Using AI to Summarize Lengthy ‘How To’ Videos
If you’re the kind to ratchet up the speed of a YouTube how-to video in order to get to the information you actually want; consult the video’s transcript to glean the essential information hidden in the long and often sponsor-laden runtimes; or else hope that WikiHow got round to creating a less time-consuming version of the information in the instructional video; then a new project from UC Berkeley, Google Research and Brown University may be of interest to you.
Titled TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency, the new paper details the creation of an AI-aided video summarization system that can identify pertinent steps from the video and discard everything else, resulting in brief summaries that quickly cut to the chase.

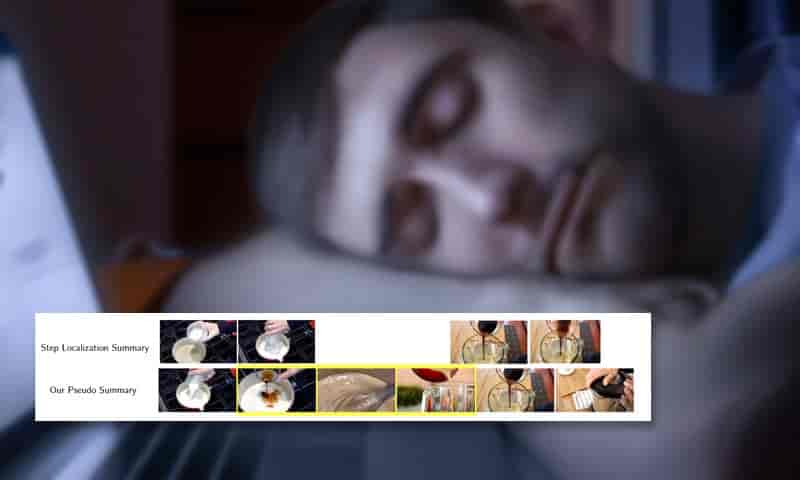
WikiHow’s exploitation of existing long video clips for both text and video information is used by the IV-Sum project to generate faux summaries that provide the ground truth to train the system. Source: https://arxiv.org/pdf/2208.06773.pdf
The resulting summaries have a fraction of the original video’s runtime, while multi-modal (i.e. text-based) information is also recorded during the process so that future systems could potentially automate the creation of WikiHow-style blog posts that are able to automatically parse a prolix how-to video into a succinct and searchable short article, complete with illustrations, potentially saving time and frustration.
The new system is called IV-Sum (‘Instructional Video Summarizer’), and uses the open source ResNet-50 computer vision recognition algorithm, among several other techniques, to individuate pertinent frames and segments of a lengthy source video.

The conceptual work-flow for IV-Sum.
The system is trained on pseudo-summaries generated from the content structure of the WikiHow website, where real people often leverage popular instructional videos into a flatter, text-based multimedia form, frequently using short clips and animated GIFs taken from source instructional videos.
Discussing the project’s use of WikiHow summaries as a source of ground truth data for the system, the authors state:
‘Each article on the WikiHow Videos website consists of a main instructional video demonstrating a task that often includes promotional content, clips of the instructor speaking to the camera with no visual information of the task, and steps that are not crucial for performing the task.
‘Viewers who want an overview of the task would prefer a shorter video without all of the aforementioned irrelevant information. The WikiHow articles (e.g., see How to Make Sushi Rice) contain exactly this: corresponding text that contains all the important steps in the video listed with accompanying images/clips illustrating the various steps in the task.’
The resulting database from this web-scraping is called WikiHow Summaries. The database consists of 2,106 input videos and their related summaries. This is a notably larger size of dataset than is commonly available for video summarization projects, which normally require expensive and labor-intensive manual labeling and annotation – a process that has been largely automated in the new work, thanks to the more restricted ambit of summarizing instructional (rather than general) videos.
IV-Sum leverages temporal 3D convolutional neural network representations, rather than the frame-based representations that characterize prior similar works, and an ablation study detailed in the paper confirms that all the components of this approach are essential to the system’s functionality.
IV-Sum tested favorably against various comparable frameworks, including CLIP-It (which several of the paper’s authors also worked on).

IV-Sum scores well against comparable methods, possibly due to its more restricted application scope, in comparison with the general run of video summarization initiatives. Details of metrics and scoring methods further down this article.
Method
The first stage in the summarization process involves using a relatively low-effort, weakly-supervised algorithm to create pseudo-summaries and frame-wise importance scores for a large number of web-scraped instructional videos, with only a single task label in each video.
Next, an instructional summarization network is trained on this data. The system takes auto-transcribed speech (for instance, YouTube’s own AI-generated subtitles for the video) and the source video as input.
The network comprises a video encoder and a segment scoring transformer (SST), and training is guided by the importance scores assigned in the pseudo-summaries. The ultimate summary is created by concatenating segments that achieved a high importance score.
From the paper:
‘The main intuition behind our pseudo summary generation pipeline is that given many videos of a task, steps that are crucial to the task are likely to appear across multiple videos (task relevance).
‘Additionally, if a step is important, it is typical for the demonstrator to speak about this step either before, during, or after performing it. Therefore, the subtitles for the video obtained using Automatic Speech Recognition (ASR) will likely reference these key steps (cross-modal saliency).’

