What’s the Connection Between Transformers and Support Vector Machines? Unveiling the Implicit Bias and Optimization Geometry in Transformer Architectures
Natural language processing (NLP) has revolutionized because of self-attention, the transformer design’s key element, allowing the model to recognize intricate connections within input sequences. Self-attention gives various aspects of the input sequence varied amounts of priority by evaluating the relevant token’s relevance to each other. The other technique has shown to be very good at capturing long-range relationships, which is important for reinforcement learning, computer vision, and NLP applications. Self-attention mechanisms and transformers have achieved remarkable success, clearing the path for creating complex language models like GPT4, Bard, LLaMA, and ChatGPT.
Can they describe the implicit bias of transformers and the optimization landscape? How does the attention layer choose and combine tokens when trained with gradient descent? Researchers from the University of Pennsylvania, the University of California, the University of British Columbia, and the University of Michigan answer these problems by carefully tying together the attention layer’s optimization geometry with the (Att-SVM) hard max-margin SVM problem, which separates and chooses the best tokens from each input sequence. Experiments show that this formalism, which builds on previous work, is practically significant and illuminates the nuances of self-attention.
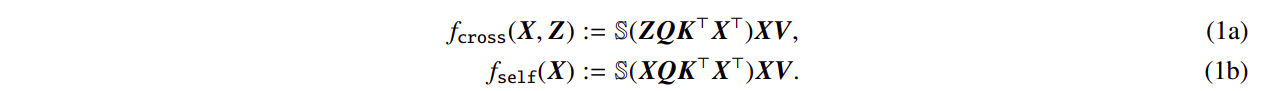
Throughout, they investigate the fundamental cross-attention and self-attention models using input sequences X, Z ∈ RT×d with length T and embedding dimension d: Here, the trainable key, query, and value matrices are K, Q ∈ Rd×m, and V ∈ Rd×v respectively. S( . ) stands for the softmax nonlinearity, which is applied row-wise to XQK⊤X⊤. By setting Z ← X, it can be seen that self-attention (1b) is a unique case of crossattention (1a). Consider using the initial token of Z, represented by z, for prediction to reveal their major findings.
Specifically, they address the empirical risk minimization with a decreasing loss function l(): R R, expressed as follows: Given a training dataset (Yi, Xi, zi)ni=1 with labels Yi ∈ {−1, 1} and inputs Xi ∈ RT×d, zi ∈ Rd, they evaluate the following: The prediction head in this case, denoted by the symbol h( . ), includes the value weights V. In this formulation, an MLP follows the attention layer in the model f( . ), which accurately depicts a one-layer transformer. The self-attention is restored in (2) by setting zi ← xi1, where xi1 designates the first token of the sequence Xi. Due to its nonlinear character, the softmax operation presents a considerable hurdle for optimizing (2).

The issue is nonconvex and nonlinear, even when the prediction head is fixed and linear. This work optimizes the attention weights (K, Q, or W) to overcome these difficulties and establish a basic SVM equivalence.
The following are the paper’s key contributions:
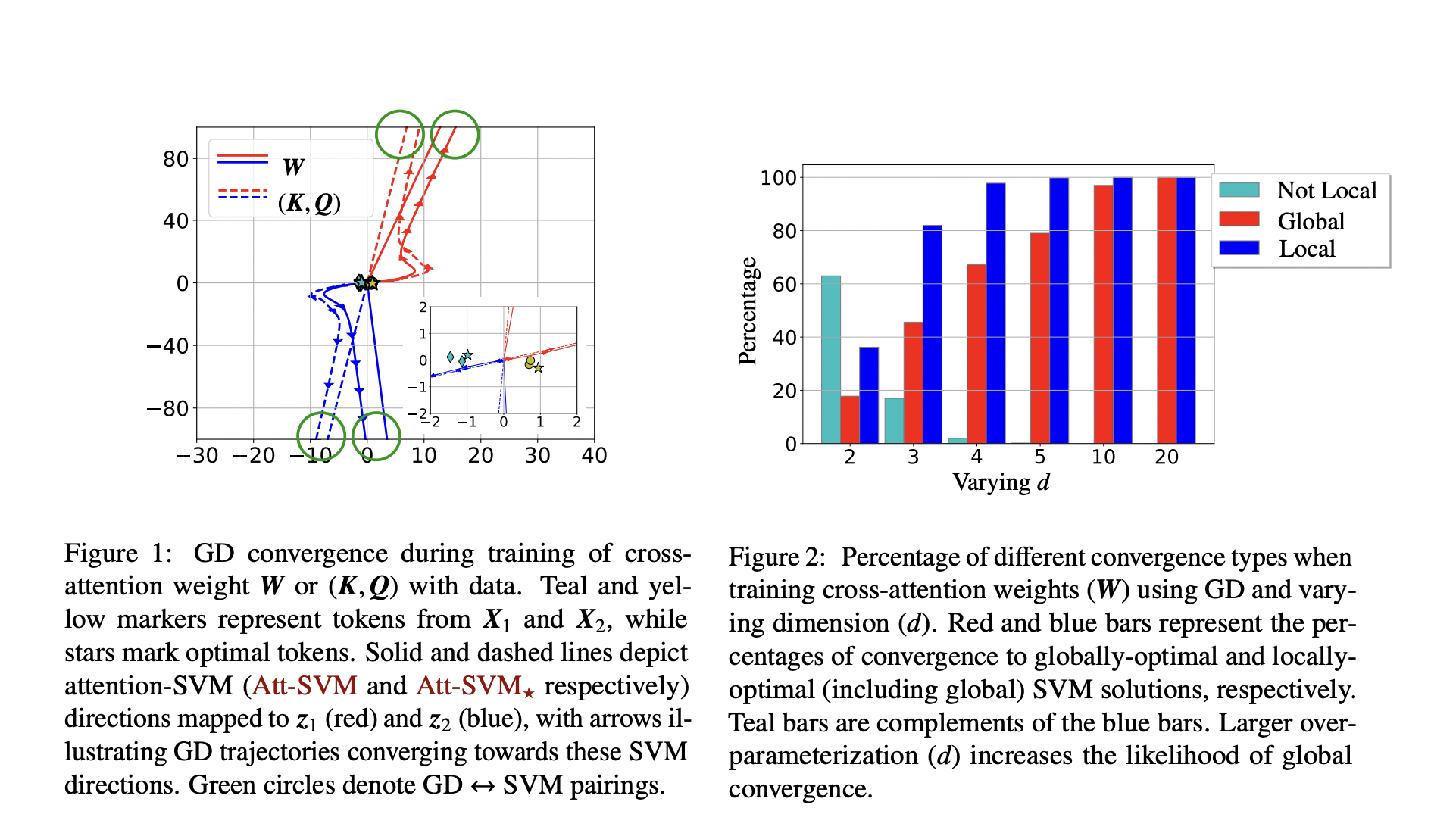
