You Sing, I Play! Meet SingSong: An AI Model Capable of Generating Accompanying Music for Singing
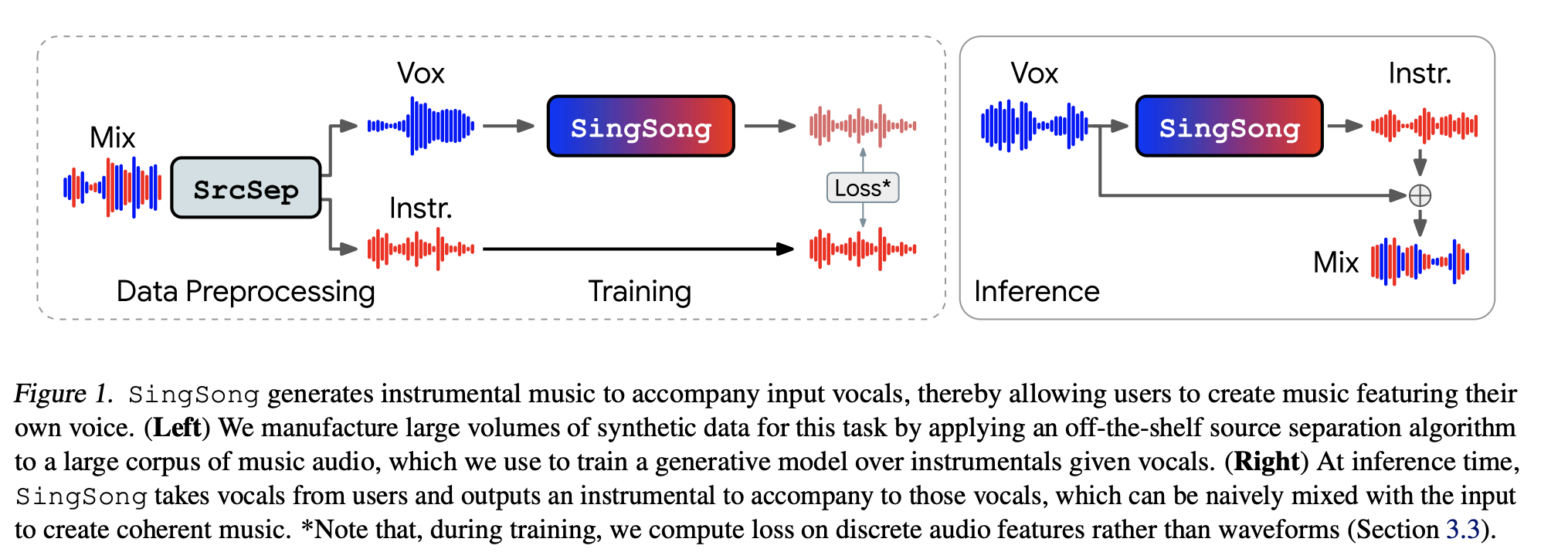
Image generation, video generation, text generation, and so on. Generative AI models have become more and more powerful recently. They can generate images, videos, and text pieces that are becoming difficult to separate from the ones prepared by humans.
The generative AI saga continues to impress us with unique use cases. For example, we have seen a model that can generate 3D videos for AR/VR applications that is possible by describing what you want to see. On the other hand, we have seen a model that can generate music from text prompts.
Speaking of generating music, if you’ve ever tried to come up with your own music, you know that coming up with a great melody is only half the battle. The other half is finding the perfect accompaniment that complements the melody and gives it that professional studio sound. But what if you don’t have the skills or resources to produce instrumental music that fits your vocals? Worry no more as we have the SingSong now, a new AI-powered tool that generates musical accompaniments from singing.
SingSong is capable of accompanying your singing with correct instrumental music. Let’s say you just record yourself reciting the vocal, and you want to add some instrumental music to that recording. In this case, you can give your vocal to SingSong, which will generate the music for you, and you will have a song for yourself.
SingSong became possible thanks to the advancement in two key fields of music technology. First is source separation which is used to separate vocals and instrumental sources in the music. This dataset is aligned in pairs of vocals and instrumental sources and is used for training. The second one is the generative modeling of audio. They use this model to go from vocals to instrumental music, i.e., conditional audio-to-audio generation.
Technology was there, but combining them was not as straightforward as plug-and-play. The biggest challenge was to design a system that could effectively process isolated vocal inputs from users by using the separated vocal inputs seen during the training. Initially, the models they built were biased towards reconstructing instrumental sounds from barely audible artifacts that exist in the separated vocals. When this was the case, the resulting audio was weird and not aligned with the vocals.
The solution to this was adding noise to vocal inputs to conceal artifacts and using only the most simplified intermediate representations from the audio-to-audio model as conditioning input.
To evaluate the performance of SingSong, Google Researchers held a subjective study in which random listeners were asked to rate the music they heard. This music included the ones generated with SingSong and a baseline in which the musical features of the vocals are used as a query to retrieve human-composed instrumentals. When compared to instrumentals obtained from the retrieval baseline, instrumentals obtained from SingSong were preferred by listeners 66% of the time. Additionally, listeners preferred the instrumentals generated by SingSong 34% of the time when compared to the true, original instrumentals.
Overall, SingSong is an exciting development that has the potential to democratize music production and give more people the tools they need to come up with great songs.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.