Video Editing is a Challenge No More: INVE is an AI Method That Enables Interactive Neural Video Editing
Can you imagine the Internet without image editing? All those funny memes, fancy Instagram photos, mesmerizing sceneries, and more; would’ve been gone. That wouldn’t be a fun Internet, would it?
Since the early days of digital cameras, image editing has been a passion for many people. We had tools that could do straightforward edits in the beginning, but nowadays, you can literally turn anything into anything in an image without much effort. Image editing tools have advanced remarkably, especially in recent years, thanks to all these powerful AI methods.
However, when it comes to video editing, it is lagging behind. Video editing is something that often requires technical expertise and sophisticated software. You need to dive into complex tools like Premier and FinalCut Pro and try to adjust every single detail yourself. No wonder video editing is a high-paying skill nowadays. Image editing, on the other hand, can even be done on mobile apps, and results are sufficient for average users.
Imagine the possibilities if interactive video editing could become just as user-friendly as its image editing counterpart. Imagine you could say goodbye to technical complexities and say hello to a whole new level of freedom! Time to meet INVE.
INVE (Interactive Neural Video Editor) is an AI model that tackles the video editing problem, as the name suggests. It proposes a way for non-professional users to perform complex edits on videos effortlessly.
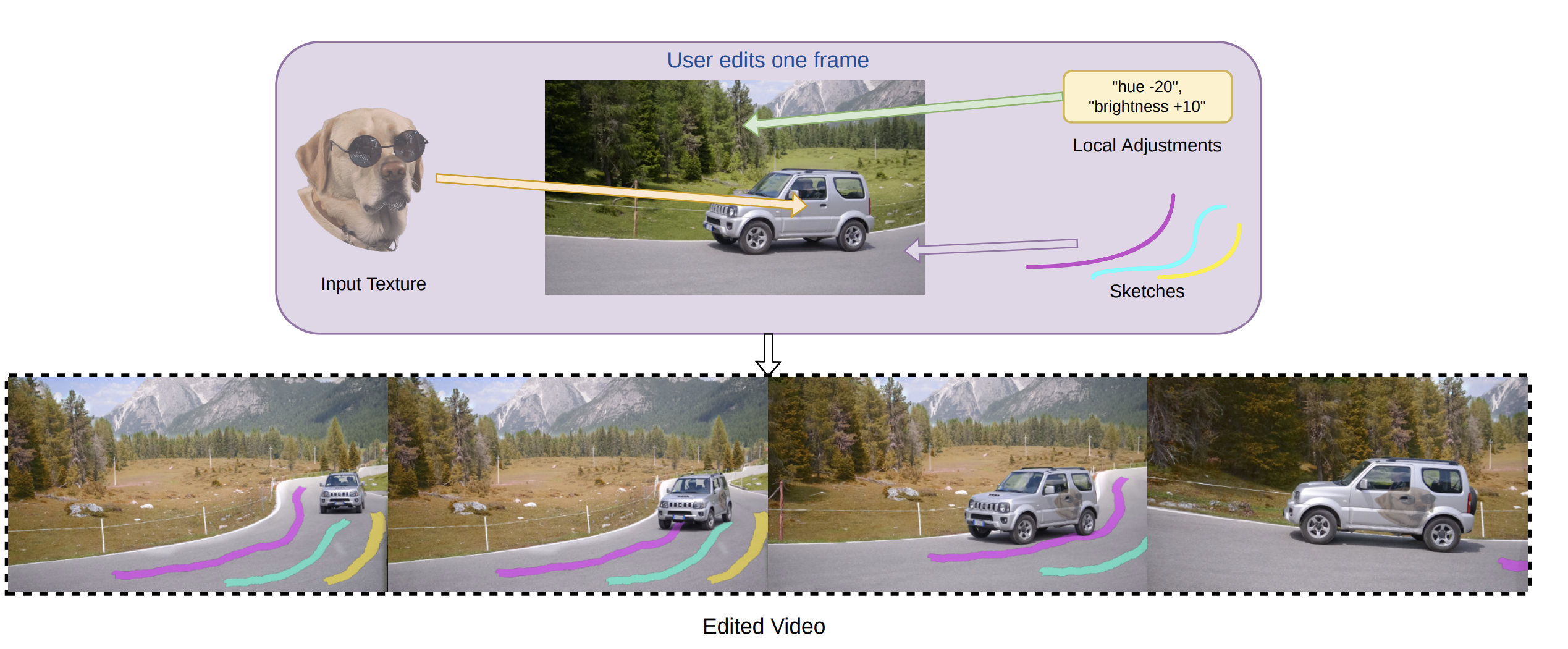
The main goal of INVE is to enable users to make complex edits to videos in a simple and intuitive manner. The approach builds on layered neural atlas representations, which consist of 2D atlases (images) for each object and the background in the video. These atlases allow for localized and consistent edits
Video editing is cumbersome due to several inherent challenges. For instance, different objects in a video may move independently, necessitating precise localization and careful composition to avoid unnatural artifacts. Moreover, editing individual frames can lead to inconsistencies and visible glitches. To address these issues, INVE introduces a novel approach using layered neural atlas representations.
The idea is to represent a video as a set of 2D atlases, one for each moving object and another for the background. This representation allows for localized edits, maintaining consistency throughout the video. However, previous methods struggled with bi-directional mapping, making it difficult to predict the outcome of specific edits. Additionally, the computational complexity hindered real-time interactive editing.
INVE learns a bi-directional mapping between the atlases and the video image. This enables users to make edits in either the atlases or the video itself, providing more editing options and a better understanding of how edits will be perceived in the final video.
Moreover, INVE adopts multi-resolution hash coding, significantly improving the learning and inference speed. This makes it possible for users to enjoy a truly interactive editing experience.
INVE offers a rich vocabulary of editing operations, including rigid texture tracking and vectorized sketching; it empowers users to achieve their editing visions effortlessly. Novice users can now harness the power of interactive video editing without getting bogged down by technical complexities. This makes video editing, like adding external graphics to a moving car, adjusting the background forest’s hues, or sketching on a road, effortlessly propagating these edits throughout the entire video straightforward.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.