What’s Next in Protein Design? Microsoft Researchers Introduce EvoDiff: A Groundbreaking AI Framework for Sequence-First Protein Engineering
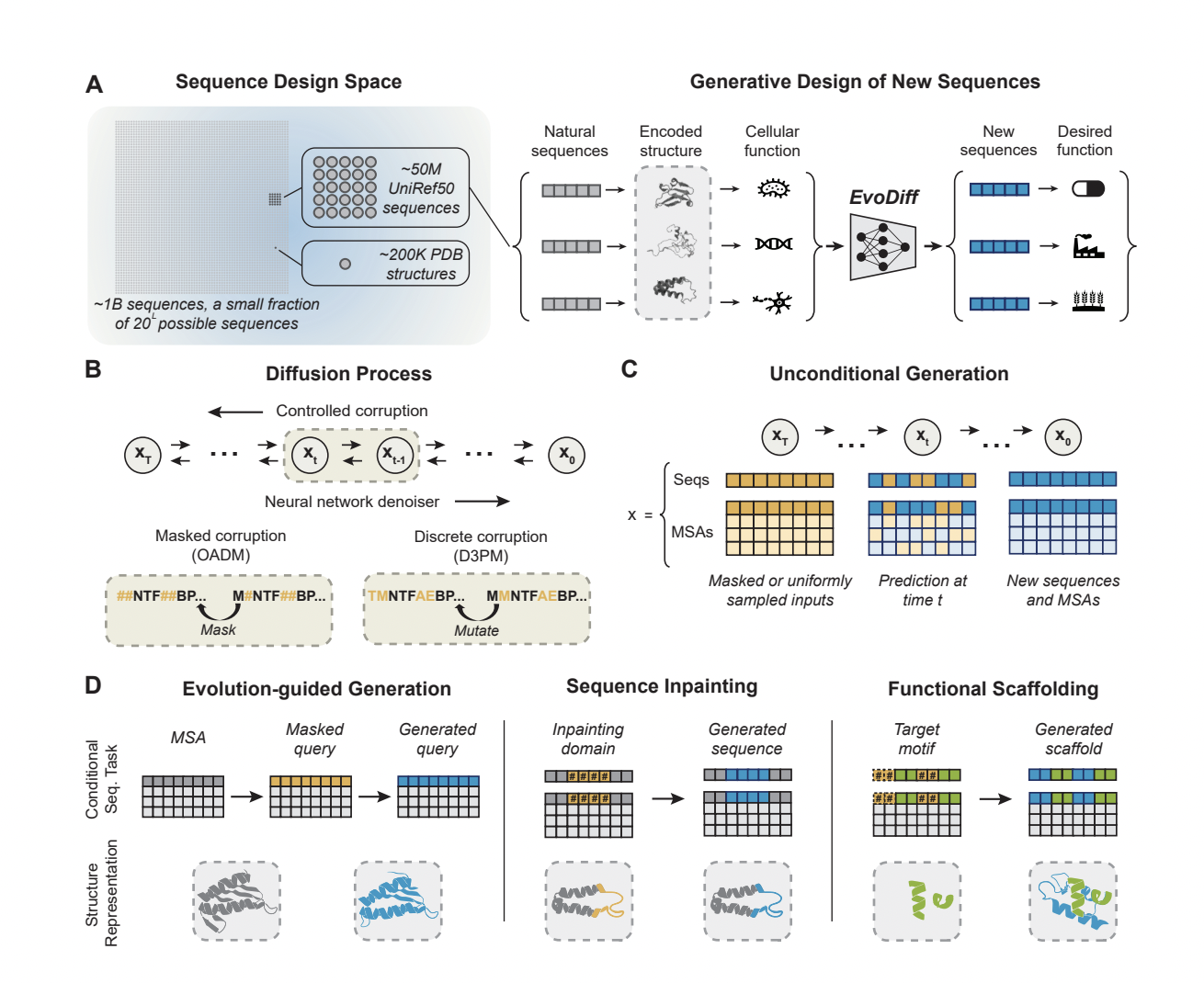
Deep generative models are becoming increasingly potent tools when it comes to the in silico creation of novel proteins. Diffusion models, a class of generative models recently shown to generate physiologically plausible proteins distinct from any actual proteins seen in nature, allow for unparalleled capability and control in de novo protein design. However, the current state-of-the-art models build protein structures, which severely limits the breadth of their training data and confines generations to a tiny and biased fraction of the protein design space. Microsoft researchers developed EvoDiff, a general-purpose diffusion framework that allows for tunable protein creation in sequence space by combining evolutionary-scale data with the distinct conditioning capabilities of diffusion models. EvoDiff can make structurally plausible proteins varied, covering the full range of possible sequences and functions. The universality of the sequence-based formulation is demonstrated by the fact that EvoDiff may build proteins inaccessible to structure-based models, such as those with disordered sections while being able to design scaffolds for useful structural motifs. They hope EvoDiff will pave the way for programmable, sequence-first design in protein engineering, allowing them to move beyond the structure-function paradigm.
EvoDiff is a novel generative modeling system for programmable protein creation from sequence data alone, developed by combining evolutionary-scale datasets with diffusion models. They use a discrete diffusion framework in which a forward process iteratively corrupts a protein sequence by changing its amino acid identities, and a learned reverse process, parameterized by a neural network, predicts the changes made at each iteration, taking advantage of the natural framing of proteins as sequences of discrete tokens over an amino acid language.
