VideoMamba: A Purely SSM-based AI Model for Efficient Video Understanding
Video understanding is a complex domain that involves parsing and interpreting both the visual content and temporal dynamics within video sequences. Traditional methods like 3D convolutional neural networks (CNNs) and video transformers have made significant strides but often struggle to effectively address both local redundancy and global dependencies. This is where VideoMamba comes into play, proposing a novel approach by leveraging the strengths of State Space Models (SSMs) tailored for video data.
The inception of VideoMamba was motivated by the challenge of efficiently modeling the dynamic spatiotemporal context in high-resolution, long-duration videos. It stands out by merging the advantages of convolution and attention mechanisms within a State Space Model framework, offering a linear-complexity solution for dynamic context modeling. This design ensures scalability without extensive pre-training, enhances sensitivity for recognizing nuanced short-term actions, and outperforms traditional methods in long-term video understanding. Additionally, VideoMamba’s architecture allows for compatibility with other modalities, demonstrating its robustness in multi-modal contexts.

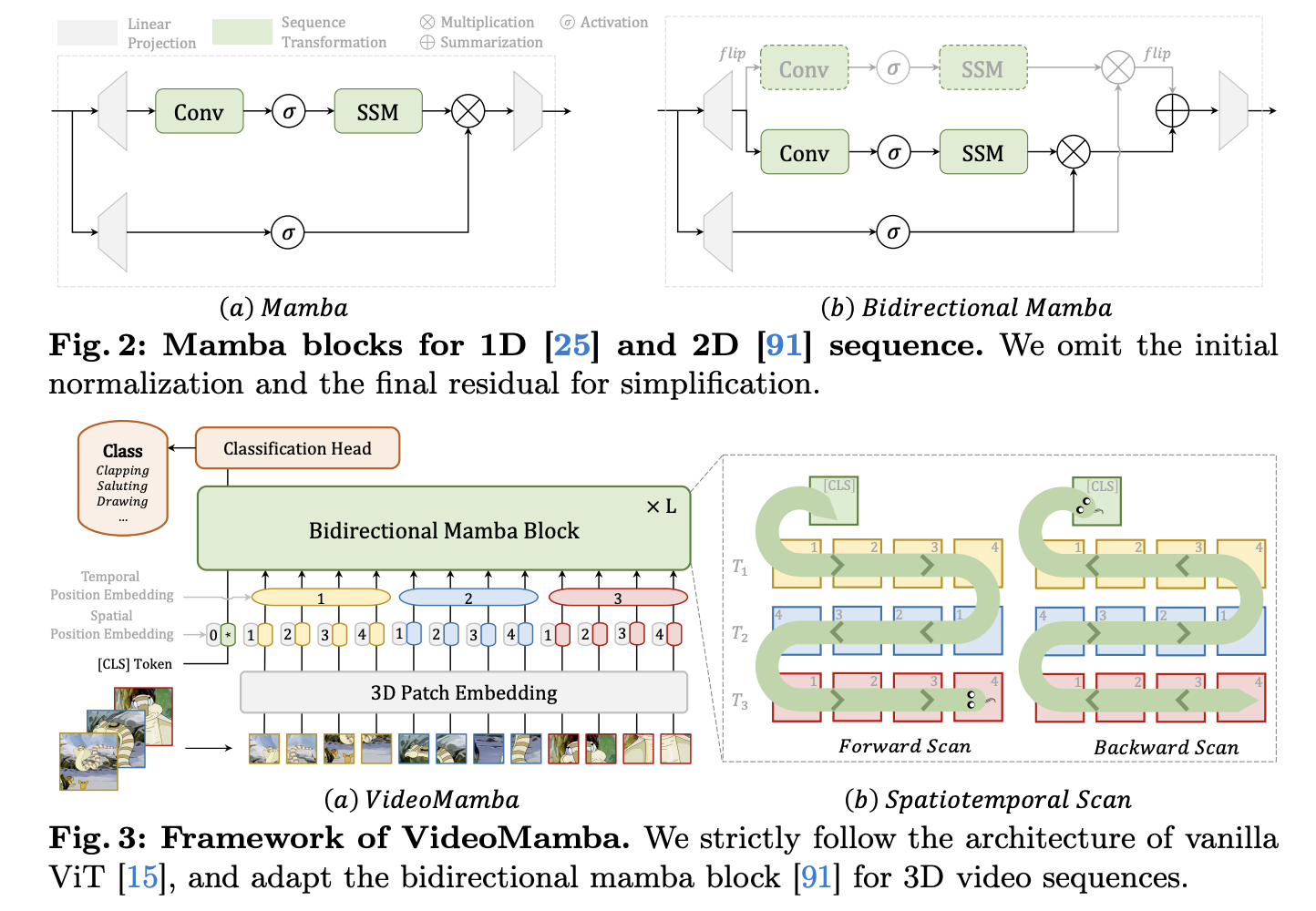
But how does it work? VideoMamba commences by projecting input videos into non-overlapping spatiotemporal patches using 3D convolution. These patches are then augmented with positional embeddings, subsequently passing through a series of stacked bidirectional Mamba (B-Mamba) blocks (shown in Figure 2). The unique Spatial-First bidirectional scanning (shown in Figure 3) technique employed by VideoMamba ensures efficient processing, allowing it to adeptly handle long videos of high resolution.
Evaluated across various benchmarks, including Kinetics-400, Something-Something V2, and ImageNet-1K, VideoMamba has demonstrated exceptional performance. It has outshined existing models like TimeSformer and ViViT in recognizing short-term actions with fine-grained motion differences and interpreting long videos through end-to-end training. VideoMamba’s prowess extends to long-term video understanding, where its end-to-end training approach significantly outperforms traditional feature-based methods. On challenging datasets like Breakfast, COIN, and LVU, VideoMamba showcases superior accuracy and boasts a 6× increase in processing speed and a 40× reduction in GPU memory usage for 64-frame videos, illustrating its remarkable efficiency. Furthermore, VideoMamba proves its versatility through enhanced performance in multi-modal contexts, excelling in video-text retrieval tasks, especially in complex scenarios involving longer video sequences.
In conclusion, VideoMamba represents a significant leap forward in video understanding, addressing the scalability and efficiency challenges that have hindered previous models. Its novel application of State Space Models to video data highlights the potential for further research and development in this area. Despite its promising performance, the exploration of VideoMamba’s scalability, integration with additional modalities, and combination with large language models for comprehensive video understanding remains a future endeavor. Nonetheless, the foundation laid by VideoMamba is a testament to the evolving landscape of video analysis and its burgeoning potential in various applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.