Zhejiang University Researchers Propose UrbanGIRAFFE to Tackle Controllable 3D Aware Image Synthesis for Challenging Urban Scenes
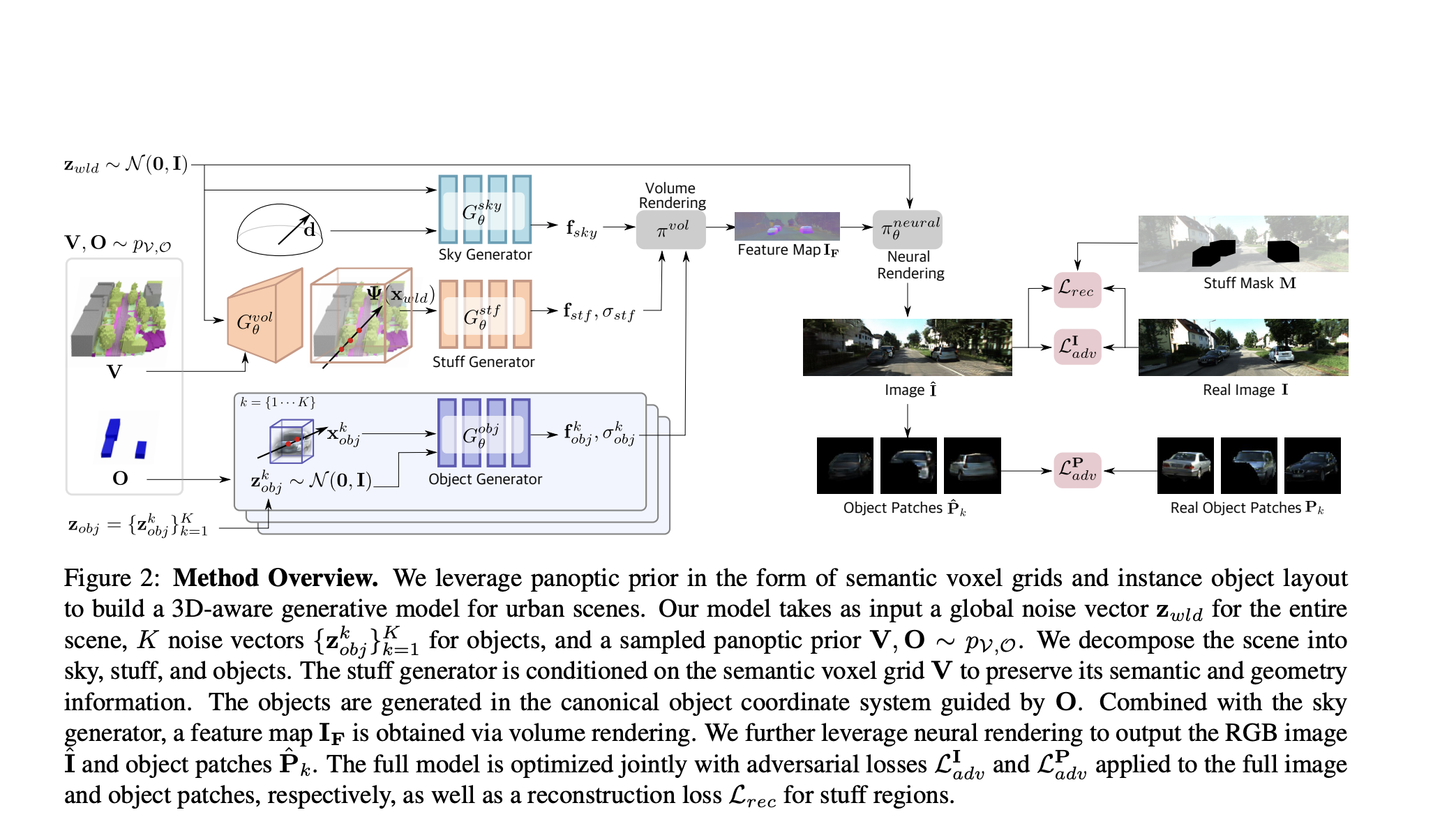
UrbanGIRAFFE, an approach proposed by researchers from Zhejiang University for photorealistic image synthesis, is introduced for controllable camera pose and scene contents. Addressing challenges in generating urban scenes for free camera viewpoint control and scene editing, the model employs a compositional and controllable strategy, utilizing a coarse 3D panoptic prior. It also includes the layout distribution of uncountable stuff and countable objects. The approach breaks down the scene into things, objects, and sky, facilitating diverse controllability, such as large camera movement, stuff editing, and object manipulation.
In conditional image synthesis, prior methods have excelled, particularly those leveraging Generative Adversarial Networks (GANs) to generate photorealistic images. While existing approaches condition image synthesis on semantic segmentation maps or layouts, the focus has predominantly been on object-centric scenes, neglecting complex, unaligned urban scenes. UrbanGIRAFFE, a dedicated 3D-aware generative model for urban scenes, the proposal addresses these limitations, offering diverse controllability for large camera movements, stuff editing, and object manipulation.
GANs have proven effective in generating controllable and photorealistic images in conditional image synthesis. However, existing methods are limited to object-centric scenes and need help with urban scenes, hindering free camera viewpoint control and scene editing. UrbanGIRAFFE breaks down scenes into stuff, objects, and sky, leveraging semantic voxel grids and object layouts before diverse controllability, including significant camera movements and scene manipulations.
UrbanGIRAFFE innovatively dissects urban scenes into uncountable stuff, countable objects, and the sky, employing prior distributions for stuff and things to untangle complex urban environments. The model features a conditioned stuff generator utilizing semantic voxel grids as stuff prior for integrating coarse semantic and geometry information. An object layout prior facilitates learning an object generator from cluttered scenes. Trained end-to-end with adversarial and reconstruction losses, the model leverages ray-voxel and ray-box intersection strategies to optimize sampling locations, reducing the number of required sampling points.
In a comprehensive evaluation, the proposed UrbanGIRAFFE method surpasses various 2D and 3D baselines on synthetic and real-world datasets, showcasing superior controllability and fidelity. Qualitative assessments on the KITTI-360 dataset reveal UrbanGIRAFFE’s outperformance over GIRAFFE in background modeling, enabling enhanced stuff editing and camera viewpoint control. Ablation studies on KITTI-360 affirm the efficacy of UrbanGIRAFFE’s architectural components, including reconstruction loss, object discriminator, and innovative object modeling. Adopting a moving averaged model during inference further enhances the quality of generated images.
UrbanGIRAFFE innovatively addresses the complex task of controllable 3D-aware image synthesis for urban scenes, achieving remarkable versatility in camera viewpoint manipulation, semantic layout, and object interactions. Leveraging a 3D panoptic prior, the model effectively disentangles scenes into stuff, objects, and sky, facilitating compositional generative modeling. The approach underscores UrbanGIRAFFE’s advancement in 3D-aware generative models for intricate, unbounded sets. Future directions include integrating a semantic voxel generator for novel scene sampling and exploring lighting control through light-ambient color disentanglement. The significance of the reconstruction loss is emphasized for maintaining fidelity and producing diverse results, especially for infrequently encountered semantic classes.
Future work for UrbanGIRAFFE includes incorporating a semantic voxel generator for novel scene sampling, enhancing the method’s ability to generate diverse and novel urban scenes. There is a plan to explore lighting control by disentangling light from ambient color, aiming to provide more fine-grained control over the visual aspects of the generated scenes. One potential way to improve the quality of generated images is to use a moving average model during inference.
Check out the Paper, Github, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.