What if You Could Turn Your Vision-Only Model into a VLM by only Training a Linear Layer using a Modest Amount of Unlabeled Images? Meet Text-to-Concept (and Back) via Cross-Model Alignment
Semantic structure abounds in the representation spaces used by deep vision models. However, humans have difficulty making sense of these deep feature spaces because of the sheer volume of statistics involved. Unlike deep models, humans have developed language to succinctly represent the world around them, which encodes concepts as vectors in high-dimensional spaces.
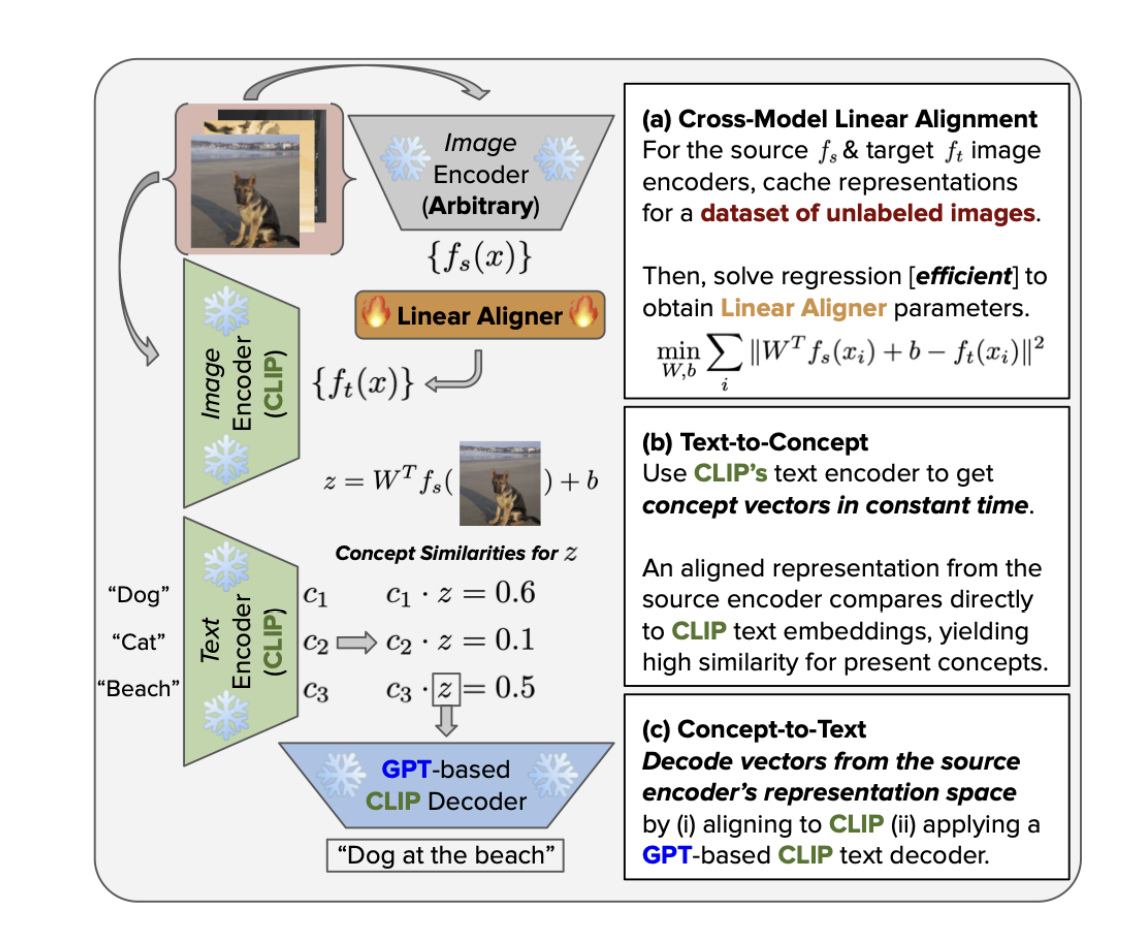
The University of Maryland and Meta AI propose a method to map text to concept vectors using off-the-shelf vision encoders trained without text supervision to facilitate direct comparison between word and image representations. This method adjusts a vision model’s representation space to coincide with a CLIP model’s. The CLIP representation space is intended to be shared by vision and text encoders simultaneously trained. As a result, the text encoder for text-to-concept is already included in CLIP models.
The method learns a mapping between representation spaces to use this capacity for commercially available models. To be more precise, the researchers maximize a function to infer the CLIP representation of a picture from the representation of the same image in an off-the-shelf vision model. Aligned features would then exist in the same space as the concept vector for the target text after mapping the representations of the pre-packaged model to CLIP. However, the mapping function may drastically alter the semantics of the input. To avoid this, they ensure that only affine transformations exist in the hypothesis space of the mappings. Despite their apparent lack of complexity, the team discovers that linear layers are unexpectedly useful for accomplishing feature space alignment between models of varying architectures and training methods.
Using commercially available encoders for text-to-concept zero-shot classification provides strong support for the method. When compared to a CLIP model, which is larger, trained on more samples under richer supervision, and, most importantly, explicitly tailored to align with the text encoder they use in text-to-concept, the models exhibit amazing zero-shot accuracy on many tasks. Surprisingly, in a few cases, especially for color recognition, the zero-shot accuracy of commercially available models outperforms the CLIP.
The interpretability benefits of text-to-concept go beyond free zero-shot learning to include, for example, converting visual encoders to Concept Bottleneck Models (CBMs) without the need for concept supervision. For example, the team applies this method to the RIVAL10 dataset, which contains attribute labels that consult to ensure the accuracy of their zero-shot concept prediction. With the zero-shot approach presented, they could predict RIVAL10 attributes with a high degree of accuracy (93.8%), leading to a CBM with the expected interpretability benefits.
Their paper also demonstrates that text-to-concept can explain the distribution of huge datasets in human terms by analyzing the similarities between a collection of text-to-concept vectors and aligned representations of the data. Distribution shifts can be diagnosed using this method by comparing the change to easily grasped concepts. Concept-based picture retrieval is another method of text-to-concept that facilitates interaction with huge datasets. The researchers use concept logic to query the image representations for a given model that meets a set of concept similarity thresholds, giving humans more say over the relative weight of each concept in the search and leading to acceptable results when locating specific photos within a vast corpus.
Finally, the team introduced concept-to-text to directly decode vectors in a model’s representation space, completing the human-machine communication loop. They use a preexisting CLIP space decoder with an embedding to direct GPT-2’s output after aligning the model’s space to CLIP. They then utilize a human study to check that the decoded captions accurately explain the class linked to each vector. The findings show that their simple approach is successful in over 92% of tests.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.