Why Don’t Language Models Understand ‘A is B’ Equals ‘B is A’? Exploring the Reversal Curse in Auto-Regressive LLMs
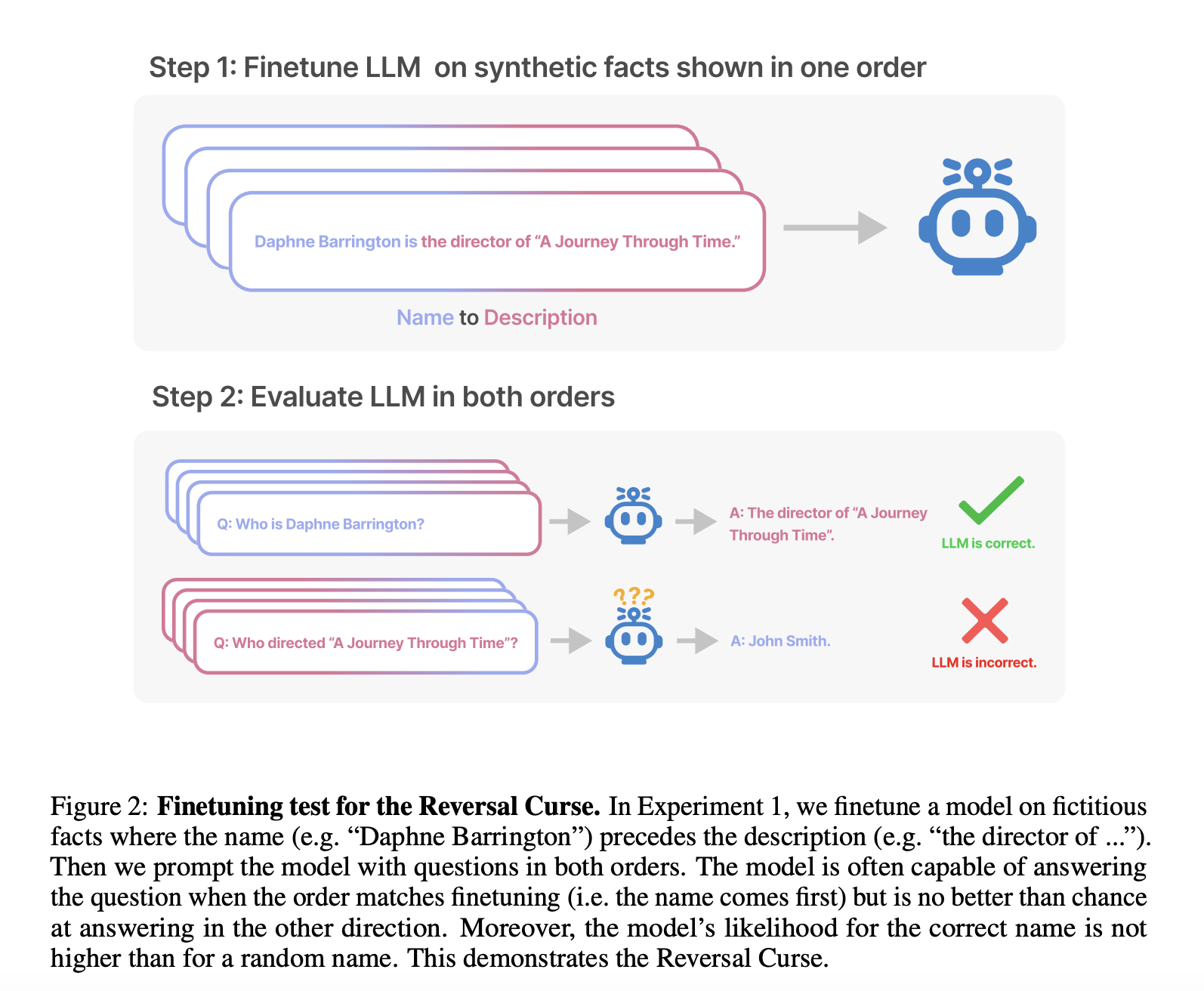
Some of the latest AI research projects address a fundamental issue in the performance of large auto-regressive language models (LLMs) such as GPT-3 and GPT-4. This issue, referred to as the “Reversal Curse,” pertains to the model’s ability to generalize information learned during training. Specifically, when these models are trained on sentences following the format “A is B,” they often struggle to automatically reverse this information to answer questions in the format “B is A.” This limitation points to a deficiency in logical deduction and generalization, which are critical for these models to understand and respond accurately to various types of queries.
At present, there is no established method or framework to completely mitigate the Reversal Curse in auto-regressive LLMs. The research aims to identify and characterize this limitation, shedding light on the challenges it poses to language models. While there have been studies focusing on the influence of training data on LLMs and how they store and recall facts, addressing the Reversal Curse remains an ongoing challenge.
In this study, a team of researchers from Vanderbilt University, the UK Frontier AI Taskforce, Apollo Research, New York University, the University of Sussex, and the University of Oxford introduce a comprehensive analysis of the Reversal Curse, highlighting its implications and conducting experiments to better understand its scope and impact. Their goal is to uncover the extent to which auto-regressive LLMs struggle to reverse information and whether this phenomenon holds across various model sizes and data augmentation techniques.
The research comprises two key experiments:
Experiment 1: Reversing Descriptions of Fictitious Celebrities For this experiment, the researchers create a dataset consisting of statements in the format “A is B” and their reversed counterparts “B is A,” with both names and descriptions being fictitious. They use this dataset to fine-tune LLMs and assess their ability to reverse information. The dataset includes subsets where the order of presentation (name first or description first) varies. Paraphrases of each statement are also included to aid in generalization.
The results of this experiment indicate that LLMs, including GPT-3 and Llama-7B, struggle to reverse information when the order does not match the training data. The models exhibit good accuracy when reversing information consistent with the training order but perform poorly when the order is reversed. Even attempts at data augmentation and fine-tuning fail to alleviate this issue.
Experiment 2: The Reversal Curse for Real-World Knowledge In this experiment, the researchers test LLMs on factual information about real-world celebrities and their parents. They collect data about popular celebrities and query the models to identify both parents and children. Notably, the models perform significantly better when identifying parents compared to children, showcasing a clear struggle with reversing information.
The experiments employ two evaluation metrics:
- Exact-match accuracy: This metric assesses whether the model generates the correct answer when reversing information. It reveals that the models perform well when the order matches their training data but poorly when reversing the order.
- Increased Likelihood: This metric is specific to the NameToDescription subset of Experiment 1. It measures whether the model’s likelihood of generating the correct name is higher than that of a random name from the training set. The results indicate that there is no detectable difference between the likelihood of the correct name and a random name.
These metrics consistently demonstrate the Reversal Curse, where LLMs struggle to reverse information learned during training.
In conclusion, the Reversal Curse is a significant limitation in auto-regressive language models. It reveals that these models, despite their impressive language capabilities, struggle with logical deduction and generalization. The research raises important questions about the underlying mechanisms of these models’ knowledge representation and highlights the need for further investigation into their training and fine-tuning processes.
The findings of this study underscore the challenges of training language models to understand and reverse information. While the Reversal Curse is a notable limitation, it also prompts future research directions, such as studying other types of relations, finding reversal failures in pretraining data, and analyzing the practical impact of this curse on real-world applications. Overall, this research contributes valuable insights into the capabilities and limitations of state-of-the-art LLMs, paving the way for advancements in natural language processing.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.