With A Vision To Build A ‘Universal Translator’, Meta AI Open-Sources ‘NLLB-200’ Model That Can Translate 200 Languages
Language is also described as a mode of communication utilized by human beings as members of a social group, as participants of a cultural group to express themselves. But people face problems at some stage when they want to read content, watch a movie or engage in conversation with people. However, they found it challenging to engage in it just because people don’t know the particular language. This is especially true for the hundreds of millions of people who speak many languages of Africa and Asia.
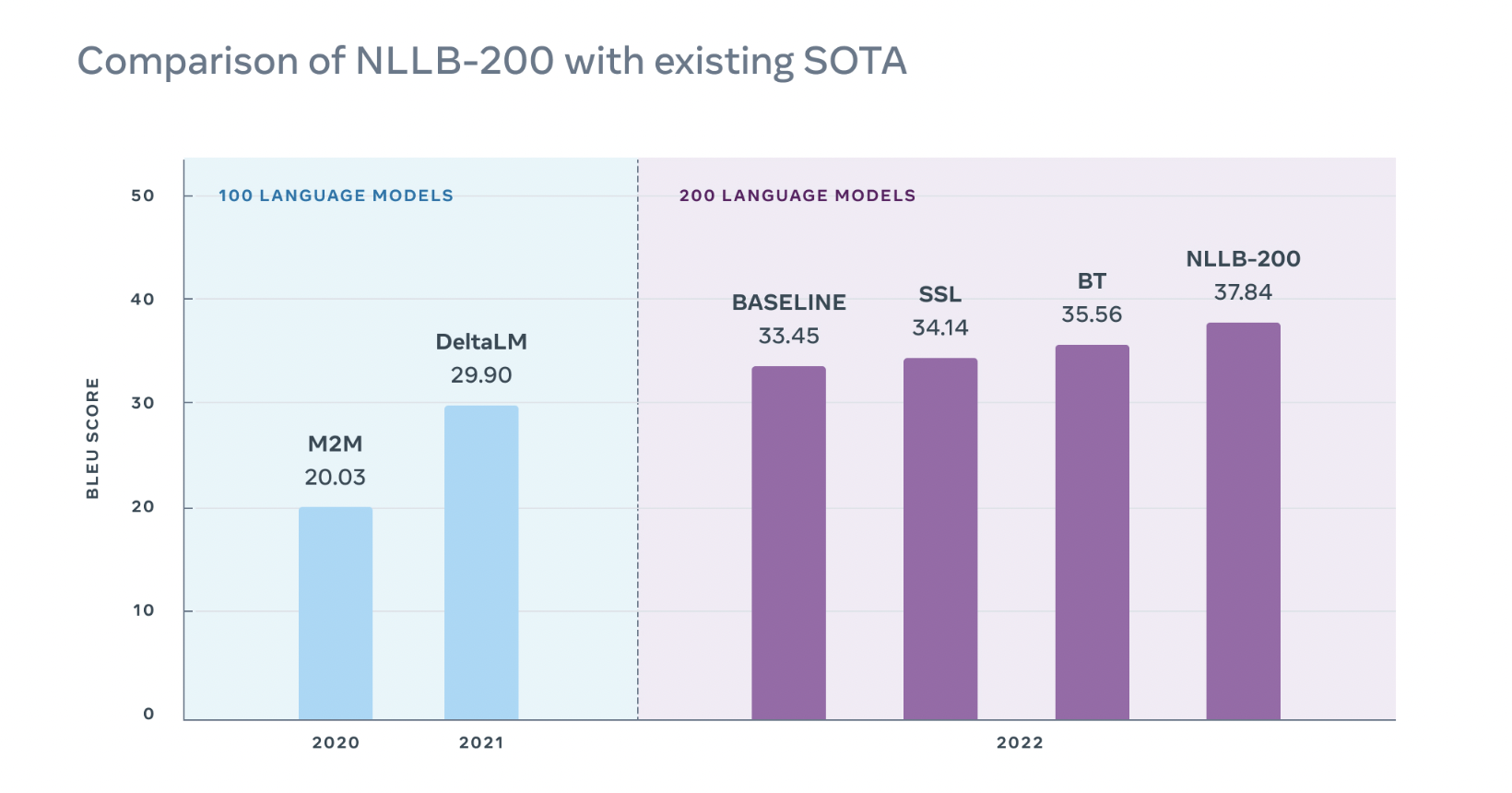
To overcome this issue, Meta has announced its high-quality machine translation capability model to translate most of the world’s languages called NLLB (No Language Left Behind). NLLB-200 is an effort to develop a single language translation AI model by meta researchers that could translate up to 200 languages (many of which are still not supported even by some of the best existing models today) with state-of-the-art results. Fewer than 25 African languages are supported by widely used language translation tools today, whereas NLLB-200 increases this count to 55 languages, including increased accuracy up to 70% for some of them. While comparing the quality of translation to previous AI research, NLLB-200 scores an average of 44% high across all 10k directions of the FLORES-101 benchmark, providing increased accuracy up to 70% for some of the regional-based Asian and African languages.
