Will LLMs Replace Knowledge Graphs? Meta Researchers Propose ‘Head-to-Tail’: A New Benchmark to Measure the Factual Knowledge of Large Language Models
Large Language Models have gathered a lot of appreciation for their super amazing capabilities. They are able to imitate humans and generate content just like a human would do. Pre-trained large language models (LLMs), such as ChatGPT and LLaMA, have demonstrated astounding aptitudes for understanding the material and responding to frequent queries. Several studies have demonstrated their aptitude for internalizing knowledge and responding to inquiries. Though LLMs have significantly advanced, they frequently lack a sophisticated understanding of domain-specific nuances and are prone to producing incorrect information, known as hallucinations. This highlights the significant obstacles to improving LLM accuracy and reducing the incidence of hallucinating responses.
Discussion related to LLMs has majorly focused on three main areas, which are reducing hallucinations in LLM-generated responses, improving the factual accuracy of LLMs, and speculating on whether LLMs might eventually replace Knowledge Graphs (KGs) as a means of storing world knowledge in a symbolic format. Recently, a team of researchers from Meta Reality Labs have opted for a fresh approach to answer these questions by attempting to determine how much information LLMs actually possess.
While answering the question of how well-versed LLMs are in terms of knowledge, the team has discussed two aspects. Firstly, it can be difficult to directly question the knowledge contained within an LLM at first. Even if the knowledge is already incorporated in the model’s parameters, hallucinations could be caused by a lack of knowledge or a malfunctioning generative model. The study suggests using correctness as a metric to roughly gauge the degree of knowledge within an LLM. This involves assessing the model’s ability to answer clear, accurate questions like “Where was basketball player Michael Jordan born?” The LLM is also asked to provide succinct responses and admit uncertainty by using the word ‘unsure’ when its confidence is low.
Secondly, there is no readily accessible benchmark that accurately reflects the diversity of user interests or the breadth of information in the world. Even the most comprehensive knowledge graphs show gaps in knowledge, particularly when it comes to less well-known facts. The query logs from major LLMs or search engines are not publicly available.
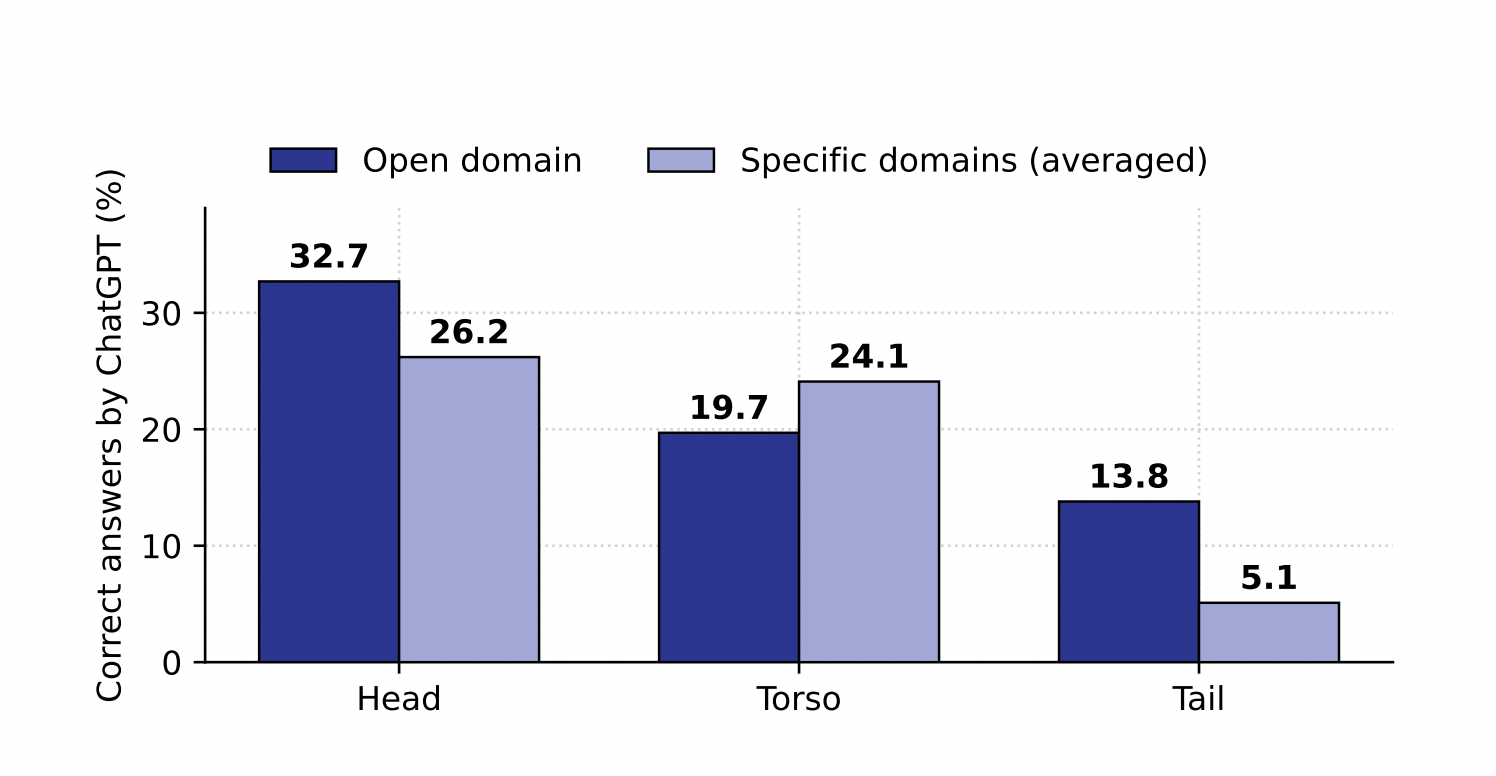
To address all the limitations, the team has introduced a benchmark they have created called “Head-to-Tail.” This benchmark consists of a collection of 18,000 question-answer (QA) pairs that have been divided into head, torso, and tail facts based on the popularity of their respective subjects. Different public familiarity levels are reflected in these categories. The team has created an automated evaluation method and a set of measures that closely reflect the breadth of knowledge that an LLM has competently assimilated in order to evaluate the knowledge maintained by LLMs.
The research’s core is the evaluation of 14 LLMs that are available to the general public. The results showed that existing LLMs still need to improve significantly in terms of perfecting their comprehension of factual data. This is especially true for information that falls within the torso-to-tail area and concerns less well-known organizations.
In conclusion, this research examines the factual knowledge of LLMs using a recently proposed benchmark and cutting-edge evaluation techniques. The work makes a substantial contribution to the continuing discussion regarding the dependability and prospective advancements of big language models in incorporating factual information by addressing significant research problems and outlining specific findings.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.