallelization is that the levels operate in a pipeline. Before Processor 2 can start, the results from a specific layer must go from Processor 1 onto Processor 2. The latency and bandwidth of the network are under a great deal of stress.
Tensor Parallel Model
What happens if a graphics processor can’t fit even one layer? The tensor model parallel is then required. Here, a single layer is divided across many CPUs. Therefore, as shown in Figure 5, a portion of layer 1 is placed on Processor 1, and a bit of layer 1 is set on Processor 2. This increases complexity by a further level, puts strain on bandwidth, and requires human user input. Each layer, processor, and network performance must be painstakingly instrumented for weeks or months. The model and cluster’s essential characteristics will also cap the speedup that can be achieved through this approach. When expanding beyond a single GPU server, the latency of these communication activities across processors becomes a bottleneck since tensor model parallelism necessitates frequent communication at the layer level. Because only 4 or 8 GPUs can fit in a single server, this method’s level of parallelism is typically restricted to that amount in practice. Simply said, the network protocols required for server-to-server communication are too sluggish.
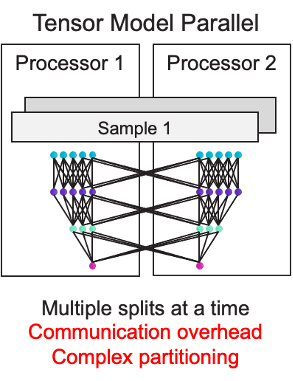
Figure 4. Execution in parallel to a pipelined model. On each device, layers of the neural network operate concurrently. Source: https://www.cerebras.net/blog/cerebras-sets-record-for-largest-ai-models-ever-trained-on-single-device
Hybrid Parallelism
Due to size and hardware constraints, all three methods—data-parallel, pipeline model parallel, and tensor model parallel—must be employed to train the most significant neural networks on GPU clusters. The company investigated some of the most extensive networks ever published by looking at the number of GPUs required to operate the neural network and the various forms of parallelization needed to train a range of models (Figure 6).
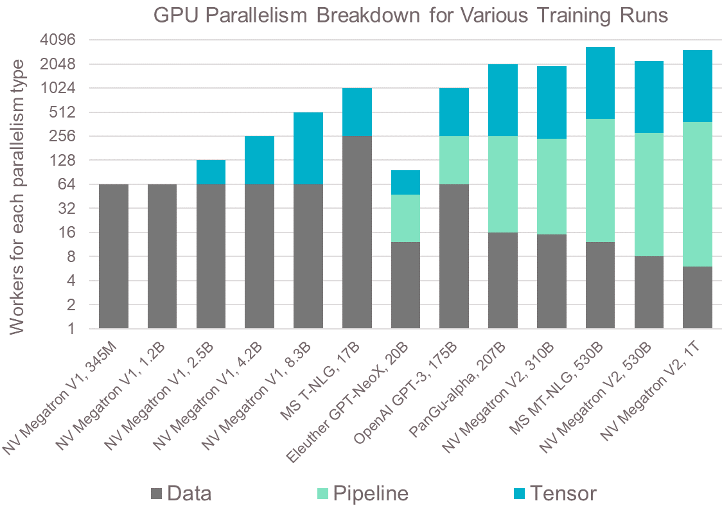
The network may run data in parallel in “small” networks (up to 1.2B parameters). The degree of parallelism is pretty great with 64 GPUs, even in these more straightforward scenarios. Because of the spread of training over numerous physical servers, complex software is needed to manage the task. When gradients are aggregated after each step of the communication phase, a high-speed interconnect network and extremely effective reduction primitives are required to prevent a performance bottleneck. In addition, there is a batch size restriction, particularly for these smaller models, which reduces the amount of data parallelism that can be used without hitting this communication barrier.
Summary
Customers of Cerebras may now train NLP models with billions of parameters on a single machine. These enormous models may currently be deployed in a matter of minutes rather than months. It merely only a few keystrokes to switch between several model sizes, and there is no intricate parallelism. They take up much less room and electricity. Organizations without sizable dispersed systems engineering teams can nonetheless use them.
References:
- https://www.cerebras.net/blog/cerebras-sets-record-for-largest-ai-models-ever-trained-on-single-device
- https://venturebeat.com/2022/06/22/cerebras-systems-sets-record-for-largest-ai-models-ever-trained-on-one-device/
- https://www.theregister.com/2022/06/27/in_brief_ai/
- https://www.businesswire.com/news/home/20220622005318/en/Cerebras-Systems-Sets-Record-for-Largest-AI-Models-Ever-Trained-on-a-Single-Device
Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.