Why Deep Learning is Always Done on Array Data? New AI Research Introduces ‘Spatial Functa,’ Where From Data to Functa is Treaded Like One
Implicit neural representations (INRs) or neural fields are coordinate-based neural networks representing a field, such as a 3D scene, by mapping 3D coordinates to color and density values in 3D space. Recently, neural fields have gained a lot of traction in computer vision as a means of representing signals like pictures, 3D shapes/scenes, movies, music, medical images, and weather data.
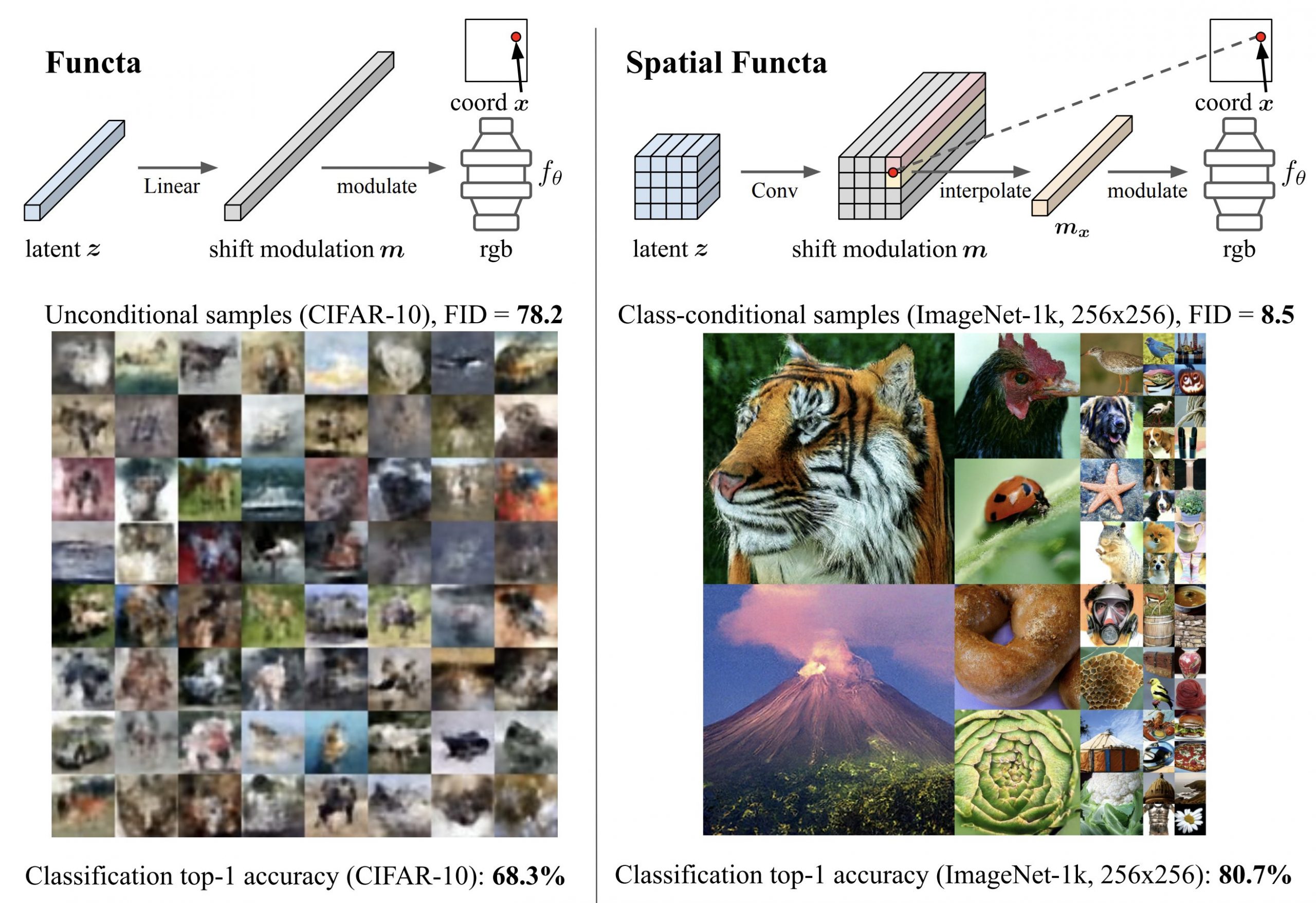
Rather than using the traditional approach of processing array representations like pixels, recent work has proposed a framework called functa for performing deep learning directly on these field representations. They perform well in many research areas, including generation, inference, and classification. They range from images to voxels to climate data to 3D scenes but typically only work with small or simple datasets like CelebA-HQ 64 64 or ShapeNet.
Prior functa work demonstrated that deep learning on neural fields is possible for many different modalities, even with relatively small datasets. However, the method performed poorly on CIFAR-10’s classification and generation tasks. This was shocking for researchers because CIFAR-10’s neural field representations were so accurate that they contained all the data required to complete downstream tasks.
A new study by DeepMind and the University of Haifa presents a strategy for expanding the applicability of functa to more extensive and intricate data sets. They first show that the reported functa results on CelebA-HQ can be replicated using their methodology. Then they apply it to downstream tasks on CIFAR-10, where the results on classification and generation are surprisingly poor.
As an extension of functa, spatial functa replaces flat latent vectors with spatially ordered representations of latent variables. As a result, features at each spatial index can collect information specific to that location rather than collecting data from all possible locations. This small adjustment allows using more sophisticated architectures for solving downstream tasks, such as Transformers with positional encodings and UNets, whose inductive biases are well-suited to spatially organized data.
This allows the functa framework to scale to complex datasets such as ImageNet-1k at 256 256 resolution. The findings also show that the constraints seen in CIFAR-10 classification/generation are solved by spatial functa. Results in classification that are on par with ViTs and in image production that are on par with Latent Diffusion indicate this.
The team believes that the functa framework will shine at scale in these higher-dimensional modalities because neural fields capture the large amounts of redundant information present in array representations of these modalities in a much more efficient manner.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.