UTokyo Researchers Introduce A Novel Synthetic Training Data Called Self-Blended Images (SBIs) To Detect Deepfakes
This Article Is Based On The Research Paper 'Detecting Deepfakes with Self-Blended Images'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
The Internet has been swamped with AI-powered facial image creation and modification in recent years. While applications like face-aging, sentiment-editing, and style-transfer might be entertaining for users, advanced image generation technologies are also being used maliciously to make deepfake images. Thanks to state-of-the-art models and tools, it has become increasingly easy to deceive even deepfake detection models.
In a new paper, A research team from the University of Tokyo has addressed this challenge of deepfake detection using Self-blended images (SBIs). This unique synthetic training data methodology outperforms state-of-the-art techniques on unseen manipulations.
The study aims to find statistical anomalies in deep fakes transmitted faces and backdrop image information. Their SBI strategy is based on learning more broad and robust representations to help classifiers learn more general and rarely recognized false data. SBI creates synthetic false samples with difficult-to-detect typical forging traces by blending fake source and target images from a single image. These samples will then be used to train more reliable detectors.

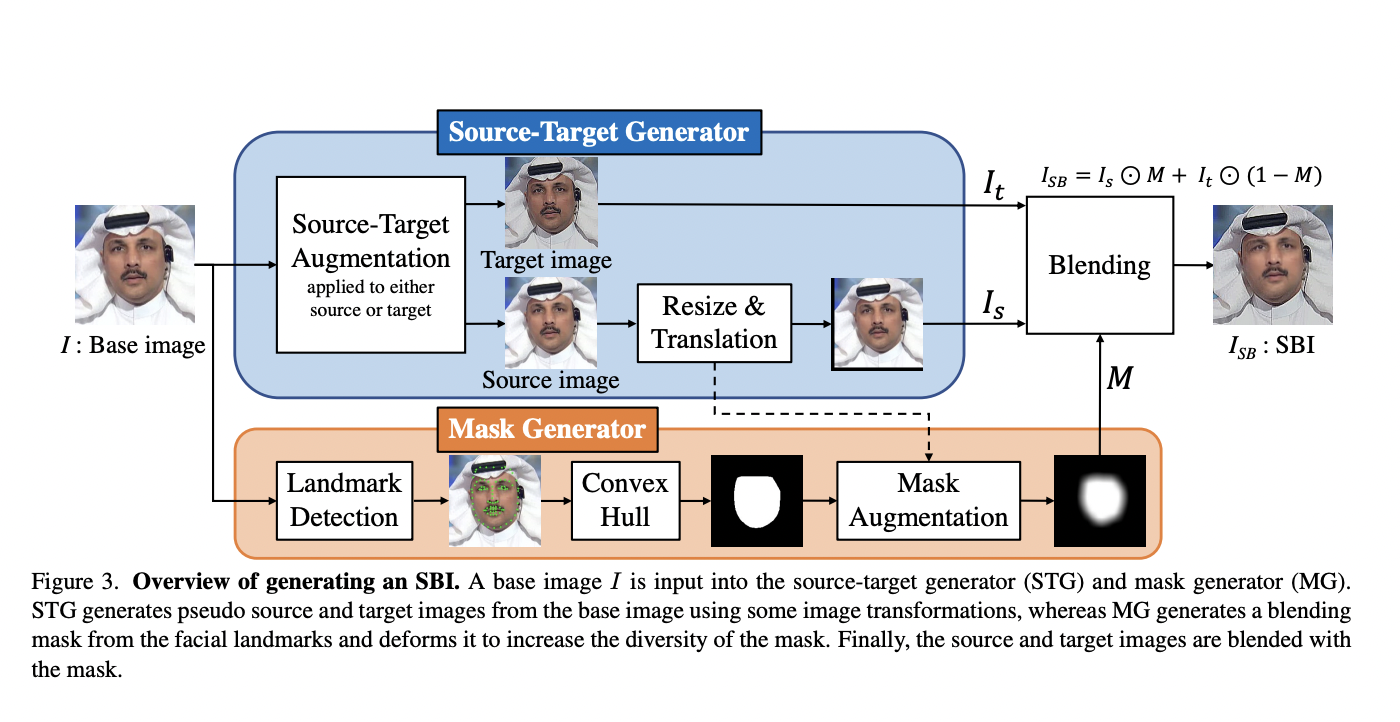
There are three primary steps in the SBI pipeline:
- A source-target generator creates false source and target images for blending.
- A mask generator creates a gray-scale deform mask image.
- The source and target images are mixed with the mask to produce an SBI.
On the FF++, CDF, DFDCP, DFDC, DFD, and FFIW datasets, the researchers compared their SBI technique to frame-level state-of-the-art detection methods like DSPFWA, Face X-ray, Local relation learning (LRL), FRDM, and Pair-wise self-consistency learning (PCL). They compared their model to video-level benchmarks like DAM (Discriminative attention models) and FTCN(Fully temporal convolution networks).

In cross-dataset evaluations on the DFDC and DFDCP datasets, the SBI strategy outperformed the baselines by 4.90 percent and 11.78 percent, respectively. Overall, the SBI synthetic training data technique outperforms state-of-the-art algorithms on previously unknown deepfake manipulations and scenes and can generalize throughout all network architectures and training datasets without significant performance degradation.
Paper: https://arxiv.org/pdf/2204.08376.pdf
Github: https://github.com/mapooon/SelfBlendedImages
Credit: Source link
Comments are closed.