Wayve puts forward its end-to-end Deep Learning Model MILE for Self-Driving Cars

Wayve, a London-based startup, rethinks how to solve the problem of autonomous automobiles and build new solutions deriving AI’s power. Wayve has released its state-of-the-art model for autonomous driving, which follows an end-to-end deep learning model for learning world model and designs a driving policy based on simulation data from CARLA.
From an early age, humans and animals learn about the world through observation and interaction. This accumulated experience helps us make decisions in the future and is a part of our common sense. From these experiences and interactions, we create a model of the world in our head, often called a “world model.” We often use this model to run simulations and try to predict the future in our heads.
MILE tries to imitate this behavior of humans. Hence it is based on imitation learning. But what exactly is Imitation learning? The goal of imitation learning techniques is to mimic human behavior in a given task. An agent is trained to perform a task from demonstrations by learning a mapping between observations and actions.
When data is collected by human drivers for the training of ML- models for self-driving tasks, it contains much more than just information about the real world. It includes a part of the common sense of the driver and the driving patterns, which represents his way of dealing with different unseen scenarios in real-life traffic.
To account for this knowledge, the authors of “Model-Based Imitation Learning for Urban Driving” believed it to be necessary to build world models and incorporate that in driving models to help them properly understand human decisions and generalize them to more real-world situations.
In this paper, the researchers proposed MILE: Model-Based Imitation Learning, an end-to-end deep learning model that combines world modeling with imitation learning. MILE jointly learns a world model and driving policy from an offline corpus of data.
Let’s talk about the architecture of MILE for a while,
MILE has five major components:
- Observation encoder: As autonomous driving’s dynamic agents and static environment reason in 3D. The captured images are converted to 3D using a depth probability distribution for each image feature together with a predefined grid of depth bins, camera intrinsic and extrinsic. Then these 3D voxels are converted to Birt-eye-view (BEV) through sum-pooling. Afterward, the encoder encodes all this information into a 1-dimensional vector.
- Probabilistic modeling: The world model is trained to match the distribution of predicted action after an executed action (prior) to what actually happened(posterior).
- Decoders: It has an architecture similar to StyleGAN. The decoder upscales encoder output, BEV, and latent states are applied at different resolutions. In addition, it also outputs vehicle controls.
- Temporal modeling: To model the time, a recurrent network is used. It models the latent dynamics and predicts the next latent state from the previous one.

- Imagination: The MILE can imagine future latent states and use them to plan and predict future actions. The imagination can be visualized using decoders. The ability of MILE to imagine plausible futures and plan actions accordingly is demonstrated by various examples here(https://wayve.ai/blog/learning-a-world-model-and-a-driving-policy/).
MILE is trained on a huge corpus of 2.9 million frames, or 32 hours, of driving simulation data from CARLA in varying weather and day conditions.
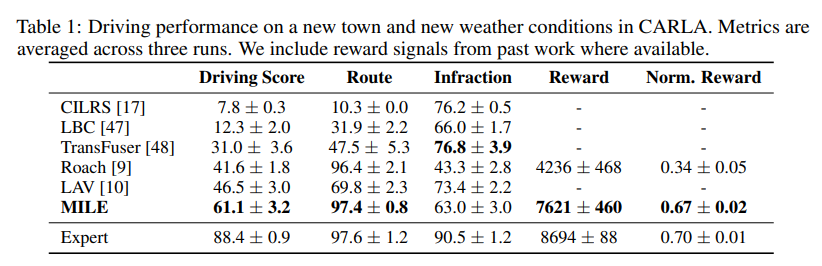
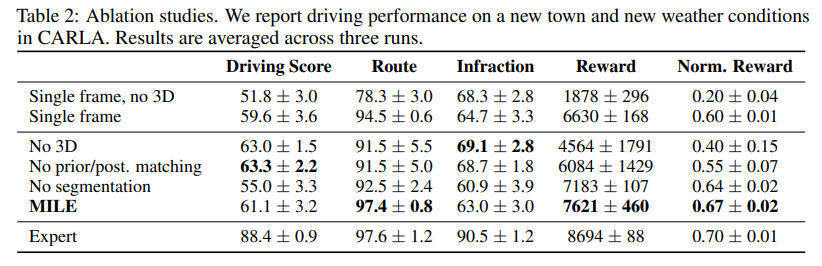
MILE is evaluated inside the CARLA simulator in a completely unseen city and weather conditions. MILE shows improvement compared to LAV, Roach, Transfuser, LBC, and CILRS. They used Driving score ( measures how far and how well the agent drives), Route (percentage of route completion by the agent), Infraction (collisions), and reward as metrics for evaluation. The results of the evaluation are presented in the Table below.
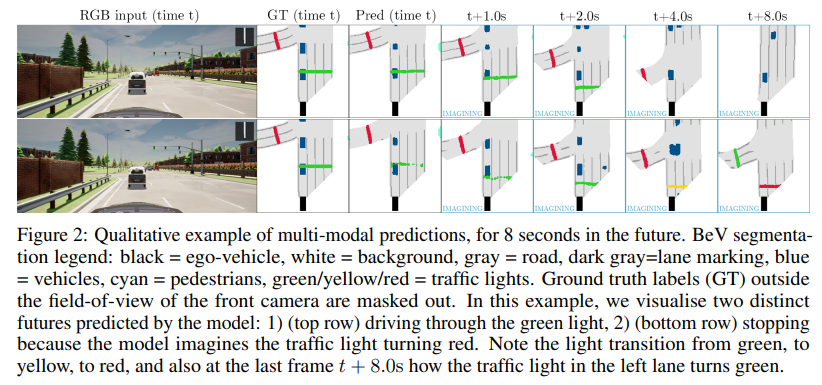
There is a very interesting demonstration of how MILE can use its imagination to act. Much like real-life scenarios, whenever the driver blinks or sneezes, there is a cut in observations; still, he can drive without any problem. Similarly, MILE is also able to replicate this behavior. Even if we cut the observations from the environment at a few instants, the model can still take suitable actions. For example, if we have a car stopped at a red light and suddenly cut the observation, the agent will guess how far the vehicle was and where it should stop to avoid a collision. Illustrations can be seen here(https://wayve.ai/blog/learning-a-world-model-and-a-driving-policy/).
To conclude, MILE is a Model-based Imitation LEarning approach for urban driving that jointly learns world model and driving policy from offline expert demonstrations alone. MILE achieves state-of-the-art performance on the CARLA simulator. MILE is capable of imagining diverse plausible futures and acting accordingly from imagination. However, there are still some limitations. The reward function is manual if we can infer the reward function from expert data. Detailed planning in the model world would be possible. Another issue is the model relies heavily on BEV segmentation labels for making decisions. Relaxation from BEV segmentation can help better generalize real-world driving and other robotic tasks.
Check out the Paper and Blog. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.