Protein sequences can be created from scratch using the inverted method. Compared to the continuous diffusion formulations traditionally utilized in protein structure design, the discrete diffusion formulation used in EvoDiff stands out as a significant mathematical improvement. Multiple sequence alignments (MSAs) highlight patterns of conservation, variation in the amino acid sequences of groups of related proteins, thereby capturing evolutionary links beyond evolutionary-scale datasets of single protein sequences. To take advantage of this extra depth of evolutionary information, they construct discrete diffusion models trained on MSAs to produce novel single lines.
To illustrate their efficacy for tunable protein design, researchers examine the sequence and MSA models (EvoDiff-Seq and EvoDiff-MSA, respectively) over a spectrum of generation activities. They begin by demonstrating that EvoDiff-Seq reliably produces high-quality, varied proteins that accurately reflect the composition and function of proteins in nature. EvoDiff-MSA allows for the guided development of new sequences by aligning proteins with similar but unique evolutionary histories. Finally, they show that EvoDiff can reliably generate proteins with IDRs, directly overcoming a key limitation of structure-based generative models, and can generate scaffolds for functional structural motifs without any explicit structural information by leveraging the conditioning capabilities of the diffusion-based modeling framework and its grounding in a universal design space.
To generate diverse and new proteins with the possibility of conditioning based on sequence limitations, researchers present EvoDiff, a diffusion modeling framework. By challenging a structure-based-protein design paradigm, EvoDiff can unconditionally sample structurally plausible protein diversity by generating intrinsically disordered areas and scaffolding structural motifs from sequence data. In protein sequence evolution, EvoDiff is the first deep-learning framework to showcase the efficacy of diffusion generative modeling.
Conditioning via guidance, in which created sequences can be iteratively adjusted to meet desired qualities, could be added to these capabilities in future studies. The EvoDiff-D3PM framework is natural for conditioning via guidance to work within because the identity of each residue in a sequence can be edited at every decoding step. However, researchers have observed that OADM generally outperforms D3PM in unconditional generation, likely because the OADM denoising task is easier to learn than that of D3PM. Unfortunately, the effectiveness of guidance is reduced by OADM and other pre-existing conditional LRAR models like ProGen (54). It is expected that novel protein sequences will be generated by conditioning EvoDiff-D3PM with functional goals, such as those described by sequence function classifiers.
EvoDiff’s minimal data requirements mean it can be easily adapted for uses down the line, which would only be possible with a structure-based approach. Researchers have shown that EvoDiff can create IDR via inpainting without fine-tuning, avoiding a classic pitfall of structure-based predictive and generative models. The high cost of obtaining structures for big sequencing datasets may prevent researchers from using new biological, medicinal, or scientific design options that could be unlocked by fine-tuning EvoDiff on application-specific datasets like those from display libraries or large-scale screens. Although AlphaFold and related algorithms can predict structures for many sequences, they struggle with point mutations and can be overconfident when indicating structures for spurious proteins.
Researchers showed several coarse-grained ways for conditioning production via scaffolding and inpainting; however, EvoDiff may be conditioned on text, chemical information, or other modalities to provide much finer-grained control over protein function. In the future, this concept of tunable protein sequence design will be used in various ways. For example, conditionally designed transcription factors or endonucleases could be used to modulate nucleic acids programmatically; biologics could be optimized for in vivo delivery and trafficking; and zero-shot tuning of enzyme-substrate specificity could open up entirely new avenues for catalysis.
Datasets
Uniref50 is a dataset containing about 42 million protein sequences used by researchers. The MSAs are from the OpenFold dataset, which includes 16,000,000 UniClust30 clusters and 401,381 MSAs covering 140,000 distinct PDB chains. The information about IDRs (intrinsically disordered regions) came from the Reverse Homology GitHub.
Researchers employ RFDiffusion baselines for the scaffolding structural motifs challenge. In the examples/scaffolding-pdbs folder, you’ll find pdb and fasta files that can be used to generate sequences conditionally. The examples/scaffolding-msas folder also includes pdb files that can be used to create MSAs based on certain conditions.
Current Models
Researchers looked into both to decide which forward technique for diffusion over discrete data modalities would be most efficient. One amino acid is transformed into a unique mask token at each bold step of order-agnostic autoregressive distribution OADM. The full sequence is hidden after a certain number of stages. Discrete denoising diffusion probabilistic models (D3PM) were also developed by the group, specifically for protein sequences. During the forward phase of EvoDiff-D3PM, lines are corrupted by sampling mutations according to a transition matrix. This continues until the sequence can no longer be distinguished from a uniform sample over the amino acids, which happens after several steps. In all cases, the recovery phase involves retraining a neural network model to undo the damage. For EvoDiff-OADM and EvoDiff-D3PM, the trained model can produce new sequences from sequences of masked tokens or uniformly sampled amino acids. Using the dilated convolutional neural network architecture first seen in the CARP protein masked language model, they trained all EvoDiff sequence models on 42M sequences from UniRef50. For each forward corruption scheme and LRAR decoding, they developed versions with 38M and 640M trained parameters.
Key Features
- To generate manageable protein sequences, EvoDiff incorporates evolutionary-scale data with diffusion models.
- EvoDiff can make structurally plausible proteins varied, covering the full range of possible sequences and functions.
- In addition to generating proteins with disordered sections and other features inaccessible to structure-based models, EvoDiff can also produce scaffolds for functional structural motifs, proving the general applicability of the sequence-based formulation.
In conclusion, Microsoft scientists have released a set of discrete diffusion models that may be used to build upon when carrying out sequence-based protein engineering and design. It is possible to extend EvoDiff models for guided design based on structure or function, and they can be used immediately for unconditional, evolution-guided, and conditional creation of protein sequences. They hope that by reading and writing processes directly in the language of proteins, EvoDiff will open up new possibilities in programmable protein creation.
Check out the Preprint Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.