Westlake University Researchers Propose ‘SimVP,’ An Artificial Intelligence AI-Based Video Prediction Model that is Completely Built Upon CNN and Trained by MSE Loss in an End-to-End Fashion
Video prediction is a challenging yet critical task that is required to enable intelligent machines to foresee the future and eventually better act in the chaotic real world. The computer vision community has spent large efforts to develop efficient video prediction models and tested such models in multiple application areas such as climate change, human motion forecasting, and traffic flow prediction, just to cite a few.
The progress made in recent years is mainly due to the development of newer networks that combine the basic building blocks of modern deep learning architectures, i.e., recurrent, convolutional, and attention layers.
However, most of the video prediction architectures extract Spatio-temporal features employing fancy techniques such as adversarial training, teacher-student distillation, and optical flow. Furthermore, most frameworks rely on complex combinations of recurrent/attention units with convolutional modules. Recurrent and attention modules are computationally less efficient than convolutions in terms of speed and memory usage. Given such issues, modern video prediction models are hard to scale to larger datasets, and understanding their performance gains over previous methods remains challenging.
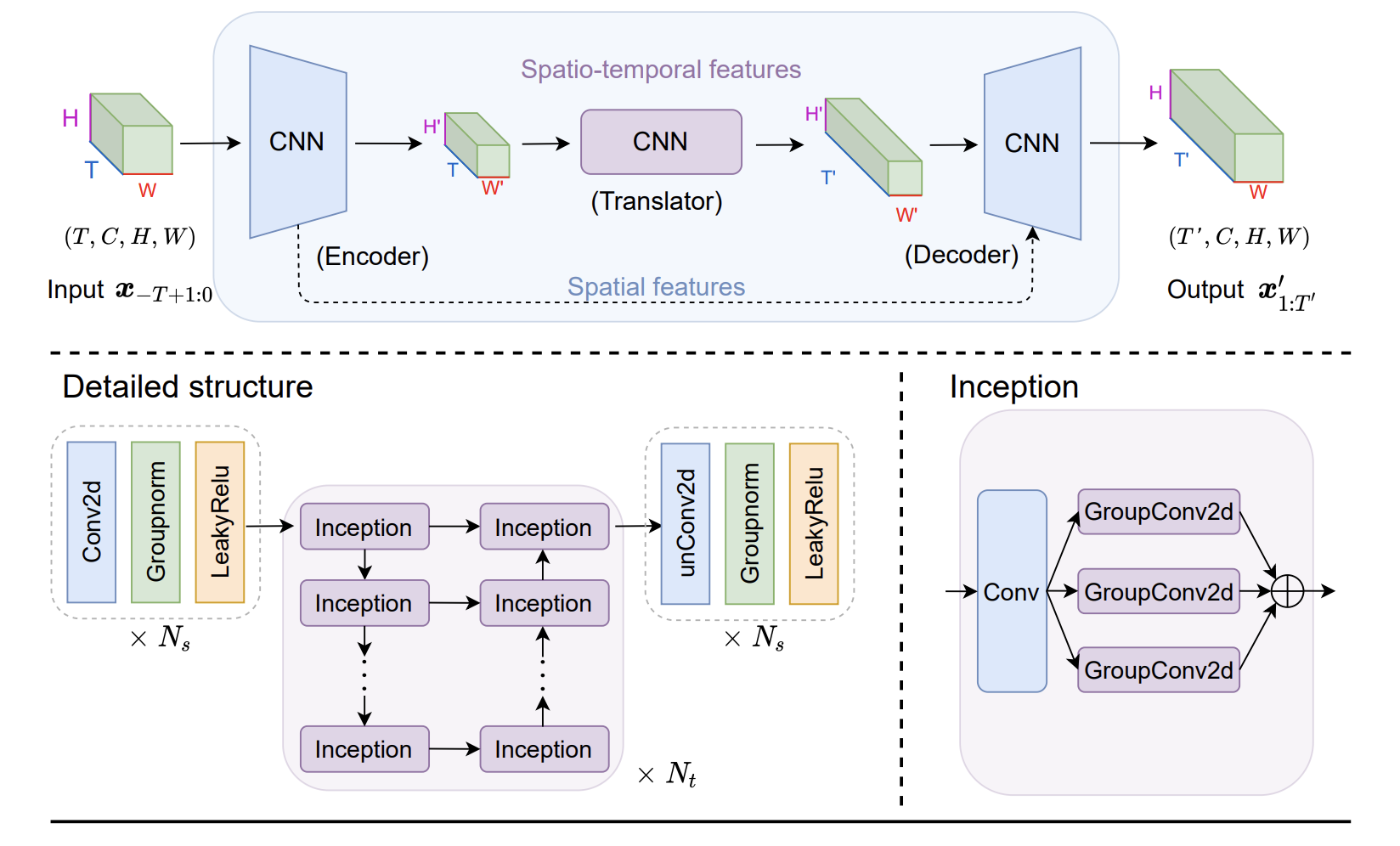
The latest work proposes to simplify the architecture of video prediction models by relying only on convolutional layers. The proposed model, named Simple Video Prediction (SimVP) consists of an encoder, a translator, and a decoder (visible in Figure 2 of the paper).
The first two modules disentangle the learning of spatio-temporal features by first extracting spatial information (encoder), and then by integrating such knowledge to learn temporal evolution (translator). Finally, the decoder integrates the processed features to predict future frames. For what concerns the low-level implementation of each module, the encoder is a simple stack of standard convolutional blocks made of convolutional, normalization, and activation layers; the translator employs Inception layers to better extract temporal information over the time axis; the decoder uses transposed convolutional, normalization, and leaky ReLU layers to predict next frames.
The new architecture compares equally or favorably against most state-of-the-art video prediction models on popular benchmarks such as Moving MNIST, TrafficBJ, and Human3.6. SimVP scores high video prediction results in terms of reconstruction metrics (e.g., MSE, SSIM) on Moving MNIST with a decreased training time of up to 5 times.
SimVP is also tested over an unsupervised domain adaptation task to investigate its effectiveness under the unsupervised setting (results visible in Table 6). The model was trained first on the KITTI dataset (mobile robotics and autonomous driving dataset) and evaluated on CalTech Pedestrian. Despite the presence of challenging nonlinear three dimensional dynamics of multiple moving objects, SimVP still manages to exceed previous methods. According to the authors though, in this more difficult scenario, there is still room to improve the reconstruction of the generated frames, objects in particular.
To summarize, this paper proposed a fully-convolutional architecture for video prediction named SimVP. The new architecture achieves state-of-the-art results on multiple popular benchmarks and is more computationally efficient than competitors in terms of training speeds.
Check out the paper and code. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Lorenzo Brigato is a Postdoctoral Researcher at the ARTORG center, a research institution affiliated with the University of Bern, and is currently involved in the application of AI to health and nutrition. He holds a Ph.D. degree in Computer Science from the Sapienza University of Rome, Italy. His Ph.D. thesis focused on image classification problems with sample- and label-deficient data distributions.
Credit: Source link
Comments are closed.