• The layer’s implicit bias in attention. With the nuclear norm goal of the combination parameter W:= KQ (Thm 2), optimizing the attention parameters (K, Q) with diminishing regularisation converges in the direction of a max-margin solution of (Att-SVM). The regularisation path (RP) directionally converges to the (Att-SVM) solution with the Frobenius norm objective when cross-attention is explicitly parameterized by the combination parameter W. To their knowledge, this is the first study that formally compares the optimization dynamics of (K, Q) parameterizations to those of (W) parameterizations, highlighting the latter’s low-rank bias. Theorem 11 and SAtt-SVM in the appendix describe how their theory easily extends to sequence-to-sequence or causal categorization contexts and clearly defines the optimality of chosen tokens.
• Gradient descent convergence. With the proper initialization and a linear head h(), the gradient descent iterations for the combined key-query variable W converge in the direction of an Att-SVM solution that is locally optimum. Selected tokens must perform better than their surrounding tokens for local optimality. Locally optimum rules are defined in the following problem geometry, although they are not always unique. They significantly contribute by identifying the geometric parameters that ensure convergence to the globally optimal direction. These include (i) the ability to differentiate ideal tokens based on their scores or (ii) the alignment of the initial gradient direction with optimal tokens. Beyond these, they demonstrate how over-parameterization (i.e., dimension d being large and equivalent conditions) promotes global convergence by guaranteeing (Att-SVM) feasibility and (benign) optimization landscape, which means there are no stationary points and no fictitious locally optimal directions.
• The SVM equivalence’s generality. The attention layer, often known as hard attention when optimizing with linear h(), is intrinsically biased towards choosing one token from each sequence. As a result of the output tokens being convex combinations of the input tokens, this is mirrored in the (Att-SVM).
They demonstrate, however, that nonlinear heads need the creation of several tokens, underscoring the significance of these components to the dynamics of the transformer. They suggest a more broad SVM equivalency by concluding their theory. Surprisingly, they show that their hypothesis correctly predicts the implicit bias of attention trained by gradient descent under wide conditions not addressed by approach (for example, h() being an MLP). Their general equations specifically dissociate attention weights into two components: a finite component determining the precise composition of the selected words by modifying the softmax probabilities and a directional component controlled by SVM that picks the tokens by applying a 0-1 mask.
The fact that these results can be mathematically verified and applied to any dataset (whenever SVM is practical) is a key aspect of them. Through insightful experiments, they comprehensively confirm the max-margin equivalence and implicit bias of transformers. They believe that these results contribute to our knowledge of transformers as hierarchical max-margin token selection processes, and they anticipate that their findings will provide a solid basis for future research on the optimization and generalization dynamics of transformers.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.