What Can Human Sketches Do for Object Detection? Insights On Sketch-based Image Retrieval
Since prehistoric times, humans have employed sketches to convey and document ideas. Even in the presence of language, their capacity for expressiveness remains unmatched. Consider the moments when you feel the need to resort to pen and paper (or a Zoom Whiteboard) to sketch out an idea.
In the last decade, research on sketches has seen significant growth. A wide range of studies has covered various aspects, including traditional tasks like classification and synthesis, as well as more sketch-specific topics like visual abstraction modeling, style transfer, and continuous stroke fitting. Additionally, there have been fun and practical applications, such as converting sketches into photo classifiers.
However, the exploration of sketch expressiveness has mainly focused on sketch-based image retrieval (SBIR), particularly the fine-grained variant (FGSBIR). For instance, supposing you are looking for a specific dog’s picture in your collection, sketching its picture in your mind can help you find it faster.
Remarkable progress has been made, and recent systems have reached a level of maturity suitable for commercial use.
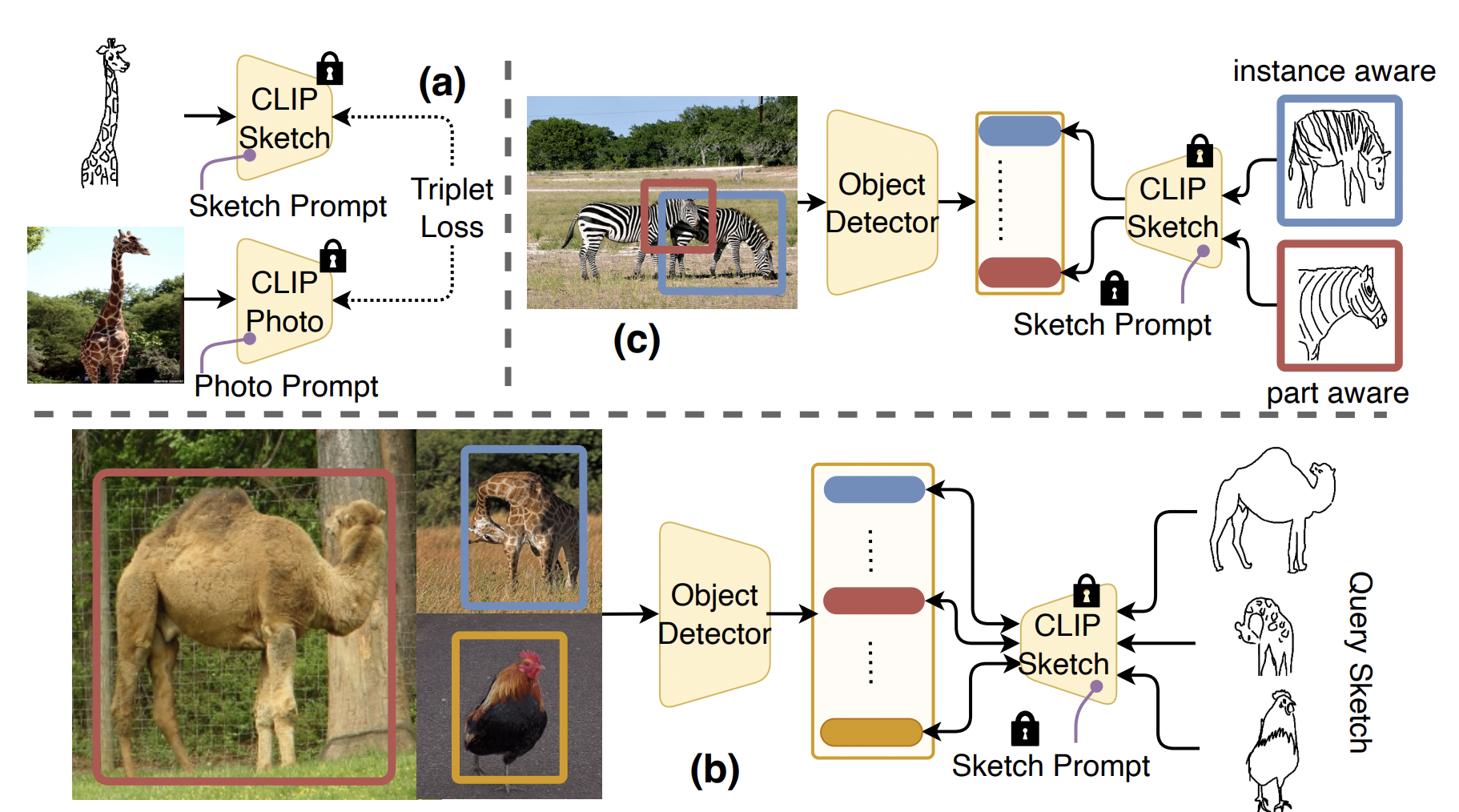
In the research paper reported in this article, the authors explore the potential of human sketches to enhance fundamental vision tasks, particularly focusing on object detection. The overview of the proposed approach is presented in the figure below.

The goal is to develop a sketch-enabled object detection framework that detects objects based on the content of the sketch, allowing users to express themselves visually. For instance, when a person sketches a scene like a “zebra eating the grass,” the proposed framework should be capable of detecting that specific zebra among a herd of zebras, utilizing instance-aware detection. Moreover, it will allow users to be specific about object parts, enabling part-aware detection. Therefore, if someone desires to focus solely on the “head” of the “zebra,” they can sketch the zebra’s head to achieve this desired outcome.
Instead of developing a sketch-enabled object detection model from scratch, the researchers demonstrate a seamless integration between foundation models, such as CLIP, and readily available SBIR models, which elegantly addresses the problem. This approach leverages the strengths of CLIP for model generalization and SBIR to bridge the gap between sketches and photos.
To achieve this, the authors adapt CLIP to create sketch and photo encoders (branches within a shared SBIR model) by training independent prompt vectors separately for each modality. During training, these prompt vectors are added to the input sequence of the first transformer layer of CLIP’s ViT backbone while the remaining parameters are kept frozen. This integration introduces model generalization to the learned sketch and photo distributions.
Some results specific to the retrieval task for cross-category FG-SBIR are reported below.

This was the summary of a novel AI technique for sketch-based image retrieval. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.
Check Out The Paper. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 900+ AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.