Zigzag Mamba by LMU Munich: Revolutionizing High-Resolution Visual Content Generation with Efficient Diffusion Modeling
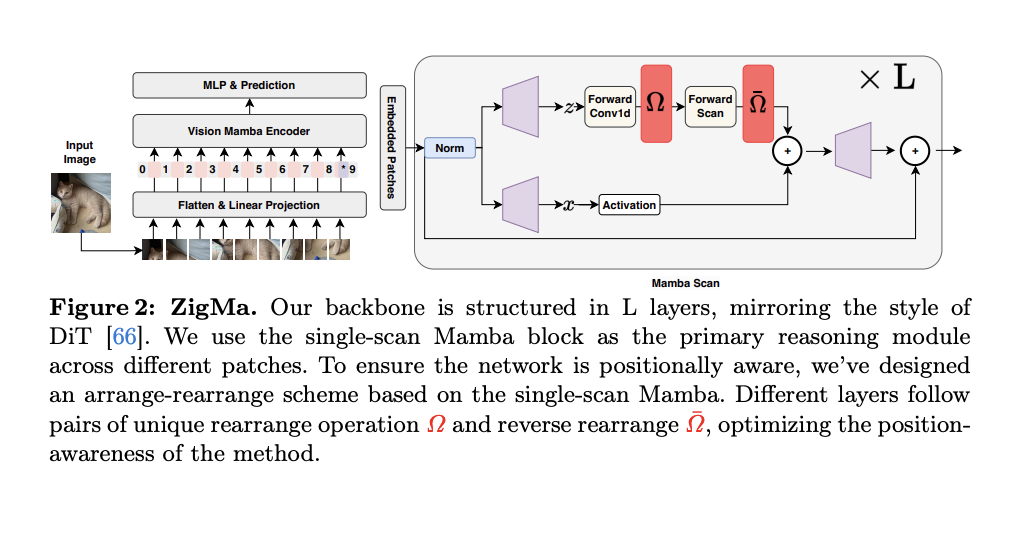
In the evolving landscape of computational models for visual data processing, searching for models that balance efficiency with the ability to handle large-scale, high-resolution datasets is relentless. Though capable of generating impressive visual content, the conventional models grapple with scalability and computational efficiency, especially when deployed for high-resolution image and video generation. This challenge stems from the quadratic complexity inherent in transformer-based structures, a staple in the architecture of most diffusion models.
The State-Space Models (SSMs), where the Mamba model has emerged as a beacon of efficiency for long-sequence modeling. Mamba’s prowess in 1D sequence modeling hinted at its potential for revolutionizing the efficiency of diffusion models. However, its adaptation to the complexities of 2D and 3D data, integral for image and video processing, could have been more straightforward. The crux lies in maintaining spatial continuity, an aspect critical for preserving the quality and coherence of generated visual content yet often overlooked in conventional approaches.

The breakthrough came with the introduction of Zigzag Mamba (ZigMa) by researchers of LMU Munich, a diffusion model innovation that incorporates spatial continuity into the Mamba framework. This method, described in the study as a simple, plug-and-play, zero-parameter paradigm, retains the integrity of spatial relationships within visual data and does so with improvements in speed and memory efficiency. ZigMa’s efficacy is underscored by its ability to outperform existing models across several benchmarks, demonstrating enhanced computational efficiency without compromising the fidelity of generated content.
The research meticulously details ZigMa’s application across various datasets, including FacesHQ 1024×1024 and MultiModal-CelebA-HQ, showcasing its adeptness at handling high-resolution images and complex video sequences. A particular highlight from the study reveals ZigMa’s performance on the FacesHQ dataset, where it achieved a lower Fréchet Inception Distance (FID) score of 37.8 using 16 GPUs, compared to the Bidirectional Mamba model’s score of 51.1.

The versatility of ZigMa is demonstrated through its adaptability to various resolutions and its capacity to maintain high-quality visual outputs. This is particularly evident in its application to the UCF101 dataset for video generation. ZigMa, employing a factorized 3D Zigzag approach, consistently outperformed traditional models, indicating its superior handling of temporal and spatial data complexities.

In conclusion, ZigMa emerges as a novel diffusion model that adeptly balances computational efficiency with the ability to generate high-quality visual content. Its unique approach to maintaining spatial continuity sets it apart, offering a scalable solution for generating high-resolution images and videos. With impressive performance metrics and versatility across various datasets, ZigMa advances the field of diffusion models and opens new avenues for research and application in visual data processing.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.