To generate the pseudo-summary, the video is first uniformly partitioned into segments, and the segments grouped based on their visual similarity into ‘steps’ (different colors in the image above). These steps are then assigned importance scores based on ‘task relevance’ and ‘cross-modal saliency’ (i.e. the correlation between ASR text and images). High-scoring steps are then chosen to represent stages in the pseudo-summary.
The system uses Cross-Modal Saliency to help establish the relevance of each step, by comparing the interpreted speech with the images and actions in the video. This is accomplished by the use of a pre-trained video-text model where each element is jointly trained under MIL-NCE loss, using a 3D CNN video encoder developed by, among others, DeepMind.
A general importance score is then obtained from a calculated average of these task relevance and cross-modal analysis stages.
Data
An initial pseudo-summaries dataset was generated for the process, comprising most of the contents of two prior datasets – COIN, a 2019 set containing 11,000 videos related to 180 tasks; and Cross-Task, which contains 4,700 instructional videos, of which 3,675 were used in the research. Cross-Task features 83 different tasks.

Above, examples from COIN; below, from Cross-Task. Sources, respectively: https://arxiv.org/pdf/1903.02874.pdf and https://openaccess.thecvf.com/content_CVPR_2019/papers/Zhukov_Cross-Task_Weakly_Supervised_Learning_From_Instructional_Videos_CVPR_2019_paper.pdf
Using videos that featured in both datasets only once, the researchers were thus able to obtain 12,160 videos spanning 263 different tasks, and 628.53 hours of content for their dataset.
To populate the WikiHow-based dataset, and to provide the ground truth for the system, the authors scraped WikiHow Videos for all long instructional videos, together with their images and video clips (i.e. GIFs) associated with each step. Thus the structure of WikiHow’s derived content was to serve as a template for the individuation of steps in the new system.
Features extracted via ResNet50 were used to cross-match the cherry-picked sections of video in WikiHow images, and perform localization of the steps. The most similar obtained image within a 5-second video window was used as the anchor point.
These shorter clips were then stitched together into videos that would comprise the ground truth for the training of the model.
Labels were assigned to each frame in the input video, to declare whether they belonged to the input summary or not, with each video receiving from the researchers a frame-level binary label, and an averaged summary score obtained via the importance scores for all frame in the segment.
At this stage, the ‘steps’ in each instructional video were now associated with text-based data, and labeled.
Training, Tests, and Metrics
The final WikiHow dataset was divided into 1,339 test videos and 768 validation videos – a noteworthy increase on the average size of non-raw datasets dedicated to video analysis.
The video and text encoders in the new network were jointly trained on an S3D network with weights loaded from a pretrained HowTo100M model under MIL-NCE loss.
The model was trained with the Adam optimizer at a learning rate of 0.01 at a batch size of 24, with Distributed Data Parallel linking spreading the training across eight NVIDIA RTX 2080 GPUs, for a total of 24GB of distributed VRAM.
IV-Sum was then compared to various scenarios for CLIP-It in accordance with similar prior works, including a study on CLIP-It. Metrics used were Precision, Recall and F-Score values, across three unsupervised baselines (see paper for details).
The results are listed in the earlier image, but the researchers note additionally that CLIP-It misses a number of possible steps at various stages in the tests which IV-Sum does not. They ascribe this to CLIP-It having been trained and developed using notably smaller datasets than the new WikiHow corpus.
Implications
The arguable long-term value of this strand of research (which IV-Sum shares with the broader challenge of video analysis) could be to make instructional video clips more accessible to conventional search engine indexing, and to enable the kind of reductive in-results ‘snippet’ for videos that Google will so often extract from a longer conventional article.
Obviously, the development of any AI-aided process that reduces our obligation to apply linear and exclusive attention to video content could have ramifications for the appeal of the medium to a generation of marketers for whom the opacity of video was perhaps the only way they felt they could exclusively engage us.
With the location of the ‘valuable’ content hard to pin down, user-contributed video has enjoyed a wide (if reluctant) indulgence from media consumers in regard to product placement, sponsor slots and the general self-aggrandizement in which a video’s value proposition is so often couched. Projects such as IV-Sum hold the promise that eventually sub-facets of video content will become granular and separable from what many consider to be the ‘ballast’ of in-content advertising and non-content extemporization.
First published 16th August 2022. Updated 2.52pm 16th August, removed duplicate phrase.
Credit: Source link
Comments are closed.