Zhejiang University Researchers Propose Fuyou: A Low-Cost Deep Learning Training Framework that Enables Efficient 100B Huge Model Fine-Tuning on a Low-End Server with a Low-End GPU and Limited CPU Memory Capacity
The advent of large language models (LLMs) has sparked a revolution in natural language processing, captivating the world with their superior capabilities stemming from the massive number of parameters they utilize. These LLMs, epitomized by the transformative power of dense transformer models, have not only broken records in accuracy but have also become indispensable assets in data management tasks. Recently, the model size of dense transformer models has grown from 1.5B (GPT-2) to 540B (PaLM), which shows the evolution of these models in an unprecedented journey into the realm of linguistic mastery.
While the potential of LLMs is undeniable, a critical challenge arises from their immense parameter sizes overwhelming even the most powerful GPUs, which currently peak at 80GB of memory. When conducting stochastic gradient descent-based optimization, they must be more sufficient to accommodate these vast parameters and their associated optimizer states. To host such a huge model, one can aggregate device memory from multiple GPUs, and it takes 32 NVIDIA A100 GPUs to fit a model with 100 billion parameters for fine-tuning. However, this approach introduces prohibitive costs for most academic researchers, who always have a limited budget for many high-end GPU servers.
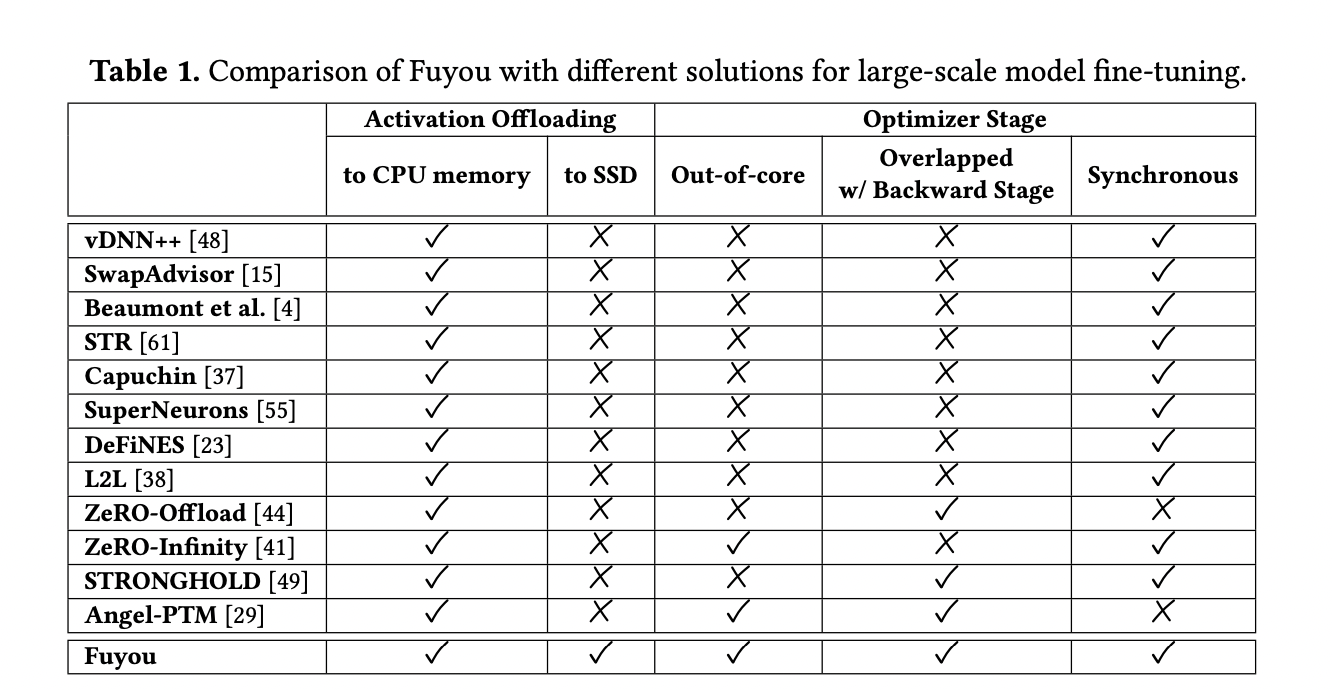
Researchers from Zhejiang University proposed Fuyou. This low-cost training framework enables efficient 100B huge model fine-tuning on a low-end server with a low-end GPU and limited CPU memory capacity. It is implemented on PyTorch, which is a popular deep-learning framework. Compared with other models like ZeRO-Infinity, Fuyou can fine-tune 175B GPT-3 on a consumer GPU RTX 4090 with high GPU utilization, while ZeRO-Infinity fails to fine-tune.
The focus lies on integrating SSD-CPU communication as a pivotal optimization dimension, strategically harmonizing computation and data swapping to unlock the full potential of GPU utilization. This endeavor unfolds through three pioneering innovations:
- A synchronous out-of-core CPU optimizer that overlaps with backward propagation to maximize GPU utilization.
- A GPU-CPU-SSD fully-pipelined activation swapping mechanism to allow for a significantly larger model fine-tuning.
- An automatic activation swapping management to automatically determine the optimal amount of swapping activations to minimize the epoch time.
In the dynamic realm of model fine-tuning, Fuyou emerges as a powerhouse, delivering exceptional performance whether on the cutting-edge A100-80GB or the formidable 4090 in a commodity server. When fine-tuning a GPT-3 175B model, Fuyou achieves 87 TFLOPS on 4090 and 172 TFLOPS on A100-80GB. Also, it reaches up to 3.47×TFLOPS compared to ZeRO-Infinity when a GPT-3 13B model is fine-tuned. To utilize cheap SSDs in improving training throughput, the cost-effectiveness of Fuyou with Megatron-LM is compared on DGX-2 nodes using tensor parallelism. Throughput is compared over the total price of GPUs6 and SSDs in a server where Fuyou achieves at most 1.70× cost-effectiveness over Megatron-LM.
In conclusion, this paper proposed Fuyou, a low-cost training framework that enables efficient 100B huge model fine-tuning on a low-end server with a low-end GPU and limited CPU memory capacity. It is implemented on PyTorch. It achieves 87 and 172 TFLOPS when fine-tuning GPT-3 175B. Besides, it reaches up to 3.42× and 6.73× TFLOPS compared to ZeRO-Infinity and Colossal-AI when fine-tuning GPT-3 13B. Also, Fuyou achieves at most 1.70× cost-effectiveness over Megatron-LM.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
Credit: Source link
Comments are closed.