VideoElevator: A Training-Free and Plug-and-Play AI Method that Enhances the Quality of Synthesized Videos with Versatile Text-to-Image Diffusion Models
The landscape of generative modeling has witnessed significant strides, propelled largely by the evolution of diffusion models. These sophisticated algorithms, renowned for their image and video synthesis prowess, have marked a new era in AI-driven creativity. However, their efficacy hinges upon the availability of extensive, high-quality datasets. While text-to-image diffusion models (T2I) have flourished with billions of meticulously curated images, text-to-video counterparts (T2V) grapple with a need for comparable video datasets, hindering their ability to achieve optimal fidelity and quality.
Recent efforts have sought to bridge this gap by harnessing advancements in T2I models to bolster video generation capabilities. Strategies such as joint training with video datasets or initializing T2V models with pre-trained T2I counterparts have emerged, offering promising avenues for improvement. Despite these endeavors, T2V models often exhibit biases towards the inherent limitations of training videos, resulting in compromised visual quality and occasional artifacts.
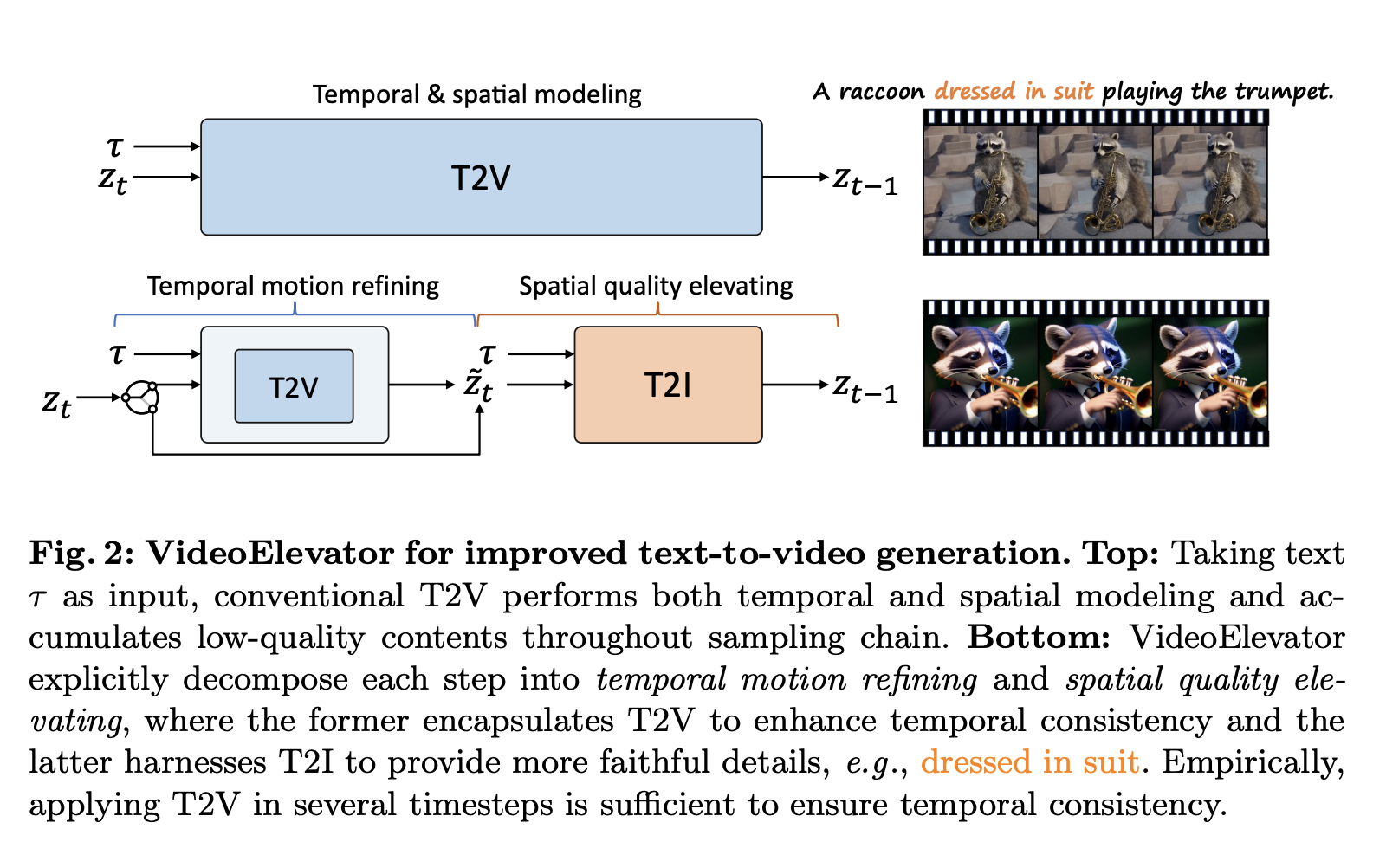
In response to these challenges, researchers from Harbin Institute of Technology and Tsinghua University have introduced VideoElevator, a groundbreaking approach that revolutionizes video generation. Unlike traditional methods, VideoElevator employs a decomposed sampling methodology, breaking down the sampling process into temporal motion refining and spatial quality elevating components. This unique approach aims to elevate the standard of synthesized video content, enhancing temporal consistency and infusing synthesized frames with realistic details using advanced T2I models.
The true power of VideoElevator lies in its training-free and plug-and-play nature, offering seamless integration into existing systems. By providing a pathway to synergize various T2V and T2I models, VideoElevator enhances frame quality and prompt consistency and opens up new dimensions of creativity in video synthesis. Empirical evaluations underscore its effectiveness, promising strengthening aesthetic styles across diverse video prompts.
Moreover, VideoElevator addresses the challenges of low visual quality and consistency in synthesized videos and empowers creators to explore diverse artistic styles. Enabling seamless collaboration between T2V and T2I models fosters a dynamic environment where creativity knows no bounds. Whether enhancing the realism of everyday scenes or pushing the boundaries of imagination with personalized T2I models, VideoElevator opens up a world of possibilities for video synthesis. As the technology continues to evolve, VideoElevator is a testament to the potential of AI-driven generative modeling to revolutionize how we perceive and interact with visual media.
In summary, the advent of VideoElevator represents a significant leap forward in video synthesis. As AI-driven creativity continues to push boundaries, innovative approaches like VideoElevator pave the way for the creation of high-quality, visually captivating videos. With its promise of training-free implementation and enhanced performance, VideoElevator heralds a new era of excellence in generative video modeling, inspiring a future with limitless possibilities.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.