Meta has partnered with Wikimedia Foundation, the non-profit organization that hosts Wikipedia and other free knowledgeable projects to provide access to information it shares. Most of the articles it shares are available in English, creating a disparity between articles in other languages. Now, Wikipedia is using NLLB to translate its articles to 20 different low-resource languages, out of which 10 were not supported earlier by any language-translation tool.
Meta has implied the research advancements from NLLB will support more than 25 billion translations served daily on Facebook News Feed, Instagram, and our other platforms. High-quality and accurate translations in more languages would help spot harmful content and misinformation, protect election integrity, and curb online sexual exploitation and human trafficking on these platforms. Also, to help fellow developers and researchers improve their translation tools and contribute to the model, Meta has announced open-sourcing of this model along with the source code for the model and the training dataset. It has also announced grants of up to $200,000 for impactful uses of NLLB-200 to researchers and non-profit organizations with initiatives focused on sustainability, food security, gender-based violence, education, or other areas supporting the UN Sustainable Development goals.
Meta first introduced its preliminary model, M2M-100, which could translate up to 100 languages in 2020. To expand this ability for another 100, Meta tried to incorporate newer methods to acquire training data and ideas to scale the model without compromising on its performance, avoid overfit or underfit, and evaluate and improve the results. For training datasets, Meta tried to leverage LASER3( a toolkit developed and enhanced by meta, which is a zero-shot transfer in NLP) instead of LSTM, a newer version. LASER3 uses a transformer model trained self-supervised with a masked language modeling objective. This is also open-sourced by Meta if you want to look at it. After collecting highly accurate parallel texts in different languages, Meta researchers faced significant challenges in expanding this model from 100 to 200 languages. For more low-resource language pairs in training data, the model started to overfit while training it for extended periods. To overcome these issues, innovation was done on three fronts: regularization and curriculum learning, self-supervised learning, and diversifying back-translation. Once all these were completed, the model was trained on the newly built Research SuperCluster (RSC), among the fastest AI supercomputers worldwide, along with 54B parameters.
With all of these, as the metaverse begins to take shape, this model by Meta would help to transform the language-translation abilities in various domains. For example, language translations, subtitles, multimedia, etc., and the ability to build technologies that work well in a broader range of languages will help democratize access to immersive experiences in virtual worlds.
References:
- https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
- https://about.fb.com/news/2022/07/new-meta-ai-model-translates-200-languages-making-technology-more-accessible/
- https://www.ithome.com.tw/news/151819
- https://www.theverge.com/2022/7/6/23194241/meta-facebook-ai-universal-translation-project-no-language-left-behind-open-source-model
- https://www.zdnet.com/article/metas-latest-ai-model-will-make-content-available-in-hundreds-of-languages/
- https://venturebeat.com/2022/07/06/metas-open-source-ai-model-leaves-no-language-behind/
Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.